nodejs模块机制
commonjs介绍
commonjs对模块的定义十分简单,主要分为模块引用、模块定义、模块标识3个部分。
- 模块引用
1 | var math = require('math'); |
- 模块定义
1 | // 在模块中,上下文提供require()方法来引入外部模块。 |
- 模块标识
模块标识其实就是传递给require()方法的参数,它必须是符合小驼峰命名的字符串,或者以.、..开头的相对路径,或者绝对路径
commonjs模块实现
node模块分为2类:**node提供的核心模块 和 用户编写的文件模块;**核心模块部分在Node源代码的编译过程中,编译进了二进制执行文件,node启动时候已经加载到内存,文件定位和编译执行这两个步骤可以省略掉所以速度最快。
加载模块过程:路径分析 –> 文件定位 –> 编译执行
Node对引入过的模块都会进行缓存,第二次优先从缓存加载;浏览器仅仅缓存文件,而Node缓存的是编译和执行之后的对象;核心模块的缓存检查先于文件模块。
1. 路径分析
模块路径是Node在定位文件模块的具体文件时制定的查找策略,具体表现为一个路径组成的数组
1 | // 1. 创建module_path.js文件,其内容为console.log(module.paths); |
根据上面的例子可以的模块路径生成规则:
❑ 当前文件目录下的node_modules目录。
❑ 父目录下的node_modules目录。
❑ 父目录的父目录下的node_modules目录。
❑ 沿路径向上逐级递归,直到根目录下的node_modules目录。
总结:生成方式与JavaScript的原型链或作用域链的查找方式十分类似。在加载的过程中,Node会逐个尝试模块路径中的路径,直到找到目标文件为止。
2. 文件定位
文件扩展名分析
Node会按.js、.json、.node的次序补足扩展名,依次尝试; 在尝试过程中,调用fs模块同步阻塞式地判断文件是否存在。目录分析和包
require()通过分析文件扩展名之后,可能没有查找到对应文件,但却得到一个目录,此时Node会将目录当做一个包来处理;优先找到目录下package.json文件下main属性当入口; 如果压根没有package.json文件,Node会将index当做默认文件名,然后依次查找index.js、index.json、index.node
3. 编译执行
编译和执行是引入文件模块的最后一个阶段。定位到具体的文件后,Node会新建一个模块对象,然后根据路径载入并编译。
1 | //模块对象 |
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能
读取文件方式
- .js文件, 通过fs模块同步读取
- .node文件, 这是c/c++编写的扩展文件,通过dlopen()加载编译成文件
- .json文件,通过fs模块同步读取, 然后json.parse()解析(反序列化:字节序列转化成对象的过程)
模块编译过程
commonjs规范规定每个模块文件中存在着require、exports、module这3个变量,但是它们在模块文件中并没有定义,那么从何而来呢?甚至在Node的API文档中,我们知道每个模块中还有__filename、__dirname这两个变量的存在,它们又是从何而来的呢。
事实上,在编译的过程中,Node对获取的JavaScript文件内容进行了头尾包装。在头部添加了(function (exports, require, module, __filename, __dirname) {\n,在尾部添加了\n});。一个正常的JavaScript文件会被包装成如下的样子:
1 | (function (exports, require, module, __filename, __dirname) { |
这样每个模块文件之间都进行了作用域隔离。包装之后的代码会通过vm原生模块的runInThisContext()方法执行(类似eval,只是具有明确上下文,不污染全局),返回一个具体的function对象;最后,将当前模块对象的exports属性、require()方法、module(模块对象自身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个function()执行。
上面是这些变量并没有定义在每个模块文件中却存在的原因。在执行之后,模块的exports属性被返回给了调用方。exports属性上的任何方法和属性都可以被外部调用到,但是模块中的其余变量或属性则不可直接被调用。
模拟require模块加载机制
1 | const path = require('path'); // 路径操作 |
异步io
为什么要异步io
- 用户体验: 同步io会影响接口响应时间(M+N+..),异步io会快速响应接口(max(M,N,..))
- 资源分配,目前主流的方式:单线程串行执行 和 多线程并行执行
- 多线程, 缺点:多线程编程经常面临锁、状态同步等问题; 优点:在多核cpu上能够有效提升cpu利用率
- 单线程, 缺点:阻塞io导致硬件资源得不到充分利用;在计算机资源中,通常I/O与CPU计算之间是可以并行进行的。但是同步的编程模型导致的问题是,I/O的进行会让后续任务等待,这造成资源不能被更好地利用。 优点:同步利于程序员编码
- node单线程异步io方案:利用单线程,远离多线程死锁、状态同步等问题;利用异步I/O,让单线程远离阻塞,以更好地使用CPU;为了弥补单线程无法利用多核CPU的缺点,Node提供了类似前端浏览器中WebWorkers的子线程,该子进程可以通过工作进程高效地利用CPU和I/O。
异步io现状
异步io和非阻塞io
异步与非阻塞听起来似乎是同一回事。从实际效果而言,异步和非阻塞都达到了我们并行I/O的目的。 但是从计算机内核I/O而言,异步/同步和阻塞/非阻塞实际上是两回事。操作系统内核对于I/O只有两种方式:阻塞与非阻塞。
任意技术都并非完美的。阻塞I/O造成CPU等待浪费,非阻塞带来的麻烦却是需要轮询去确认是否完全完成数据获取,它会让CPU处理状态判断,是对CPU资源的浪费。这里我们且看轮询技术是如何演进的,以减小I/O状态判断的CPU损耗。现存轮询技术
- read: 它是最原始、性能最低的一种,通过重复调用来检查I/O的状态来完成完整数据的读取。在得到最终数据前,CPU一直耗用在等待上。
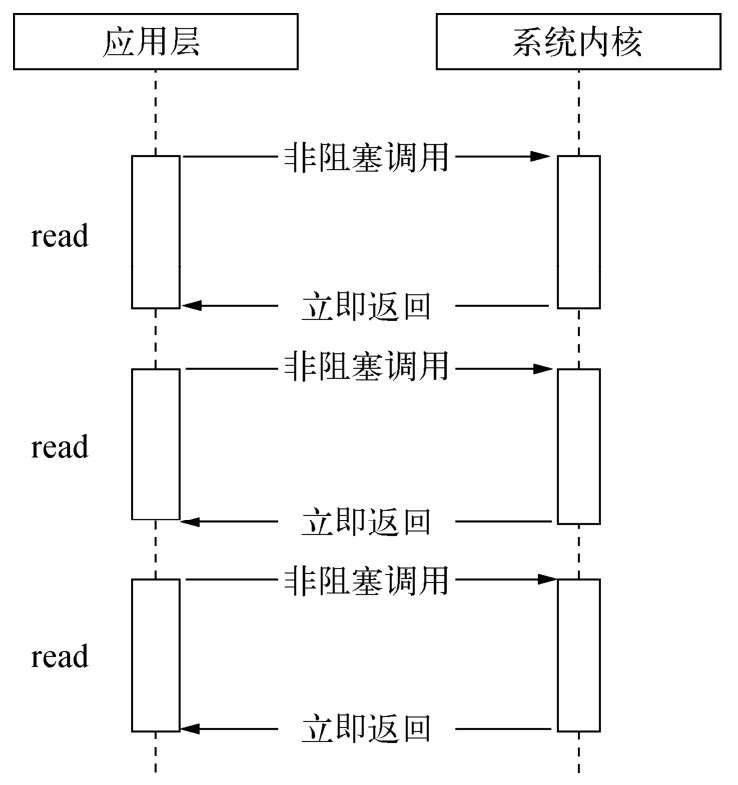 * select: 它是在read的基础上改进的一种方案,通过对文件描述符上的事件状态来进行判断。
* poll: 该方案较select有所改进,采用链表的方式避免数组长度的限制,其次它能避免不需要的检查。但是当文件描述符较多的时候,它的性能还是十分低下的。
* epoll: 该方案是Linux下效率最高的I/O事件通知机制,在进入轮询的时候如果没有检查到I/O事件,将会进行休眠,直到事件发生将它唤醒。它是真实利用了事件通知、执行回调的方式,而不是遍历查询,所以不会浪费CPU,执行效率较高。
* select: 它是在read的基础上改进的一种方案,通过对文件描述符上的事件状态来进行判断。
* poll: 该方案较select有所改进,采用链表的方式避免数组长度的限制,其次它能避免不需要的检查。但是当文件描述符较多的时候,它的性能还是十分低下的。
