日常命令
链接远程数据库
1 2 mysql -h主机地址 -P端口 -u用户名 -p用户密码 mysql -h127.0 .0 .1 -P1234 -u"myname" -p"test123"
显示所有库
进入数据库
显示当前库中所有的表
显示表字段
创建表
1 create table table_name (name char (100 ), path char (100 ), count int (10 ), firstName char (100 ), firstMD5 char (100 ), secondName char (100 ), secondMD5 char (100 ), thirdName char (100 ), thirdMD5 char (100 ));
修改表名
1 rename table table_name_old to table_name_new
插入数据
1 insert into table_name (name, path, count, firstName, firstMD5, secondName, secondMD5, thirdName, thirdMD5) VALUES ('test' , 'test' , 1 , 'name1' , 'md1' , 'name2' , 'md2' , 'name3' , 'md3' );
查询表中数据
1 2 3 4 5 select * from table_name; select * from table_name where name = 'test'; select * from table_name order by id limit 0,2;
where、group by和having区别
1 2 3 4 5 6 7 8 9 10 // 1) 在SQL语句中,where子句并不是必须出现的 // 2) where子句是对检索记录中每一行记录的过滤 // 3) having子句出现在group by子句后面 // 4) 如果在一句SQL语句中,where子句和group by……having子句同时都有的话,必须where子句在前,group by……having子句在后。(where先执行,再groupby分组;groupby先分组,having再执行) // 5) group by子句是对检索记录的分组,后面跟随的字段名是分组的依据。根据语法,在select子句中,除聚合函数语句外,SELECT子句中的每个列名称都必须在GROUP BY子句中作为分组的依据。 select vend_id, count(*) , sales from products group by vend_id; 这个语句,其中sales字段,在group by中没有,所以查询的结果,sales的值是错误的!
更新表中某一行数据
1 update table_name set folderName ='Mary' where id=1;
删除表中某一行数据
1 delete from table_name where folderName = 'test';
添加表字段
1 alter table table_name add id int auto_increment not null primary key;
删除字段
1 alter table table_name drop folderName;
left join、right join和inner join区别 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 表A aID aNum 1 a12 a23 a34 a45 a5表B bID bNum 1 b12 b23 b34 b46 b6
left join left join(左连接)返回包括左表中的所有记录和右表中联结字段相等记录。
1 2 3 4 5 6 7 8 select * from A left join B on A.aID = B.bID;aID aNum bID bNum 1 a1 1 b12 a2 2 b23 a3 3 b34 a4 4 b45 a5 NULL NULL
left join是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的.
right join right join(右连接)返回包括右表中的所有记录和左表中联结字段相等记录。
1 2 3 4 5 6 7 8 select * from A right join B on A.aID = B.bID;aID aNum bID bNum 1 a1 1 b12 a2 2 b23 a3 3 b34 a4 4 b4NULL NULL 6 b6
仔细观察一下,就会发现,和left join的结果刚好相反,这次是以右表(B)为基础的,A表不足的地方用NULL填充.
inner join inner join(等值连接)只返回两个表中联结字段相等行。
1 2 3 4 5 6 7 select * from A inner join B on A.aID = B.bID;aID aNum bID bNum 1 a1 1 b12 a2 2 b23 a3 3 b34 a4 4 b4
很明显,这里只显示出了 A.aID = B.bID的记录.这说明inner join并不以谁为基础,它只显示符合条件的记录.
优化规则 核心
字段名不要使用‘key’ ‘index’ ‘like’‘time’ 等等关键字
表字段尽量少,上限控制在20~50个,适当可以冗余(平衡范式和冗余)。
不在数据库做强运算,不要使用存储过程、触发器等,数据库主要负责存储,不承担大量业务逻辑。
拒绝大sql,大事务。批量删除时,请控制在操作行数1万以内的小事务。批量插入时,请控制并发,并发搞很容易死锁。
索引
能不加的索引尽量不加,最好不超过字段数的20%(如:性别不加),结合核心SQL优先考虑覆盖索引(https://my.oschina.net/BearCatYN/blog/476748 )
字符字段必须建前缀索引。由于字符串很长,通常可以索引开始的几个字符,而不是全部值,以节约空间并得到好的性能。(http://www.educity.cn/wenda/402373.html )
不在索引列进行数学运算和函数运算(会导致无法使用索引 => 全表扫描),如where id+1 = 100 和 id = 100 - 1,效率差很远
自增列或全局ID做INNODB的主键
尽量不用外键(由程序保证约束),高并发的时候容易死锁。
sql语句
尽量少用select *,只取需要数据列,为使用覆盖索引提供可能性,减少临时表生成,更安全
用in()代替or,因为or的效率是O(n),而in()的效率是O(Log n)。如:where a = 1 OR a = 100 与 where a IN (1, 100)
尽量避免负向查找,如NOT、!=等
减少COUNT(*),使用COUNT(col),前者资源开销大,尽量少用。
大批量更新凌晨操作,避开高峰,零点附近往往定时任务量比较大,如果可以,尽量安排在03:00-07:00.
LIMIT高效分页:传统的方法是select * from t limit 10000, 10,推荐的方法是select * from t where id > 23423 limit 10。LIMIT的偏移量越大则越慢。还有一些高效的方法有:先取id来LIMIT偏移,减少整体的数据偏移;取到需要的id,与原表JOIN;程序取ID,然后用IN来填写。select * from t where id >= (select id from t limit 10000, 1) limit 10 , select * from t INNER JOIN (select id from t limit 10000, 10) USING (id) , select id from t limit 10000, 10; select * from t where id in (123, 456…)
尽量避免%前缀模糊查询,由于使用的是B+ Tree,前缀模糊使用不了索引,导致全表扫描(后缀模糊速度相对快很多)
优化总结
SQL语句优化,尽量精简,去除非必要语句
索引优化,让所有SQL都能够走索引
如果是表的瓶颈问题,则分表,单表数据量维持在1000W以内
如果是单库瓶颈问题,则分库,读写分离
如果是物理机器性能问题,则分多个数据库节点
mysql执行过程
绿色部分为SQL实际执行部分,主要分为两步:
解析:词法解析->语法解析->逻辑计划->查询优化->物理执行计划,过程中会检查缓存是否可用,如果没有可用缓存则进入下一步mysql_execute_command执行
执行:检查用户、表权限->表加上共享读锁->取数据到query_cache->取消共享读锁
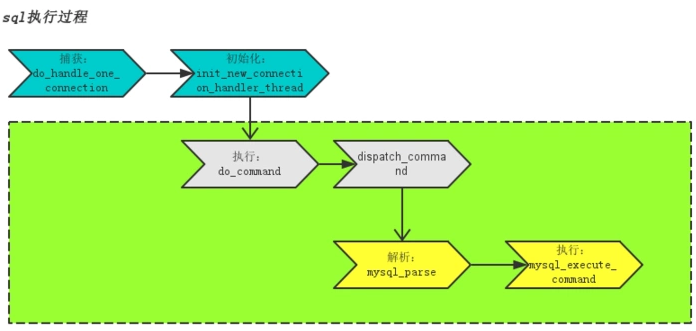 绿色部分为SQL实际执行部分,主要分为两步:
绿色部分为SQL实际执行部分,主要分为两步: