什么是架构
选择合适且有不错扩展能力的技术方案,解决业务真实存在的问题。
也可以粗暴的理解为架构就是骨架,人类的身体的支撑是主要由骨架来承担的,然后是其上的肌肉、皮肤。
什么是框架和框架本质
1. 系统和子系统
- 系统:泛指由一群有关联的个体组成,根据某种规则运作,能完成个别元件不能独立完成的工作能力的群体
- 子系统:一群关联的个体组成的系统,多半是更大系统中的一部分
2. 模块和组件
- 区分逻辑:两者都是系统组成的部分,从不同的角度拆分
- 模块:根据逻辑单位划分; 将复杂的问题简单化,可以系统、子系统、服务、函数、功能模块
- 组件:根据物理文件单位划分;可以是数据库、nginx、ui组件等技术组件
3. 框架和架构
框架是规范,如开源框架:Ruby on Rails、Spring、Laravel、Django等,这是可以拿来直接使用或者在此基础上二次开发
架构是结构,软件系统的顶层结构。架构是指经过系统性思考,权衡利弊之后在现有的资源约束下的最合理决策,最终明确的系统骨架:包括子系统、模块、组件以及他们之间的关系, 约束规范,指定原则,并且由它来指导团队中的每个人思想层面一致
系统性思考的合理决策:技术选型、解决方案
明确系统骨架:明确系统有哪些组成部分
系统协作关系:各组成部分如何协作来实现业务请求
约束规范和指导原则:保证系统有序、高效、稳定运行
架构师具备的能力
架构师思考的问题:如何针对当前需求,选择合适的应用架构,如何面对未来,保证架构平滑过渡- 理解业务
- 全局把控
- 选择合适技术
- 解决关键问题
- 指导研发落地实施
4. 架构分层和分类
1. 业务架构
- 介绍:业务架构包括业务规划、业务流程、对整个系统的业务进行拆分、对领域模型进行设计、把现实的业务转化成抽象对象
- 原则:没有最优的架构,只有最合适的架构,一切系统设计原则都是要以解决业务问题为最终目标,脱离实际业务的技术情怀架构往往会给系统带来大坑。合理的架构能够提前预见业务发展1-2年为宜。
2. 应用架构