* epoll: 该方案是Linux下效率最高的I/O事件通知机制,在进入轮询的时候如果没有检查到I/O事件,将会进行休眠,直到事件发生将它唤醒。它是真实利用了事件通知、执行回调的方式,而不是遍历查询,所以不会浪费CPU,执行效率较高。
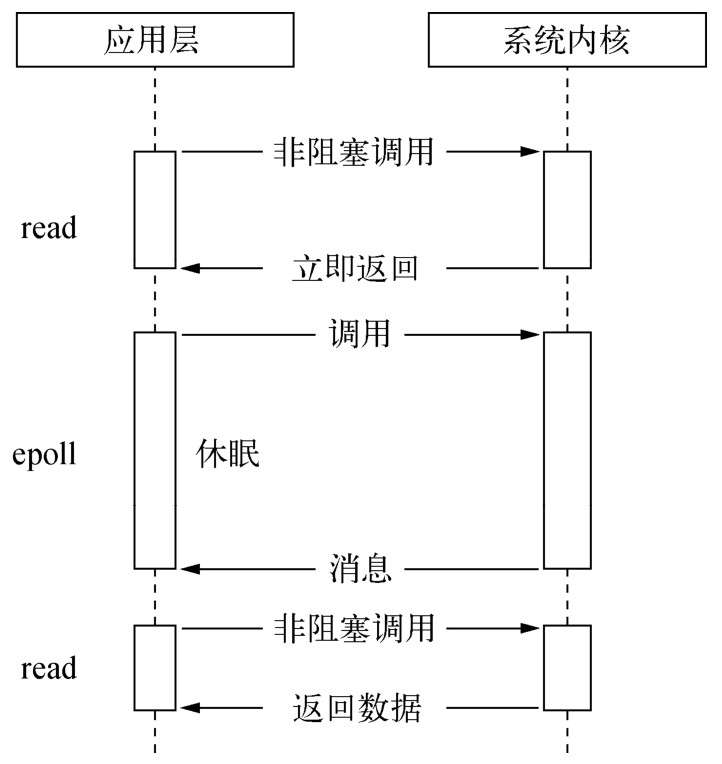
node如何实现异步io
事件循环
在进程启动时,Node便会创建一个类似于while(true)的循环,每执行一次循环体的过程我们称为Tick。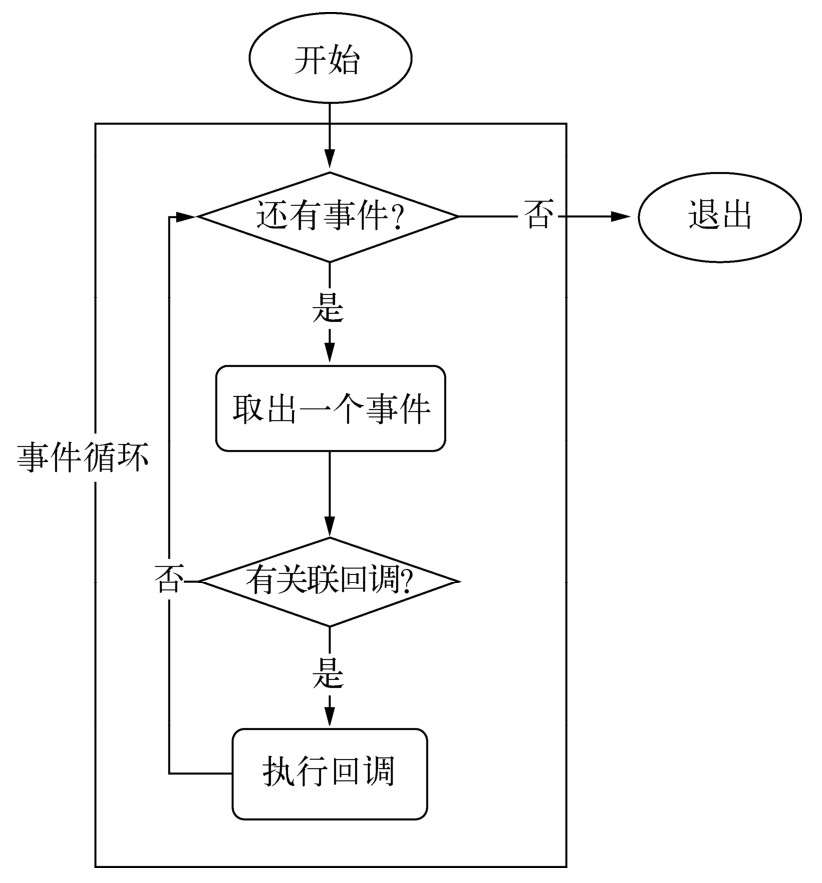
观察者
在每个Tick的过程中,如何判断是否有事件需要处理呢?这里必须要引入的概念是观察者。每个事件循环中有一个或者多个观察者,而判断是否有事件要处理的过程就是向这些观察者询问是否有要处理的事件。浏览器采用了类似的机制。事件可能来自用户的点击或者加载某些文件时产生,而这些产生的事件都有对应的观察者。在Node中,事件主要来源于网络请求、文件I/O等,这些事件对应的观察者有文件I/O观察者、网络I/O观察者等。观察者将事件进行了分类。
事件循环是一个典型的生产者/消费者模型。异步I/O、网络请求等则是事件的生产者,源源不断为Node提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理请求对象
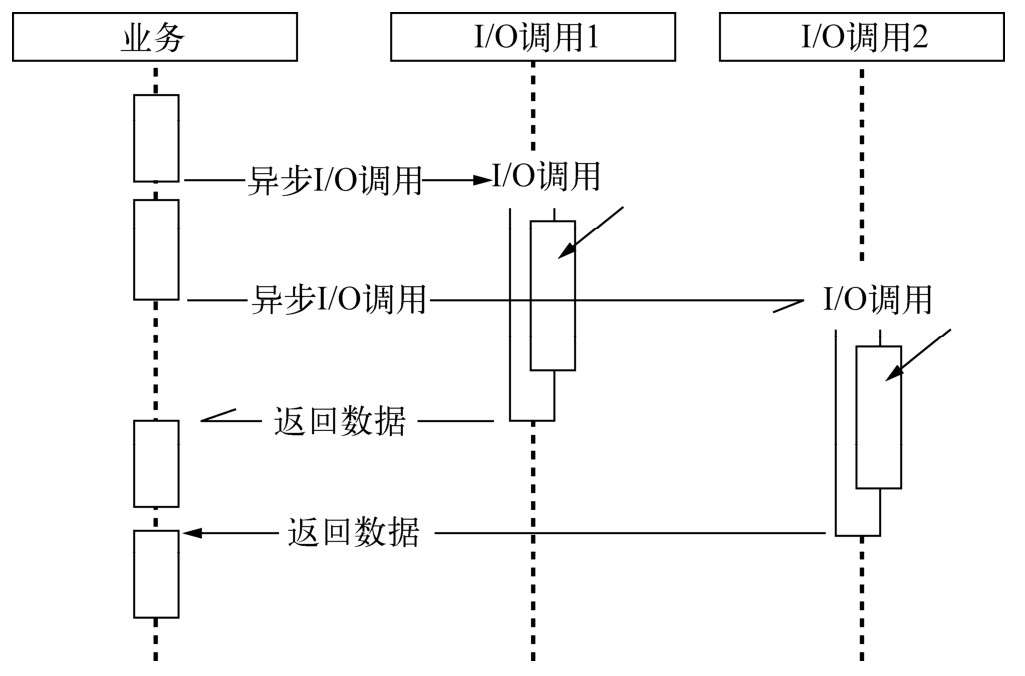
从JavaScript代码到系统内核之间都发生了什么?1
2
3
4
5
6
7fs.open = function(path, flags, mode, callback) {
// ...
binding.open(pathModule._makeLong(path),
stringToFlags(flags),
mode,
callback);
};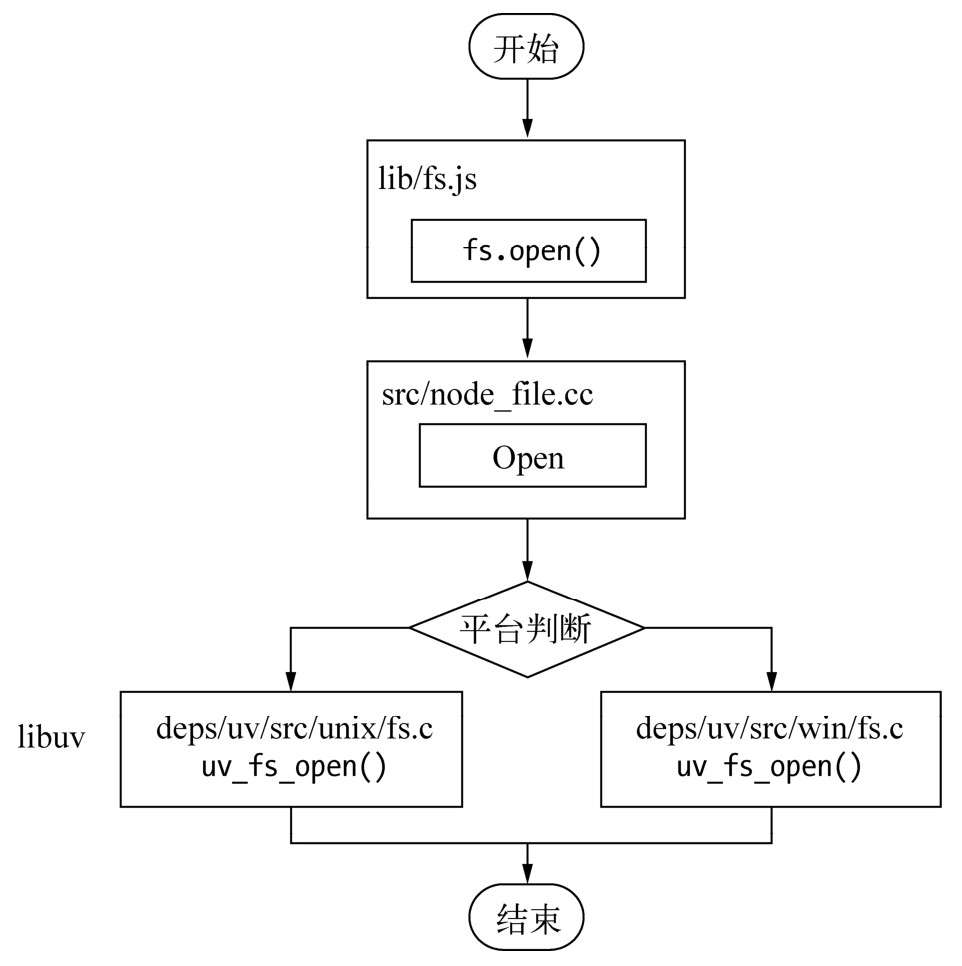 JavaScript线程可以继续执行当前任务的后续操作。当前的I/O操作在线程池中等待执行,不管它是否阻塞I/O,都不会影响到JavaScript线程的后续执行,如此就达到了异步的目的。
JavaScript线程可以继续执行当前任务的后续操作。当前的I/O操作在线程池中等待执行,不管它是否阻塞I/O,都不会影响到JavaScript线程的后续执行,如此就达到了异步的目的。
执行回调
事件循环、观察者、请求对象、I/O线程池这四者共同构成了Node异步I/O模型的基本要素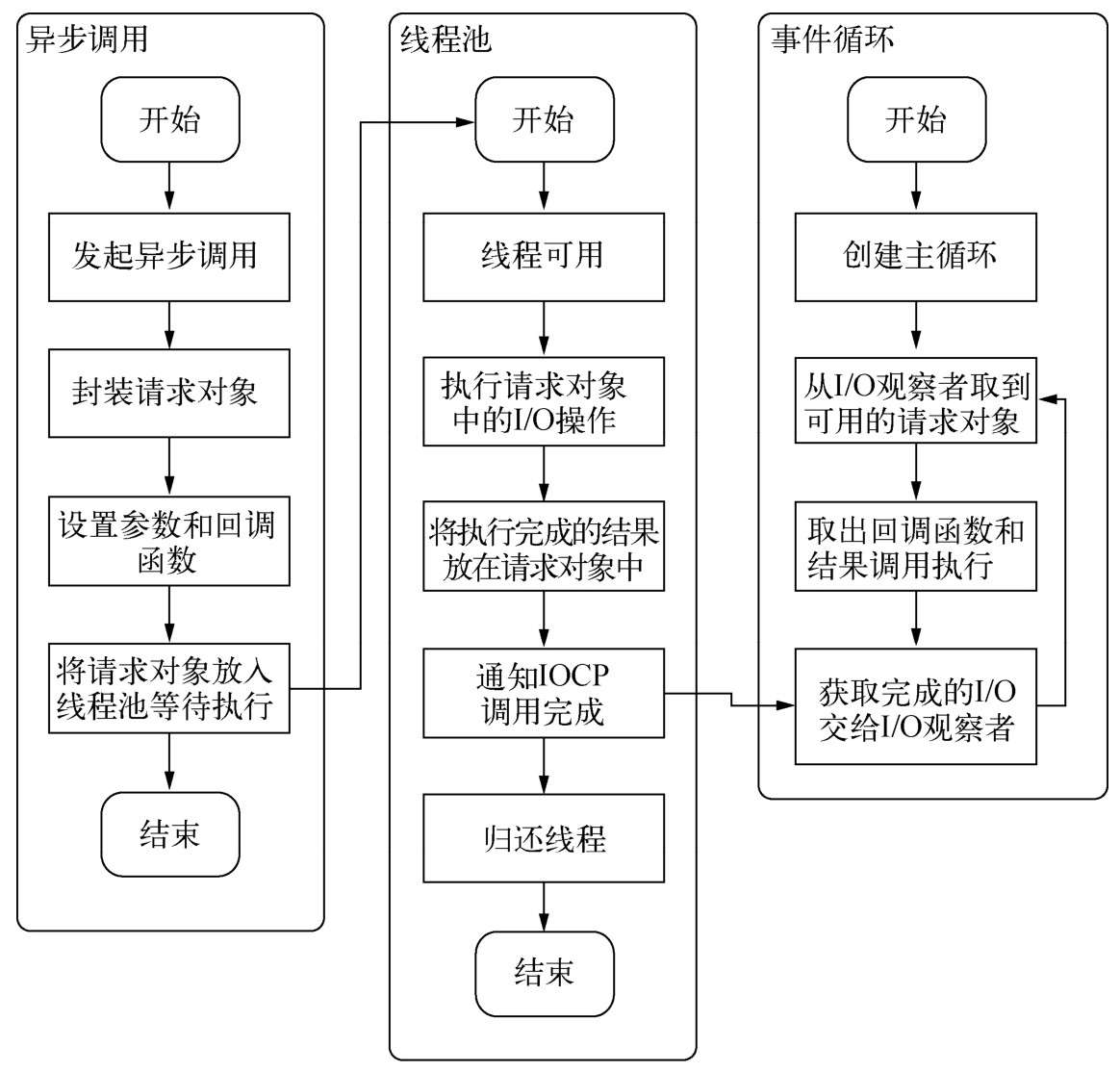
总结
我们可以提取出异步I/O的几个关键词:单线程、事件循环、观察者和I/O线程池。这里单线程与I/O线程池之间看起来有些悖论的样子。由于我们知道JavaScript是单线程的,所以按常识很容易理解为它不能充分利用多核CPU。事实上,在Node中,除了JavaScript是单线程外,Node自身其实是多线程的,只是I/O线程使用的CPU较少。另一个需要重视的观点则是,除了用户代码无法并行执行外,所有的I/O(磁盘I/O和网络I/O等)则是可以并行起来的。
node中非io的异步api
定时器(setTimout/setInterval)
调用setTimeout()或者setInterval()创建的定时器会被插入到定时器观察者内部的一个红黑树中。每次Tick执行时,会从该红黑树中迭代取出定时器对象,检查是否超过定时时间,如果超过,就形成一个事件,它的回调函数将立即执行。process.nextTick()
每次调用process.nextTick()方法,只会将回调函数放入队列中,在下一轮Tick时取出执行。定时器中采用红黑树的操作时间复杂度为O(lg(n)), nextTick()的时间复杂度为O(1)。相较之下,process.nextTick()更高效。setImmediate()
和process.nextTick功能一样优先级对比
process.nextTick > setImmediate; 这里的原因在于事件循环对观察者的检查是有先后顺序的,process.nextTick()属于idle观察者,setImmediate()属于check观察者。在每一个轮循环检查中,idle观察者先于I/O观察者,I/O观察者先于check观察者
事件驱动和高性能服务器
- 经典服务器模型
- 同步式:一次只能处理一个请求,并且其余请求都处于等待状态。
- 每进程/每请求:为每个请求启动一个进程,这样可以处理多个请求,但是它不具备扩展性,因为系统资源只有那么多。
- 每线程/每请求:为每个请求启动一个线程来处理。尽管线程比进程要轻量,但是由于每个线程都占用一定内存,当大并发请求到来时,内存将会很快用光,导致服务器缓慢。(Apache服务)
- 事件驱动:Node通过事件驱动的方式处理请求,无须为每一个请求创建额外的对应线程,可以省掉创建线程和销毁线程的开销,同时操作系统在调度任务时因为线程较少,上下文切换的代价很低。(node、nginx)
异步编程
函数数编程
**高阶函数则是可以把函数作为参数,或是将函数作为返回值的函数。**高阶函数在JavaScript中比比皆是,其中ECMAScript5中提供的一些数组方法(forEach()、map()、reduce()、reduceRight()、filter()、every()、some())十分典型。
偏函数用法是指创建一个调用另外一个部分——参数或变量已经预置的函数——的函数的用法。
1 | // 这种通过指定部分参数来产生一个新的定制函数的形式就是偏函数 |
异步编程优势和难点
A、优势
Node带来的最大特性莫过于基于事件驱动的非阻塞I/O模型,这是它的灵魂所在。非阻塞I/O可以使CPU与I/O并不相互依赖等待,让资源得到更好的利用
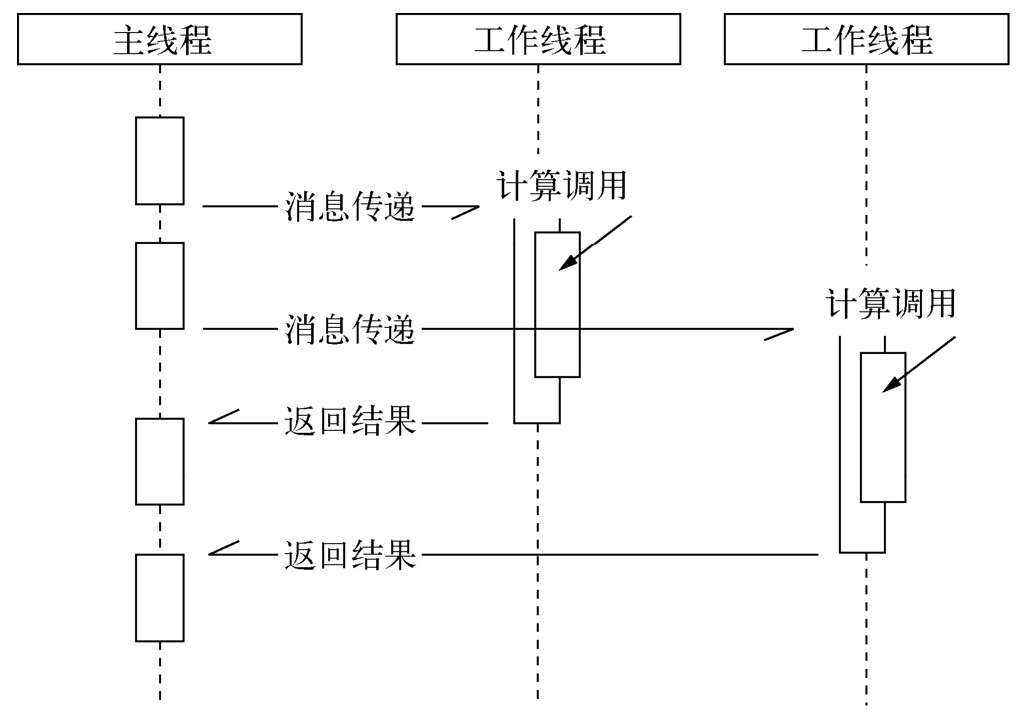
利用事件循环的方式,**JavaScript线程像一个分配任务和处理结果的大管家,I/O线程池里的各个I/O线程都是小二,负责兢兢业业地完成分配来的任务,小二与管家之间互不依赖,所以可以保持整体的高效率。**这个利用事件循环的经典调度方式在很多地方都存在应用,最典型的是UI编程,如iOS应用开发等。
Node是为了解决编程模型中阻塞I/O的性能问题的,采用了单线程模型,这导致Node更像一个处理I/O密集问题的能手,而CPU密集型则取决于管家的能耐如何
由于事件循环模型需要应对海量请求,海量请求同时作用在单线程上,就需要防止任何一个计算耗费过多的CPU时间片。至于是计算密集型,还是I/O密集型,只要计算不影响异步I/O的调度,那就不构成问题。
B、缺点
异常处理(最大缺点)
异步I/O的实现主要包含两个阶段:提交请求和处理结果。这两个阶段中间有事件循环的调度,两者彼此不关联。异步方法则通常在第一个阶段提交请求后立即返回,因为异常并不一定发生在这个阶段,try/catch的功效在此处不会发挥任何作用
1
2
3
4
5
6
7
8
9
10// callback被存放起来,直到下一个事件循环(Tick)才会取出来执行
var async = function (callback) {
process.nextTick(callback);
};
try {
async(callback);
} catch (e) {
// TODO
}函数嵌套过深, 目前node较高版本已支持async/await模式解决了函数嵌套问题
多线程编程
浏览器提出了Web Workers,它通过将JavaScript执行与UI渲染分离,可以很好地利用多核CPU为大量计算服务。同时前端Web Workers也是一个利用消息机制合理使用多核CPU的理想模型
Node借鉴了浏览器web workers这个模式,**child_process是其基础API, cluster模块是更深层次的应用。**借助Web Workers的模式,开发人员要更多地去面临跨线程的编程,这对于以往的JavaScript编程经验是较少考虑的。
异步转同步, 目前node较高版本已支持async/await模式
异步编程解决方案
1. 事件发布/订阅模式
事件侦听器模式也是一种钩子(hook)机制,利用钩子导出内部数据或状态给外部的调用者。 Node自身提供的events模块是发布/订阅模式的一个简单实现,Node中部分模块都继承自它。
EventProxy的原理
1 | // 核心代码 |
2. Promise/Deferred模式
3. async/await模式
4. 流程控制库
尾触发和next(Connect中间件)
除了事件和Promise外,还有一类方法是需要手工调用才能持续执行后续调用的,我们将此类方法叫做尾触发,常见的关键词是next
1
2
3
4
5
6
7
8
9
10var app = connect();
// Middleware
app.use(connect.staticCache());
app.use(connect.static(__dirname + '/public'));
app.use(connect.cookieParser());
app.use(connect.session());
app.use(connect.query());
app.use(connect.bodyParser());
app.use(connect.csrf());
app.listen(3001);connect核心代码
1 | function app(req, res){ app.handle(req, res); } |
- async流程库: 异步的串行执行
1
2
3
4
5
6
7
8
9
10async.series([
function (callback) {
fs.readFile('file1.txt', 'utf-8', callback);
},
function (callback) {
fs.readFile('file2.txt', 'utf-8', callback);
}
], function (err, results) {
// results => [file1.txt, file2.txt]
});
异步并发控制
目前社区中有bigpipe、async异步流程库解决方案
bigpipe核心实现
1 | /** |
内存控制
V8的垃圾回收机制和内存限制
1. V8的内存限制
至于V8为何要限制堆的大小,表层原因为V8最初为浏览器而设计,不太可能遇到用大量内存的场景。对于网页来说,V8的限制值已经绰绰有余。深层原因是V8的垃圾回收机制的限制。按官方的说法,以1.5 GB的垃圾回收堆内存为例,V8做一次小的垃圾回收需要50毫秒以上,做一次非增量式的垃圾回收甚至要1秒以上。这是垃圾回收中引起JavaScript线程暂停执行的时间,在这样的时间花销下,应用的性能和响应能力都会直线下降
- 关于V8,作为虚拟机,V8的性能表现优异。
- Node中通过JavaScript使用内存时就会发现只能使用部分内存(64位系统下约为1.4 GB,32位系统下约为0.7 GB)。
手动打开node内存限制
1 | // 设置老生代内存空间的最大值 |
2. V8的对象分配
在V8中,所有的JavaScript对象都是通过堆来进行分配的。
1 | // heapTotal和heapUsed是V8的堆内存使用情况, |
3. V8的垃圾回收机制
V8的垃圾回收策略主要基于分代式垃圾回收机制。在自动垃圾回收的演变过程中,人们发现没有一种垃圾回收算法能够胜任所有的场景。因为在实际的应用中,对象的生存周期长短不一,不同的算法只能针对特定情况具有最好的效果
- a、v8的内存分代
在V8中,主要将内存分为新生代和老生代两代。新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象

- b、Scavenge算法
在Scavenge的具体实现中,主要采用了Cheney算法; Cheney算法是一种采用复制的方式实现的垃圾回收算法。它将堆内存一分为二,每一部分空间称为semispace。在这两个semispace空间中,只有一个处于使用中,另一个处于闲置状态。处于使用状态的semispace空间称为From空间,处于闲置状态的空间称为To空间。当我们分配对象时,先是在From空间中进行分配。当开始进行垃圾回收时,会检查From空间中的存活对象,这些存活对象将被复制到To空间中,而非存活对象占用的空间将会被释放。

当一个对象经过多次复制依然存活时,它将会被认为是生命周期较长的对象。这种较长生命周期的对象随后会被移动到老生代中,采用新的算法进行管理。对象从新生代中移动到老生代中的过程称为晋升。
对象晋升的条件主要有两个:1、一个是对象是否经历过Scavenge回收,2、一个是To空间的内存(to空间超过25%)占用比超过限制。
c、Mark-Sweep & Mark-Compact (标记清除 & 标记整理)
对于老生代中的对象,由于存活对象占较大比重,再采用Scavenge的方式会有两个问题:一个是存活对象较多,复制存活对象的效率将会很低;另一个问题依然是浪费一半空间的问题。这两个问题导致应对生命周期较长的对象时Scavenge会显得捉襟见肘。为此,V8在老生代中主要采用了Mark-Sweep和Mark-Compact相结合的方式进行垃圾回收
**Mark-Sweep是标记清除的意思,它分为标记和清除两个阶段。**Mark-Sweep只清理死亡对象。活对象在新生代中只占较小部分,死对象在老生代中只占较小部分,这是两种回收方式能高效处理的原因
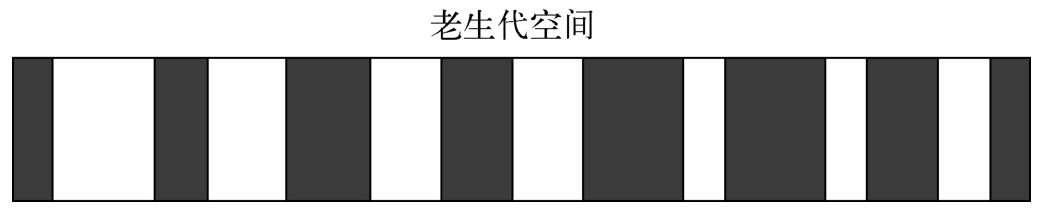
- **Mark-Compact是标记整理的意思,是在Mark-Sweep的基础上演变而来的。**它们的差别在于对象在标记为死亡后,在整理的过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存
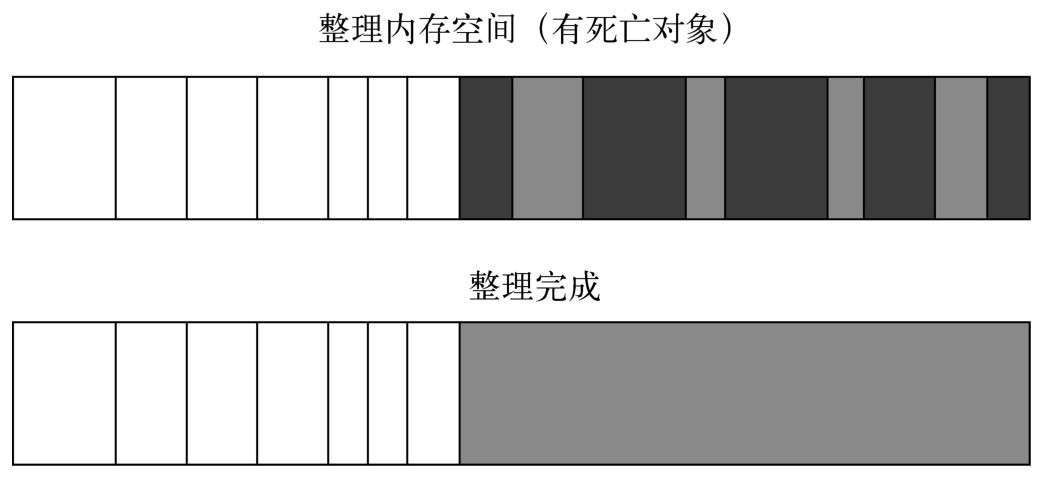
- d、3种垃圾回收算法的简单对比

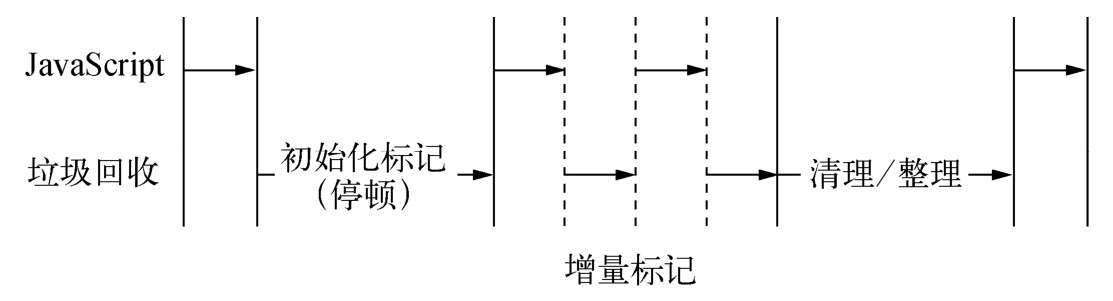
- e、增量标记
为了避免出现JavaScript应用逻辑与垃圾回收器看到的不一致的情况,垃圾回收的3种基本算法都需要将应用逻辑暂停下来,待执行完垃圾回收后再恢复执行应用逻辑,这种行为被称为“全停顿”(stop-the-world)
- f、查看垃圾回收日志
- 查看垃圾回收日志的方式主要是在启动时添加–trace_gc参数
- 通过在Node启动时使用–prof参数,可以得到V8执行时的性能分析数据,其中包含了垃圾回收执行时占用的时间
查看内存指标
应用中存在一些全局性的对象是正常的,而且在正常的使用中,变量都会自动释放回收。但是也会存在一些我们认为会回收但是却没有被回收的对象,这会导致内存占用无限增长。一旦增长达到V8的内存限制,将会得到内存溢出错误,进而导致进程退出
查看内存使用情况