- 介绍:应用作为独立可部署的单元,为系统划分了明确边界,深刻影响系统功能组织、代码开发、部署和运维等各方面
- 关键点:
- 职责划分:明确应用(各个逻辑模块和子系统)的边界:逻辑分层、子系统和模块定义
- 职责之间的协作:接口协议(应用对外输出的接口)、协议关系(应用之间的调用关系)
3. 数据架构
- 介绍:数据架构指导数据库和缓存设计
4. 代码/开发架构
- 代码单元:配置设计;框架、类库
- 代码单元组织:编码规范、编码惯例;项目模块划分;顶层文件结构设计;依赖关系
5. 技术架构
6. 部署架构
介绍:拓扑架构,包括架构部署几个节点、节点之间的关系、服务的高可用、网络路口和协议,决定了应用如何运行,运行的性能、可维护、可扩展性, 这是所有架构的基础。
设计模式
1. 什么是设计模式
模式就是经验,设计模式就是设计经验,有了这些经验,我们就能在特定情况下使用特定的设计、组合设计,这样可以大大节省我们的设计时间,提高工作效率。
2. 架构方面设计模式分类
- 单库单应用模式:结构简单、开发速度快、为原型验证和用户少的应用设计
- 内容分发模式:目前用的比较多
- 查询分离模式:对于大并发的查询、业务
- 微服务模式:适用于复杂的业务模式的拆解
- 多级缓存模式:可以把缓存玩的很好
- 分库分表模式:解决单机数据库瓶颈
- 弹性伸缩模式:解决波峰波谷业务流量不均匀的方法之一
- 多机房模式:解决高可用、高性能的一种方法
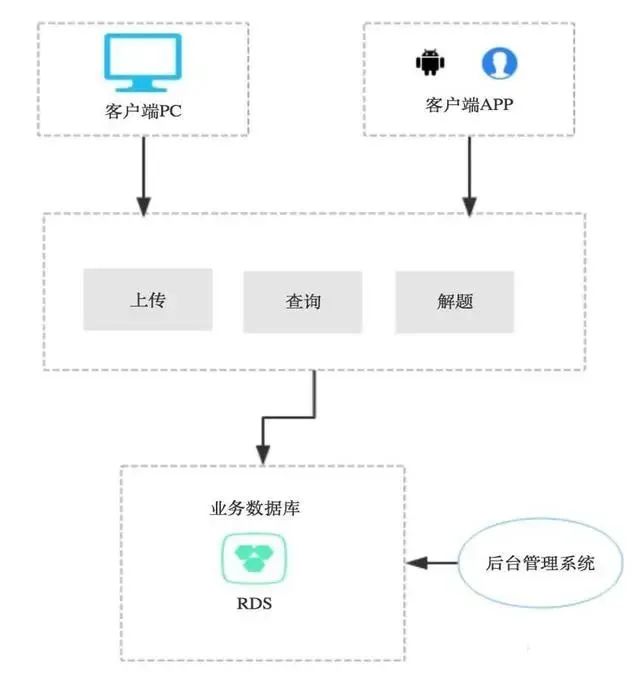
a. 单库单应用模式
- 优点:结构简单、开发速度快、实现简单,可用于产品的第一版等有原型验证需求、用户少的设计。
- 缺点:性能差、基本没有高可用、扩展性差,不适用于大规模部署、应用等生产环境。
b. 内容分发模式
基本上所有的大型的网站都有或多或少的采用这一种设计模式,常见的应用场景是使用CDN技术把网页、图片、CSS、JS等这些静态资源分发到离用户最近的服务器。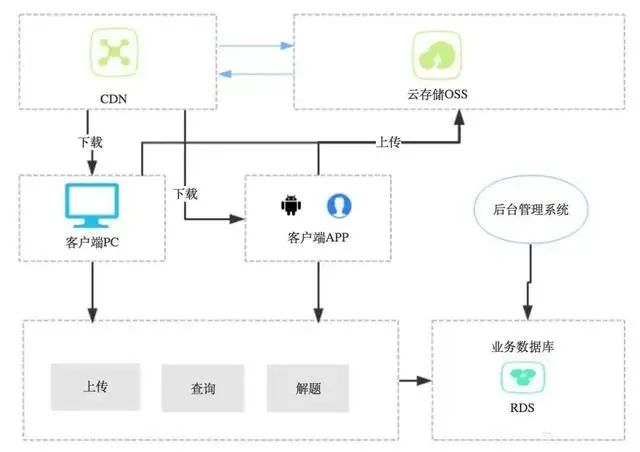
c. 查询分离模式