- a、查看进程内存占用:process.memoryUsage()可以看到Node进程的内存占用情况
1 | var showMem = function () { |
- b、查看系统的内存占用
os模块中的totalmem()和freemem()这两个方法用于查看操作系统的内存使用情况
堆外内存
通过process.memoryUsage()的结果可以看到,堆中的内存用量总是小于进程的常驻内存用量,这意味着Node中的内存使用并非都是通过V8进行分配的。我们将那些不是通过V8分配的内存称为堆外内存
1 | var useMem = function () { |
heapTotal与heapUsed的变化极小,唯一变化的是rss的值,并且该值已经远远超过V8的限制值。这其中的原因是Buffer对象不同于其他对象,它不经过V8的内存分配机制,所以也不会有堆内存的大小限制。
为何Buffer对象并非通过V8分配?这在于Node并不同于浏览器的应用场景。在浏览器中,JavaScript直接处理字符串即可满足绝大多数的业务需求,而Node则需要处理网络流和文件I/O流,操作字符串远远不能满足传输的性能需求。
总结
node的内存构成主要由通过V8进行分配的部分和node自行分配部分,受V8的垃圾回收机制限制主要是V8的堆内存
内存泄漏
造成内存泄漏的原因有如下几个: 1、缓存 2、队列消费不及时 3、作用域未释放
1. 慎将内存当缓存使用
一旦一个对象被当做缓存来使用,那就意味着它将会常驻在老生代中。缓存中存储的键越多,长期存活的对象也就越多,这将导致垃圾回收在进行扫描和整理时,对这些对象做无用功。所以在Node中,任何试图拿内存当缓存的行为都应当被限制。当然,这种限制并不是不允许使用的意思,而是要小心为之
a、缓存限制策略
需要加入一种策略来限制缓存无限制增长,例如LRU算法的缓存算法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26var LimitableMap = function (limit) {
this.limit = limit || 10;
this.map = {};
this.keys = [];
};
var hasOwnProperty = Object.prototype.hasOwnProperty;
LimitableMap.prototype.set = function (key, value) {
var map = this.map;
var keys = this.keys;
if (! hasOwnProperty.call(map, key)) {
if (keys.length === this.limit) {
var firstKey = keys.shift();
delete map[firstKey];
}
keys.push(key);
}
map[key] = value;
};
LimitableMap.prototype.get = function (key) {
return this.map[key];
};
module.exports = LimitableMap;b、缓存的解决方案
- 将缓存转移到外部,减少常驻内存的对象的数量,让垃圾回收更高效
- 进程之间可以共享缓存: 例如redis
2. 关注队列状态
在大多数应用场景下,消费的速度远远大于生产的速度,内存泄漏不易产生。但是一旦消费速度低于生产速度,将会形成堆积。
**例子:**有的应用会收集日志。如果欠缺考虑,也许会采用数据库来记录日志。日志通常会是海量的,数据库构建在文件系统之上,写入效率远远低于文件直接写入,于是会形成数据库写入操作的堆积,而JavaScript中相关的作用域也不会得到释放,内存占用不会回落,从而出现内存泄漏
解决方案:
- 通过监控系统产生报警并通知相关人员
- 任意异步调用都应该包含超时机制,一旦在限定的时间内未完成响应,通过回调函数传达超时异常,启动拒绝模式
内存排查
常见的内存排查工具
- v8-profiler:它可以用于对V8堆内存抓取快照和对CPU进行分析
- node-heapdump:它允许对V8堆内存抓取快照,用于事后分析。
- node-memwatch:
总结
排查内存泄漏的原因主要通过对堆内存进行分析而找到
大内存应用
在Node中,不可避免地还是会存在操作大文件的场景。由于Node的内存限制,操作大文件也需要小心,好在Node提供了stream模块用于处理大文件;Node中的大多数模块都有stream的应用,比如fs的createReadStream()和createWriteStream()方法可以分别用于创建文件的可读流和可写流,process模块中的stdin和stdout则分别是可读流和可写流的示例。
- fs.createReadStream 和 fs.createWriteStream 使用
1 | var reader = fs.createReadStream('in.txt'); |
可读流提供了管道方法pipe(),封装了data事件和写入操作。通过流的方式,上述代码不会受到V8内存限制的影响,有效地提高了程序的健壮性。
理解buffer
由于应用场景不同,在Node中,应用需要处理网络协议、操作数据库、处理图片、接收上传文件等,在网络流和文件的操作中,还要处理大量二进制数据,JavaScript自有的字符串远远不能满足这些需求,于是Buffer对象应运而生
Buffer的结构
a、介绍
1、由于Buffer太过常见,Node在进程启动时就已经加载了它,并将其放在全局对象(global)上。所以在使用Buffer时,无须通过require()即可直接使用;
2、Buffer是一个典型的JavaScript与C++结合的模块,它将性能相关部分用C++实现,将非性能相关的部分用JavaScript实现。
3、Buffer所占用的内存不是通过V8分配的,属于堆外内存。
b、buffer对象
Buffer对象类似于数组,它的元素为16进制的两位数,即0到255的数值。
1 | var str = "深入浅出node.js"; |
- c、buffer的内存分配
- Buffer对象的内存分配不是在V8的堆内存中,而是在Node的C++层面实现内存的申请的。因为处理大量的字节数据不能采用需要一点内存就向操作系统申请一点内存的方式,这可能造成大量的内存申请的系统调用,对操作系统有一定压力。为此Node在内存的使用上应用的是在C++层面申请内存、在JavaScript中分配内存的策略
- slab机制介绍:xxxxx
- d、总结
真正的内存是在Node的C++层面提供的,JavaScript层面只是使用它。当进行小而频繁的Buffer操作时,采用slab的机制进行**预先申请和事后分配,**使得JavaScript到操作系统之间不必有过多的内存申请方面的系统调用。对于大块的Buffer而言,则直接使用C++层面提供的内存,而无需细腻的分配操作。
Buffer的转换
- a、字符串转buffer
1 | //默认按UTF-8编码进行转码和存储 |
- b、buffer转字符串
1 | buf.toString([encoding], [start], [end]); |
Buffer的拼接
- buffer拼接
1 | var fs = require('fs'); |
中文乱码原因
- 模拟出现乱码:
1
2// 将文件可读流的每次读取的Buffer长度限制为11
var rs = fs.createReadStream('test.md', {highWaterMark: 11}); 1. 上面的诗歌中,“月”、“是”、“望”、“低”4个字没有被正常输出,取而代之的是3个?。产生这个输出结果的原因在于文件可读流在读取时会逐个读取Buffer;
2. 由于我们限定了Buffer对象的长度为11,因此只读流需要读取7次才能完成完整的读取;
3. 上文提到的buf.toString()方法默认以UTF-8为编码,中文字在UTF-8下占3个字节。所以第一个Buffer对象在输出时,只能显示3个字符,Buffer中剩下的2个字节(e6 9c)将会以乱码的形式显示。第二个Buffer对象的第一个字节也不能形成文字,只能显示乱码。于是形成一些文字无法正常显示的问题;
1. 上面的诗歌中,“月”、“是”、“望”、“低”4个字没有被正常输出,取而代之的是3个?。产生这个输出结果的原因在于文件可读流在读取时会逐个读取Buffer;
2. 由于我们限定了Buffer对象的长度为11,因此只读流需要读取7次才能完成完整的读取;
3. 上文提到的buf.toString()方法默认以UTF-8为编码,中文字在UTF-8下占3个字节。所以第一个Buffer对象在输出时,只能显示3个字符,Buffer中剩下的2个字节(e6 9c)将会以乱码的形式显示。第二个Buffer对象的第一个字节也不能形成文字,只能显示乱码。于是形成一些文字无法正常显示的问题;
- 临时解决方案
1
2
3var rs = fs.createReadStream('test.md', { highWaterMark: 11});
//该方法的作用是让data事件中传递的不再是一个Buffer对象,而是编码后的字符串
fs.setEncoding('utf8');虽然string_decoder模块很奇妙,但是它也并非万能药,它目前只能处理UTF-8、Base64和UCS-2/UTF-16LE这3种编码。所以,通过setEncoding()的方式不可否认能解决大部分的乱码问题,但并不能从根本上解决该问题
正确拼接buffer
- 通过iconv模块来转码
- 修改+=改成Buffer.concat()生成一个合并的Buffer对象
1 | var chunks = []; |
Buffer的性能
1. 介绍
Buffer在文件I/O和网络I/O中运用广泛,尤其在网络传输中,它的性能举足轻重。在应用中,我们通常会操作字符串,但一旦在网络中传输,都需要转换为Buffer,以进行二进制数据传输。
1 | var http = require('http'); |
2. 读取文件(fs.createReadStream)
fs.createReadStream()的工作方式是在内存中准备一段Buffer,然后在fs.read()读取时逐步从磁盘中将字节复制到Buffer中。完成一次读取时,则从这个Buffer中通过slice()方法取出部分数据作为一个小Buffer对象,再通过data事件传递给调用方。如果Buffer用完,则重新分配一个;如果还有剩余,则继续使用。
读取一个相同的大文件时,highWaterMark值的大小与读取速度的关系:该值越大,读取速度越快
网络编程
在Web领域,大多数的编程语言需要专门的Web服务器作为容器,如ASP、ASP.NET需要IIS作为服务器,PHP需要搭载Apache或Nginx环境等,JSP需要Tomcat服务器等。
Node提供了net、dgram、http、https这4个模块,分别用于处理TCP、UDP、HTTP、HTTPS。
构建TCP服务
1. tcp介绍
- TCP属于传输层协议, http属于应用层
- TCP是面向连接的协议,最显著的特征是传输之前要3次握手
2. 创建tcp
1 | /* |
1 | /* |
3. tcp事件
服务器事件,对于通过net.createServer()创建的服务器而言,它是一个EventEmitter实例。
- listening:在调用server.listen()绑定端口或者Domain Socket后触发,简洁写法为server.listen(port, listeningListener),
- connection:每个客户端套接字连接到服务器端时触发
- close:当服务器关闭时触发,在调用server.close()后,服务器将停止接受新的套接字连接,但保持当前存在的连接,等待所有连接都断开后,会触发该事件。
连接事件,服务器可以同时与多个客户端保持连接,对于每个连接而言是典型的可写可读Stream对象。
- data:当一端调用write()发送数据时,另一端会触发data事件,事件传递的数据即是write()发送的数据
4. 可读可写的stream流使用pipe()管道操作
由于TCP套接字是可写可读的Stream对象,可以利用pipe()方法巧妙地实现管道操作
1 | var net = require('net'); |
构建UDP服务
1. UDP和TCP区别
UDP和TCP都是处在传输层;UDP与TCP最大的不同是UDP不是面向连接的,由于UDP无须连接,资源消耗低,处理快速且灵活,所以常常应用在那种偶尔丢一两个数据包也不会产生重大影响的场景,比如音频、视频等。UDP目前应用很广泛,DNS服务即是基于它实现的。
2. 创建UDP套接字
UDP套接字一旦创建,既可以作为客户端发送数据,也可以作为服务器端接收数据
1 | var dgram = require('dgram'); |
3. 创建UDP服务端
若想让UDP套接字接收网络消息,只要调用dgram.bind(port,[address])方法对网卡和端口进行绑定即可
1 | var dgram = require("dgram"); |
4. 创建UDP客户端
1 | // client.js |
构建HTTP服务
1. 构建http服务
TCP与UDP都属于网络传输层协议,如果要构造高效的网络应用,就应该从传输层进行着手。但是对于经典的应用场景,则无须从传输层协议入手构造自己的应用,比如HTTP或SMTP等,这些经典的应用层协议对于普通应用而言绰绰有余。
1 | var http = require('http'); |
2. http报文
curl -v 127.0.0.1:5001看http原理
- 第一部分内容为经典的TCP的3次握手过程
1
2* Trying 127.0.0.1:5001...
* Connected to 127.0.0.1 (127.0.0.1) port 5001 (#0)- 第二部分是在完成握手之后,客户端向服务器端发送请求报文
1
2
3
4
5> GET / HTTP/1.1
> Host: 127.0.0.1:5001
> User-Agent: curl/7.77.0
> Accept: */*
>- 第三部分是服务器端完成处理后,向客户端发送响应内容,包括响应头和响应体
1
2
3
4
5
6
7
8
9
10
11
12
13< HTTP/1.1 200 OK
< X-Powered-By: Hexo
< Content-Type: text/html
< Date: Sat, 26 Mar 2022 08:48:21 GMT
< Connection: keep-alive
< Transfer-Encoding: chunked
<
<!DOCTYPE html>
<html lang="en">
<head><meta name="generator" content="Hexo 3.9.0">
...
...