这种模式主要解决单机数据库压力过大,从而导致业务缓慢甚至超时,查询响应时间变长的问题,也包括需要大量数据库服务器计算资源的查询请求。这个可以说是单库单应用模式的升级版本,也是技术架构迭代演进过程中的必经之路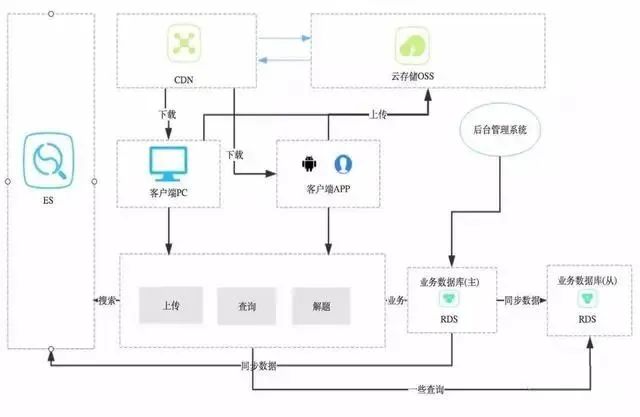
使用场景:
场景一:全文关键词检索
我想这个需求,绝大多数应用都会有,如果使用传统的数据库技术,大部分可能都会使用like这种SQL语句,高级一点可能是先分词,然后通过分词index相关的记录。SQL语句的性能问题与全表扫描机制导致了非常严重的性能问题,现在基本上很少见到。这里的ES是ElasticSearch的缩写,是一种查询引擎。
a. 服务端把一条业务数据落库
b. 服务端异步把该条数据发送到ES
c. ES把该条记录按照规则、配置放入自己的索引库
d. 客户端查询的时候,由服务端把这个请求发送到ES,得到数据后,根据需求拼装、组合数据,返回给客户端场景二:大量的普通查询
这个场景是指我们的业务中的大部分辅助性的查询,如:取钱的时候先查询一下余额,根据用户的ID查询用户的记录,取得该用户最新的一条取钱记录等。我们肯定是要天天要用的,而且用的还非常多。同时呢,我们的写入请求也是非常多的,导致大量的写入、查询操作压向同一数据库,然后,数据库挂了,系统挂了。所以要求我们必须分散数据库的压力,一个业界较成熟的方案就是数据库的读写分离,写的时候入主库,读的时候读从库。这样就把压力分散到不同的数据库了,如果一个读库性能不行,扛不住的话,可以一主多从,横向扩展。
a.服务端把一条业务数据落库
b.数据库同步或异步或半同步把该条数据复制到从库
c.服务端读数据的时候直接去从库读相应的数据
d. 微服务模式
我把业务分块,做了垂直切分,切成一个个独立的系统,每个系统各自衍化,有自己的库、缓存、ES等辅助系统,系统之间的实时交互通过RPC,异步交互通过MQ,通过这种组合,共同完成整个系统功能。 那么,这么做是否真的解决上述问题了呢?不玩虚的,一个个来说。对于问题一,由于拆分成了多个子系统,系统的压力被分散了,而各个子系统都有自己的数据库实例,所以数据库的压力变小。
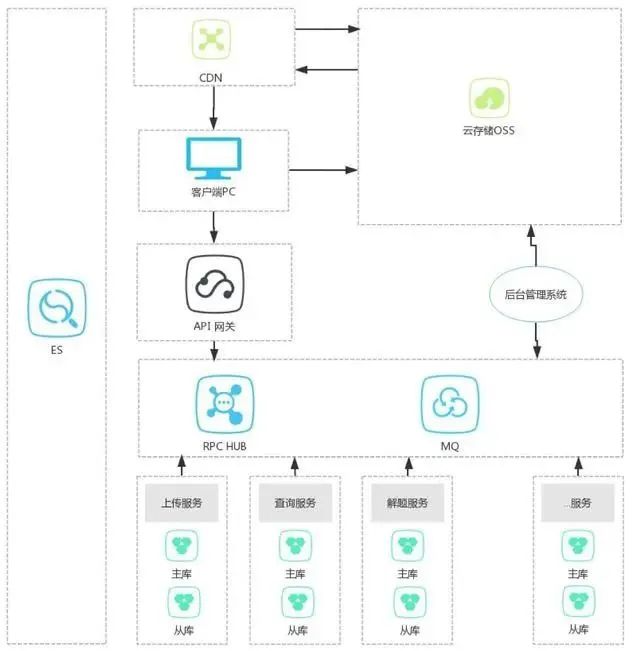
优点如下:
a.对于问题二,一个子系统A的数据库挂了,只是影响到系统A和使用系统A的那些功能,不会所有的功能不可用,从而解决一个数据库挂了,导致所有功能不可用的问题。
b.问题三、四,也因为拆分得到了解决,各个子系统有自己独立的GIT代码库,不会相互影响。通用的模块可通过库、服务、平台的形式解决。
c.问题五,子系统A发生改变,需要上线,那么我只需要编译A,然后上线就可以了,不需要其他系统做同样的事情。
d.问题六,顺应了康威定律,我部门该干什么事、输出什么,也通过服务的形式暴露出来,我部只管把我部的职责、软件功能做好就可以。
e.问题七,所有需要我部数据的需求,都通过接口的形式发布出去,客户通过接口获取数据,从而屏蔽了底层数据库结构,甚至数据来源,我部只需保证我部的接口契约没有发生变化即可,新的需求增加新的接口,不会影响老的接口。
f.问题八,不同的子系统需要不同的权限,这个问题也优雅的解决了。
g.问题九,暂时控制住了复杂性,我只需控制好大的方面,定义好系统边界、接口、大的流程,然后再分而治之、逐个击破、合纵连横。
另外,对于这个模式来说,最难把握的是度,切记不要切分过细,我见过一个功能一个子系统,上百个方法分成上百个子系统的,真的是太过度了。实践中,一个较为可行的方法是:能不分就不分,除非有非常必要的理由!。
e. 多级缓存模式
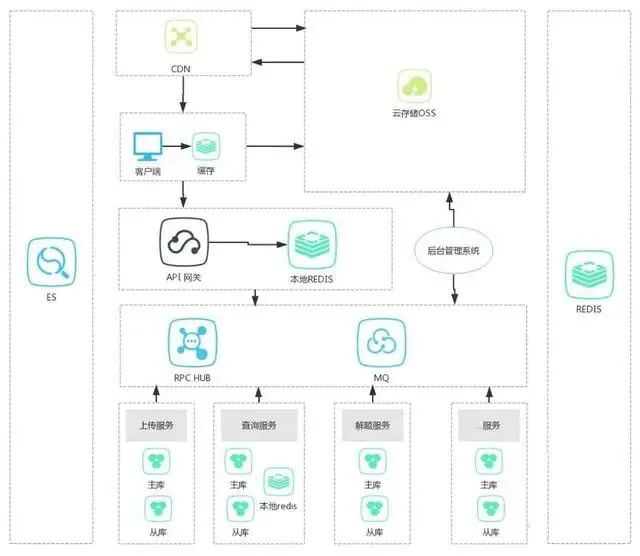
客户端处缓存 –> API网关处缓存 –> 后端业务处
- 优点:抗住大量读请求,减少后端压力。
- 缺点:数据一致性问题较突出,容易发生雪崩,即:如果客户端缓存失效、API网关缓存失效,那么所有的大量请求瞬间压向后端业务系统,后果可想而知。
f. 分库分表模式
这种模式主要解决单表写入、读取、存储压力过大,从而导致业务缓慢甚至超时,交易失败,容量不够的问题。一般有水平切分和垂直切分两种,这里主要介绍水平切分