...- 结束回话
1
* Connection #0 to host 127.0.0.1 left intact
从协议的角度来说,现在的应用,如浏览器,其实是一个HTTP的代理,用户的行为将会通过它转化为HTTP请求报文发送给服务器端,服务器端在处理请求后,发送响应报文给代理,代理在解析报文后,将用户需要的内容呈现在界面上。
以浏览器打开一张图片地址为例:首先,浏览器构造HTTP报文发向图片服务器端;然后,服务器端判断报文中的要请求的地址,将磁盘中的图片文件以报文的形式发送给浏览器;浏览器接收完图片后,调用渲染引擎将其显示给用户。
3. http模块
在Node中,HTTP服务继承自TCP服务器(net模块),它能够与多个客户端保持连接,由于其采用事件驱动的形式,并不为每一个连接创建额外的线程或进程,保持很低的内存占用,所以能实现高并发。HTTP服务与TCP服务模型有区别的地方在于,在开启keepalive后,一个TCP会话可以用于多次请求和响应。TCP服务以connection为单位进行服务,HTTP服务以request为单位进行服务。http模块即是将connection到request的过程进行了封装
http请求
对于TCP连接的读操作,http模块将其封装为ServerRequest对象。让我们再次查看前面的请求报文,报文头部将会通过http_parser进行解析1
2
3
4headers:
{ 'user-agent': 'curl/7.24.0 (x86_64-apple-darwin12.0) libcurl/7.24.0 OpenSSL/0.9.8r zlib/1.2.5',
host: '127.0.0.1:1337',
accept: '*/*' },http响应
- 我们可以调用setHeader进行多次设置,但只有调用writeHead后,报头才会写入到连接中
- 报文体部分则是调用res.write()和res.end()方法实现,后者与前者的差别在于res.end()会先调用write()发送数据,然后发送信号告知服务器这次响应结束
- 报头是在报文体发送前发送的,一旦开始了数据的发送,writeHead()和setHeader()将不再生效。这由协议的特性决定。
**http事件:**如同TCP服务一样,HTTP服务器也抽象了一些事件,以供应用层使用,同样典型的是,服务器也是一个EventEmitter实例
- connection事件:在开始HTTP请求和响应前,客户端与服务器端需要建立底层的TCP连接,这个连接可能因为开启了keep-alive,可以在多次请求响应之间使用;当这个连接建立时,服务器触发一次connection事件
- request事件:建立TCP连接后,http模块底层将在数据流中抽象出HTTP请求和HTTP响应,当请求数据发送到服务器端,在解析出HTTP请求头后,将会触发该事件;在res.end()后,TCP连接可能将用于下一次请求响应
- checkContinue事件:某些客户端在发送较大的数据时,并不会将数据直接发送,而是先发送一个头部带Expect: 100-continue的请求到服务器,服务器将会触发checkContinue事件
- upgrade事件:当客户端要求升级连接的协议时,需要和服务器端协商,客户端会在请求头中带上Upgrade字段,服务器端会在接收到这样的请求时触发该事件。这在后文的WebSocket部分有详细流程的介绍。如果不监听该事件,发起该请求的连接将会关闭。
构建websocket服务
1. node与websocket
WebSocket实现了客户端与服务器端之间的长连接,而Node事件驱动的方式十分擅长与大量的客户端保持高并发连接
2. websocket与http
- 客户端与服务器端只建立一个TCP连接,可以使用更少的连接。
- WebSocket服务器端可以推送数据到客户端,这远比HTTP请求响应模式更灵活、更高效。
- 有更轻量级的协议头,减少数据传送量
- 相比HTTP, WebSocket更接近于传输层协议,它并没有在HTTP的基础上模拟服务器端的推送,而是在TCP上定义独立的协议。让人迷惑的部分在于WebSocket的握手部分是由HTTP完成的,使人觉得它可能是基于HTTP实现的。
3. websocket握手阶段
- 和普通的http请求报文多这2个协议头, 表示升级到websocket协议
1 | ... |
- 服务端实现websocket
1 | var server = http.createServer(function (req, res) { |
- 客户端代码
1 | var WebSocket = function (url) { |
4. websocket传输数据阶段
websocket协议升级的过程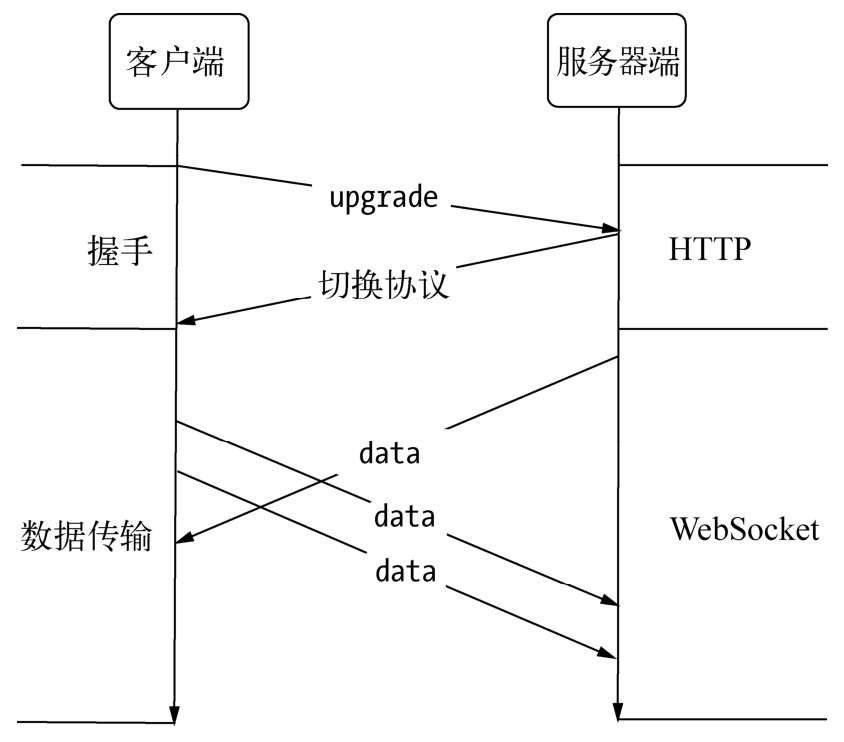
5. 总结
尽管Node没有内置WebSocket的库,但是社区的ws模块封装了WebSocket的底层实现。socket.io即是在它的基础上构建实现
- Node基于事件驱动的方式使得它应对WebSocket这类长连接的应用场景可以轻松地处理大量并发请求
- 基于JavaScript,以封装良好的WebSocket实现,API与客户端可以高度相似。
进程
1. 服务模型变迁
- 石器时代:同步
它的服务模式是一次只为一个请求服务,所有请求都得按次序等待服务。 - 青铜时代:复制进程
为了解决同步架构的并发问题,一个简单的改进是通过进程的复制同时服务更多的请求和用户。这样每个连接都需要一个进程来服务,即100个连接需要启动100个进程来进行服务,这是非常昂贵的代价。 - 白银时代:多线程
为了解决进程复制中的浪费问题,多线程被引入服务模型,让一个线程服务一个请求。线程相对进程的开销要小许多,并且线程之间可以共享数据,内存浪费的问题可以得到解决,并且利用线程池可以减少创建和销毁线程的开销。 - 黄金时代:事件驱动
node多进程目的:CPU的利用率和进程的健壮性
所有处理都在单线程上进行,影响事件驱动服务模型性能的点在于CPU的计算能力,它的上限决定这类服务模型的性能上限,但它不受多进程或多线程模式中资源上限的影响,可伸缩性远比前两者高。如果解决掉多核CPU的利用问题,带来的性能上提升是可观的
2. 多进程架构
- 介绍
面对单进程单线程对多核使用不足的问题,前人的经验是启动多进程即可。理想状态下每个进程各自利用一个CPU,以此实现多核CPU的利用。所幸,Node提供了child_process模块,并且也提供了child_process.fork()函数供我们实现进程的复制。
1 | // worker.js |
- 主从模式(master-worker)
主进程和工作进程。这是典型的分布式架构中用于并行处理业务的模式,具备较好的可伸缩性和稳定性。主进程不负责具体的业务处理,而是负责调度或管理工作进程,它是趋向于稳定的。工作进程负责具体的业务处理.
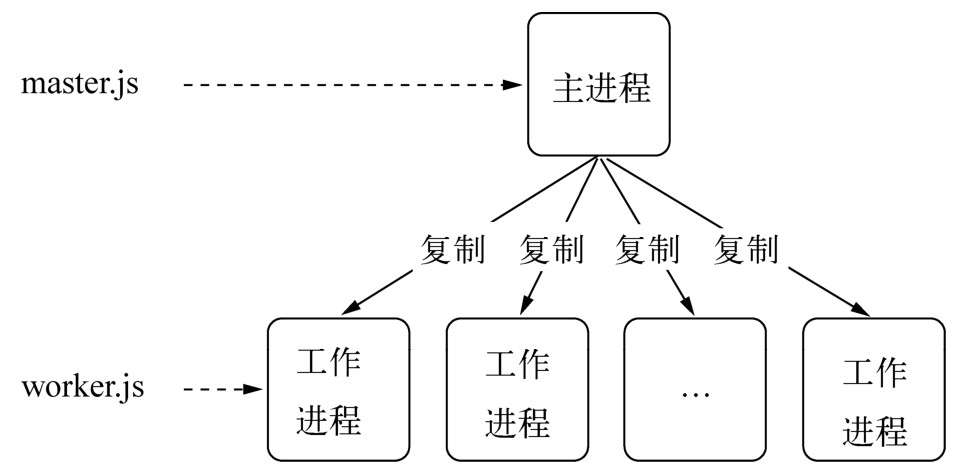
- 创建子进程
- spawn():启动一个子进程来执行命令。
- exec():启动一个子进程来执行命令,与spawn()不同的是其接口不同,它有一个回调函数获知子进程的状况。
- execFile():启动一个子进程来执行可执行文件。
- fork():与spawn()类似,不同点在于它创建Node的子进程只需指定要执行的JavaScript文件模块即可。

1 | var cp = require('child_process'); |
1 | // parent.js |
- 进程间通信原理
IPC的全称是Inter-Process Communication,即进程间通信。进程间通信的目的是为了让不同的进程能够互相访问资源并进行协调工作。实现进程间通信的技术有很多,如命名管道、匿名管道、socket、信号量、共享内存、消息队列、DomainSocket等。Node中实现IPC通道的是管道(pipe)技术。
表现在应用层上的进程间通信只有简单的message事件和send()方法,接口十分简洁和消息化。图为IPC创建和实现的示意图。
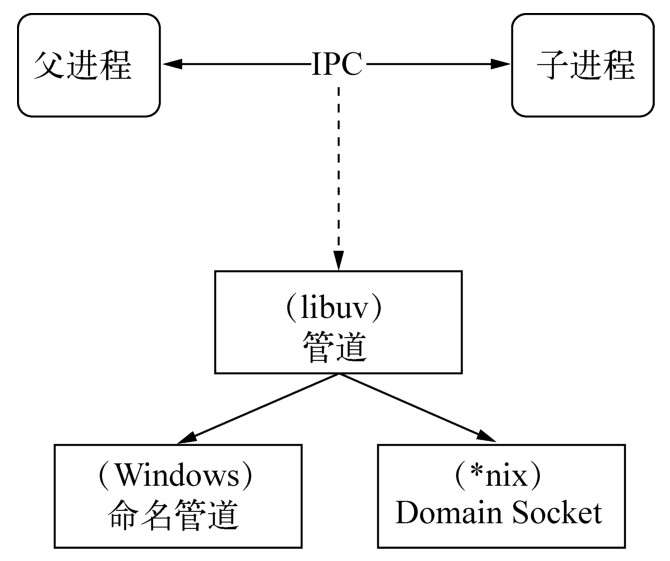
父进程在实际创建子进程之前,会创建IPC通道并监听它,然后才真正创建出子进程,并通过环境变量(NODE_CHANNEL_FD)告诉子进程这个IPC通道的文件描述符。子进程在启动的过程中,根据文件描述符去连接这个已存在的IPC通道,从而完成父子进程之间的连接。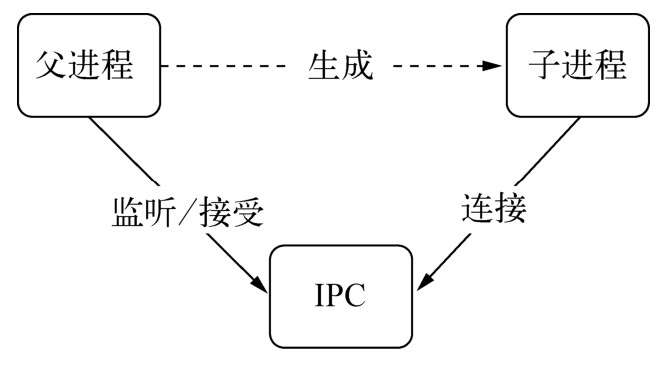
只有启动的子进程是Node进程时,子进程才会根据环境变量去连接IPC通道,对于其他类型的子进程则无法实现进程间通信,除非其他进程也按约定去连接这个已经创建好的IPC通道
句柄传递
端口被占用早期解决方案
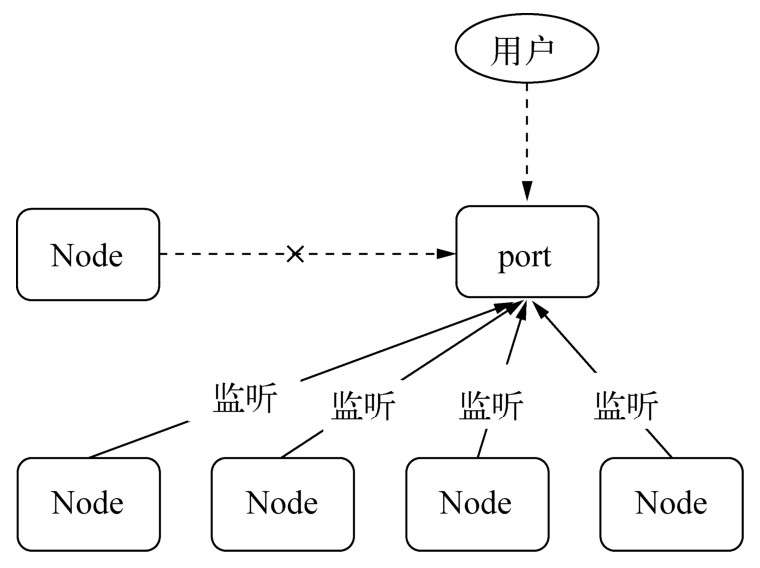
在监听的过程中都抛出了EADDRINUSE异常,这是端口被占用的情况,新的进程不能继续监听该端口了。这个问题破坏了我们将多个进程监听同一个端口的想法。要解决这个问题,通常的做法是让每个进程监听不同的端口,其中主进程监听主端口(如80),主进程对外接收所有的网络请求,再将这些请求分别代理到不同的端口的进程上。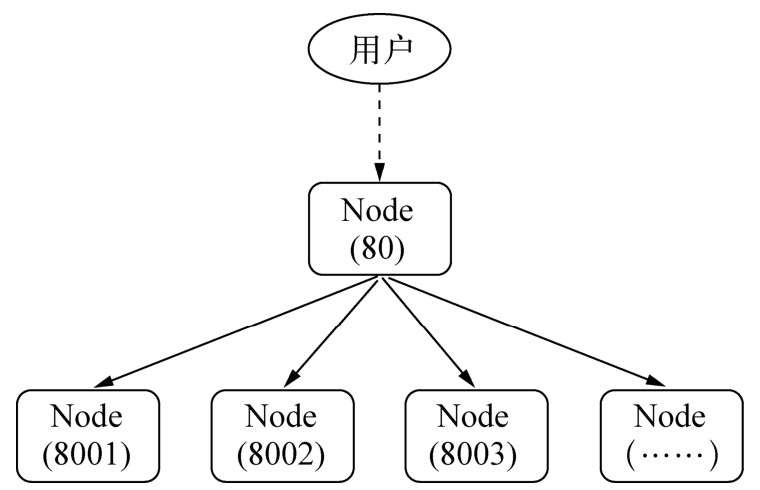
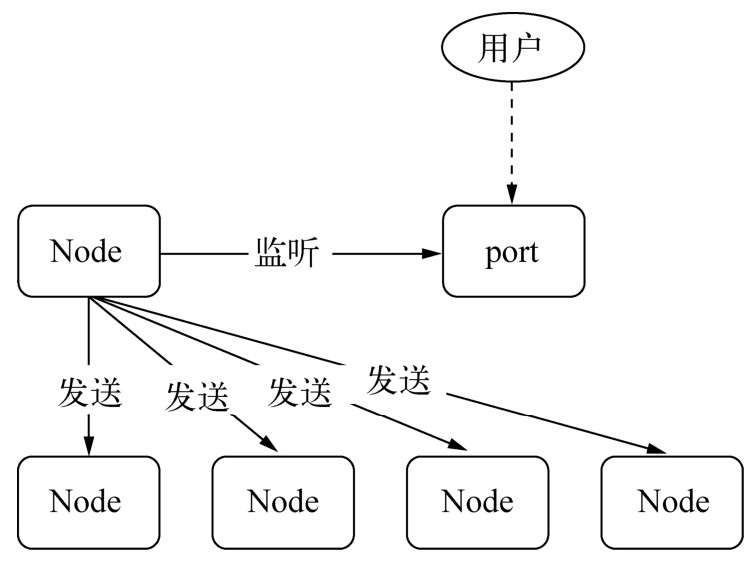
只用一个端口的解决方案(多个子进程可以同时监听相同端口)
**句柄是一种可以用来标识资源的引用,它的内部包含了指向对象的文件描述符。**比如句柄可以用来标识一个服务器端socket对象、一个客户端socket对象、一个UDP套接字、一个管道等。发送句柄意味着什么?在前一个问题中,我们可以去掉代理这种方案,使主进程接收到socket请求后,将这个socket直接发送给工作进程,而不是重新与工作进程之间建立新的socket连接来转发数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// parent.js
var cp = require('child_process');
var child1 = cp.fork('child.js');
var child2 = cp.fork('child.js');
// Open up the server object and send the handle
var server = require('net').createServer();
// server.on('connection', function (socket) {
// socket.end('handled by parent\n');
// });
server.listen(1337, function () {
child1.send('server', server);
child2.send('server', server);
// 对于主进程而言,我们甚至想要它更轻量一点,
// 那么是否将服务器句柄发送给子进程之后,就可以关掉服务器的监听,让子进程来处理请求呢
server.close();
});
// child.js
var http = require('http');
var server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('handled by child, pid is ' + process.pid + '\n');
});
process.on('message', function (m, tcp) {
if (m === 'server') {
tcp.on('connection', function (socket) {
server.emit('connection', socket);
});
}
});
句柄传送和还原
发送到IPC管道中的实际上是我们要发送的句柄文件描述符,文件描述符实际上是一个整数值。这个message对象在写入到IPC管道时也会通过JSON.stringify()进行序列化。所以最终发送到IPC通道中的信息都是字符串,send()方法能发送消息和句柄并不意味着它能发送任意对象。
连接了IPC通道的子进程可以读取到父进程发来的消息,将字符串通过JSON.parse()解析还原为对象后,才触发message事件将消息体传递给应用层使用。

- 端口共同监听
多个进程可以监听到相同的端口而不引起EADDRINUSE异常。其答案也很简单,我们独立启动的进程中,TCP服务器端socket套接字的文件描述符并不相同,导致监听到相同的端口时会抛出异常。
Node底层对每个端口监听都设置了SO_REUSEADDR选项,这个选项的涵义是不同进程可以就相同的网卡和端口进行监听,这个服务器端套接字可以被不同的进程复用。由于独立启动的进程互相之间并不知道文件描述符,所以监听相同端口时就会失败。但对于send()发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同端口不会引起异常。1
setsockopt(tcp->io_watcher.fd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on))
3. 集群稳定
搭建好了集群,充分利用了多核CPU资源,似乎就可以迎接客户端大量的请求了。 但是会出现以后几个需要主要的:多个工作进程的存活状态管理、工作进程的平滑重启、配置或者静态数据的动态重新载入
a、进程事件
- error:当子进程无法被复制创建、无法被杀死、无法发送消息时会触发该事件
- exit:子进程退出时触发该事件,子进程如果是正常退出,这个事件的第一个参数为退出码,否则为null。如果进程是通过kill()方法被杀死的,会得到第二个参数,它表示杀死进程时的信号。
- close:在子进程的标准输入输出流中止时触发该事件,参数与exit相同
- disconnect:在父进程或子进程中调用disconnect()方法时触发该事件,在调用该方法时将关闭监听IPC通道。
1 | /* |
b、自动重启
- 主进程加入子进程管理机制
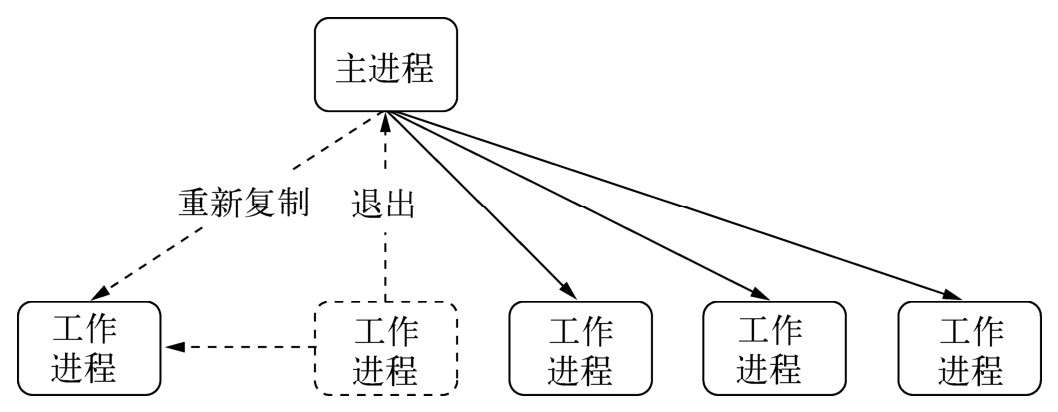
我们能够通过监听子进程的exit事件来获知其退出的信息,接着前文的多进程架构,我们在主进程上要加入一些子进程管理的机制,比如重新启动一个工作进程来继续服务。
1 | // master.js |
- 自杀信号(平滑重启)
在极端的情况下,所有工作进程都停止接收新的连接,全处在等待退出的状态。但在等到进程完全退出才重启的过程中,所有新来的请求可能存在没有工作进程为新用户服务的情景,这会丢掉大部分请求。
为此需要改进这个过程,不能等到工作进程退出后才重启新的工作进程。当然也不能暴力退出进程,因为这样会导致已连接的用户直接断开。于是我们在退出的流程中增加一个自杀(suicide)信号。工作进程在得知要退出时,向主进程发送一个自杀信号,然后才停止接收新的连接,当所有连接断开后才退出。主进程在接收到自杀信号后,立即创建新的工作进程服务。

1 | // master.js |
优点:与前一种方案相比,创建新工作进程在前,退出异常进程在后。至此我们完成了进程的平滑重启,一旦有异常出现,主进程会创建新的工作进程来为用户服务,旧的进程一旦处理完已有连接就自动断开。整个过程使得我们的应用的稳定性和健壮性大大提高。
- 限量重启
通过自杀信号告知主进程可以使得新连接总是有进程服务,但是依然还是有极端的情况。工作进程不能无限制地被重启,如果启动的过程中就发生了错误,或者启动后接到连接就收到错误,会导致工作进程被频繁重启。
c、负载均衡
- 在多进程之间监听相同的端口,使得用户请求能够分散到多个进程上进行处理,这带来的好处是可以将CPU资源都调用起来;
- Node默认提供的机制是采用操作系统的抢占式策略。所谓的抢占式就是在一堆工作进程中,闲着的进程对到来的请求进行争抢,谁抢到谁服务;
- 这种抢占式策略对大家是公平的,各个进程可以根据自己的繁忙度来进行抢占。但是对于Node而言,需要分清的是它的繁忙是由CPU、I/O两个部分构成的,影响抢占的是CPU的繁忙度。对不同的业务,可能存在I/O繁忙,而CPU较为空闲的情况,这可能造成某个进程能够抢到较多请求,形成负载不均衡的情况;