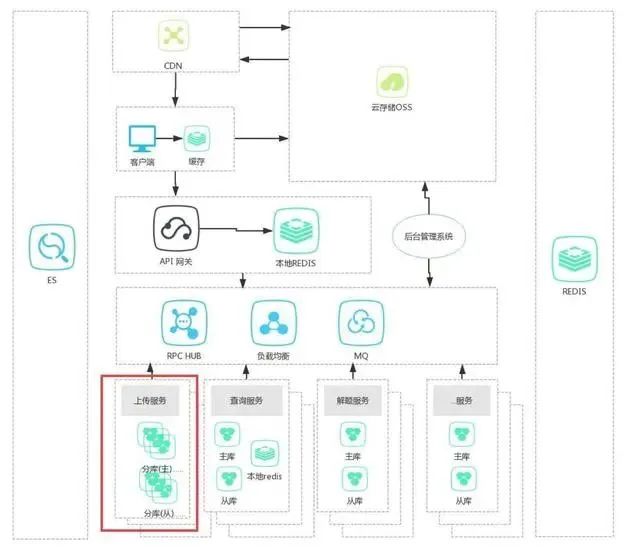
如上图所示红色部分,把一张表分到了几个不同的库中,从而分担压力
主机:硬件,指一台物理机,或者虚拟机,有自己的CPU,内存,硬盘等。
实例:数据库实例,如一个MySQL服务进程。一个主机可以有多个实例,不同的实例有不同的进程,监听不同的端口。
库:指表的集合,如学校库,可能包含教师表、学生表、食堂表等等,这些表在一个库中。一个实例中可以有多个库。库与库之间用库名来区分。
表:库中的表,不必多说,不懂的就不用往下看了,不解释。
a. 优点:减少数据库单表的压力。
b. 缺点:事务保证困难、业务逻辑需要做大量改造。
h. 弹性伸缩模式
这种模式主要解决突发流量的到来,导致无法横向扩展或者横向扩展太慢,进而影响业务,全站崩溃的问题。
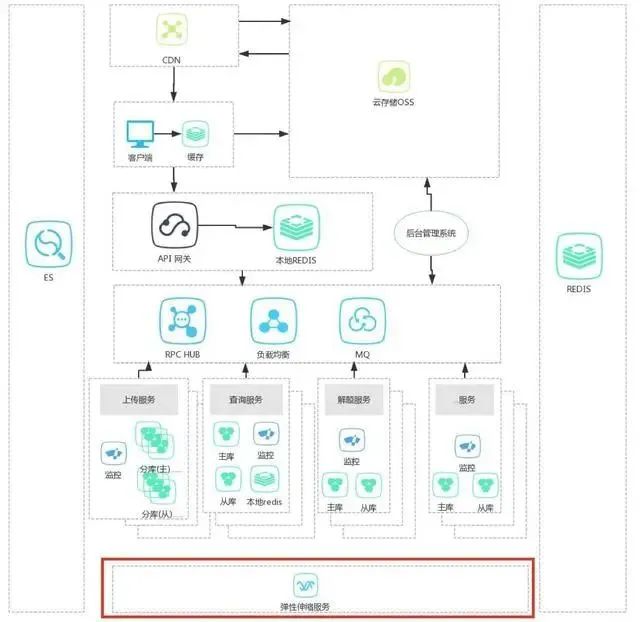
首先把所有的计算资源整合成资源池的概念,然后通过一些策略、监控、服务,动态的从资源池中获取资源,用完后在放回到池子中,供其他系统使用。具体实现上比较成熟的两种资源池方案是VM、docker,每个都有着自己强大的生态。监控的点有CPU、内存、硬盘、网络IO、服务质量等,根据这些,在配合一些预留、扩张、收缩策略,就可以简单的实现自动伸缩。
优点:弹性、随需计算,充分优化企业计算资源。
缺点:应用要从架构层做到可横向扩展化改造、依赖的底层配套比较多,对技术水平、实力、应用规模要求较高。
i. 多机房模式
这种模式主要解决不同地区高性能、高可用的问题。
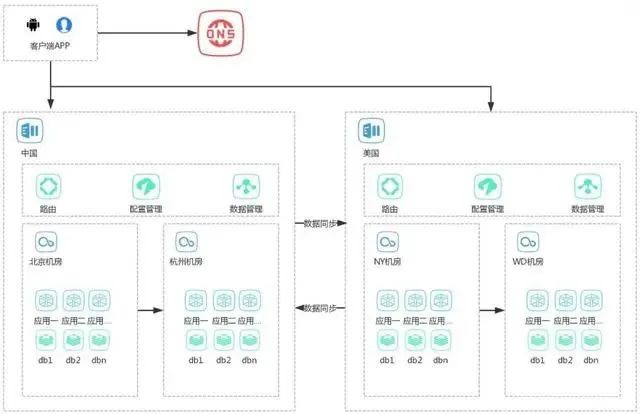
优点:高可用、高性能、异地多活。
缺点:数据同步、数据一致性、请求路由。
[文章来源于](https://mp.weixin.qq.com/s/2koujY54dUsNvmZ9KdueOg) [文章来源于](https://mp.weixin.qq.com/s/7X_WdKXgI7Vglt3qstf-Ug)