- 为此Node在v0.11中提供了一种新的策略使得负载均衡更合理,**这种新的策略叫Round-Robin,又叫轮叫调度。**轮叫调度的工作方式是由主进程接受连接,将其依次分发给工作进程。分发的策略是在N个工作进程中,每次选择第i = (i + 1) mod n个进程来发送连接。
d、状态共享
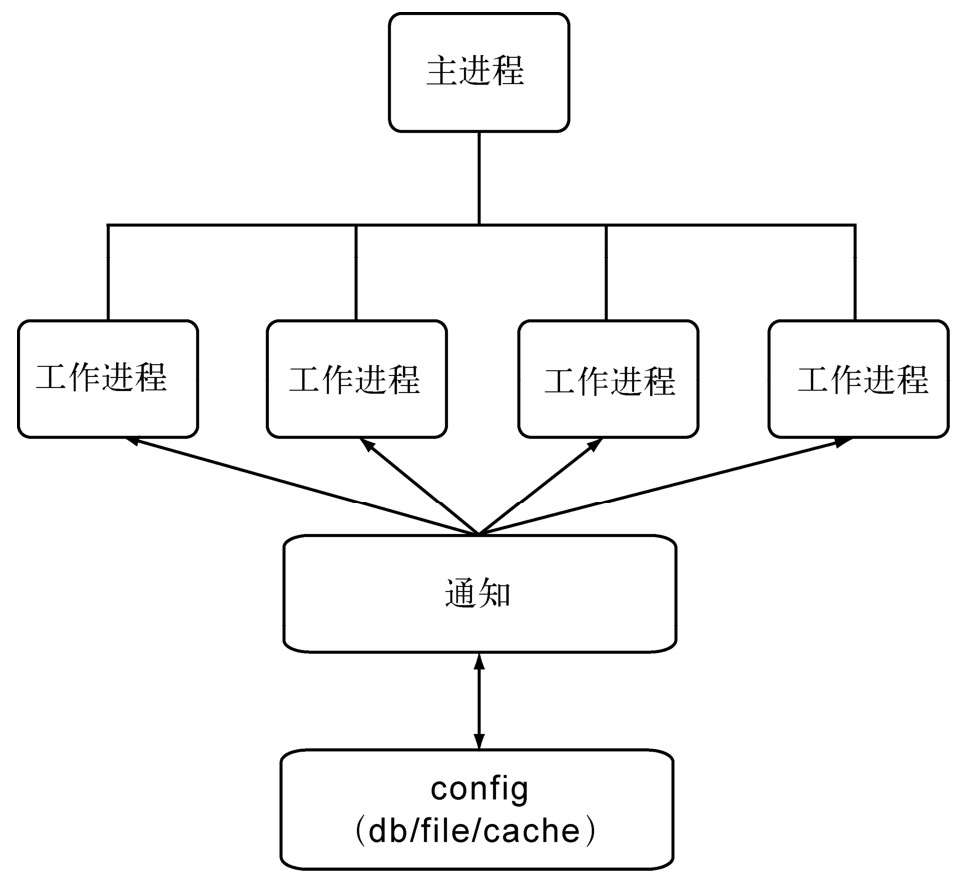
我们知道在Node进程中不宜存放太多数据,因为它会加重垃圾回收的负担,进而影响性能。同时,Node也不允许在多个进程之间共享数据。但在实际的业务中,往往需要共享一些数据,譬如配置数据,这在多个进程中应当是一致的。为此,在不允许共享数据的情况下,我们需要一种方案和机制来实现数据在多个进程之间的共享。
第三方存储数据
解决数据共享最直接、简单的方式就是通过第三方来进行数据存储,比如将数据存放到数据库、磁盘文件、缓存服务(如Redis)中,所有工作进程启动时将其读取进内存中。但这种方式存在的问题是如果数据发生改变,还需要一种机制通知到各个子进程,使得它们的内部状态也得到更新。
主动通知
一种改进的方式是当数据发生更新时,主动通知子进程。当然,即使是主动通知,也需要一种机制来及时获取数据的改变。这个过程仍然不能脱离轮询,但我们可以减少轮询的进程数量,我们将这种用来发送通知和查询状态是否更改的进程叫做通知进程。为了不混合业务逻辑,可以将这个进程设计为只进行轮询和通知,不处理任何业务逻辑。
这种推送机制如果按进程间信号传递,在跨多台服务器时会无效,是故可以考虑采用TCP或UDP的方案。进程在启动时从通知服务处除了读取第一次数据外,还将进程信息注册到通知服务处。一旦通过轮询发现有数据更新后,根据注册信息,将更新后的数据发送给工作进程
4. cluster模块
a. 使用方式
1 | // 官方推荐 |
在进程中判断是主进程还是工作进程,主要取决于环境变量中是否有NODE_UNIQUE_ID
1 | cluster.isWorker = ('NODE_UNIQUE_ID' in process.env); |
b. cluster工作原理
cluster模块就是child_process和net模块的组合应用。cluster启动时,它会在内部启动TCP服务器,在cluster.fork()子进程时,将这个TCP服务器端socket的文件描述符发送给工作进程。如果进程是通过cluster.fork()复制出来的,那么它的环境变量里就存在NODE_UNIQUE_ID,如果工作进程中存在listen()侦听网络端口的调用,它将拿到该文件描述符,通过SO_REUSEADDR端口重用,从而实现多个子进程共享端口。对于普通方式启动的进程,则不存在文件描述符传递共享等事情。
c. cluster事件
- fork:复制一个工作进程后触发该事件
- online:复制好一个工作进程后,工作进程主动发送一条online消息给主进程,主进程收到消息后,触发该事件。
- listening:工作进程中调用listen()(共享了服务器端Socket)后,发送一条listening消息给主进程,主进程收到消息后,触发该事件
- disconnect:主进程和工作进程之间IPC通道断开后会触发该事件。
- exit:有工作进程退出时触发该事件。
- setup:cluster.setupMaster()执行后触发该事件
构建web应用
1、基础功能
- 请求方法
1 | function (req, res) { |
- 路径解析
1 | function (req, res) { |
http://user:pass@host.com:8080/p/a/t/h?query=string#hash hash部分会被丢弃,不会存在于报文的任何地方
- 查询字符串
1 | function (req, res) { |
- cookie
1 | var parseCookie = function (cookie) { |
- session
- 缓存
1 | // 文件的时间戳改动但内容并不一定改动。 |
尽管条件请求可以在文件内容没有修改的情况下节省带宽,但是它依然会发起一个HTTP请求,使得客户端依然会花一定时间来等待响应。可见最好的方案就是连条件请求都不用发起
1 | var handle = function (req, res) { |
2、数据上传
通过报头的Transfer-Encoding或Content-Length即可判断请求中是否带有内容。
1 | var hasBody = function(req) { |
表单提交
1 | // 表单格式 |
文件提交
值得注意的一点是,由于是文件上传,那么像普通表单、JSON或XML那样先接收内容再解析的方式将变得不可接受。接收大小未知的数据量时,我们需要十分谨慎。
1 | /** |
数据上传的安全
- 内存限制
❑ 限制上传内容的大小,一旦超过限制,停止接收数据,并响应400状态码。
❑ 通过流式解析,将数据流导向到磁盘中,Node只保留文件路径等小数据。
1 | var bytes = 1024; |
- CSRF(跨站请求伪造)
解决CSRF攻击的方案有添加随机值的方式。 为每个请求的用户,在Session中赋予一个随机值;在做页面渲染的过程中,将这个_csrf值告之前端;所以我们只需要在接收端做一次校验就能轻易地识别出该请求是否为伪造的
3、路由解析
4、中间件
对于Web应用而言,我们希望不用接触到这么多细节性的处理,为此我们引入中间件(middleware)来简化和隔离这些基础设施与业务逻辑之间的细节,让开发者能够关注在业务的开发上,以达到提升开发效率的目的。
实现中间件
中间件的上下文也就是请求对象和响应对象:req和res。有一点区别的是,由于Node异步的原因,我们需要提供一种机制,在当前中间件处理完成后,通知下一个中间件执行。
1 | var match = function (pathname, routes) { |
异常处理
如果某个中间件出现错误该怎么办?我们需要为自己构建的Web应用的稳定性和健壮性负责。于是我们为next()方法添加err参数,并捕获中间件直接抛出的同步异常
1 | var handle500 = function (err, req, res, stack) { |
中间件与性能
- 编写高效的中间件: 缓存需要重复计算的结果、避免不必要的计算。比如HTTP报文体的解析,对于GET方法完全不需要。
- 合理利用路由,避免不必要的中间件执行: 例如静态文件中间件 app.use(‘/public’,staticFile);
5、页面渲染
内容响应
客户端在接收到这个报文后,正确的处理过程是通过gzip来解码报文体中的内容,用长度校验报文体内容是否正确,然后再以字符集UTF-8将解码后的脚本插入到文档节点中
1 | Content-Encoding: gzip |
- mime
浏览器正是通过不同的Content-Type的值来决定采用不同的渲染方式,这个值我们简称为MIME值。 - 附件下载
Content-Disposition字段影响的行为是客户端会根据它的值判断是应该将报文数据当做即时浏览的内容,还是可下载的附件。当内容只需即时查看时,它的值为inline,当数据可以存为附件时,它的值为attachment。另外,Content-Disposition字段还能通过参数指定保存时应该使用的文件名。示例如下
1 | Content-Disposition: attachment; filename="filename.ext" |
附件下载示例:
1 | res.sendfile = function (filepath) { |
- 响应json
1 | res.json = function (json) { |
- 重定向
1 | res.redirect = function (url) { |
视图渲染
1 | res.render = function (view, data) { |
模板
这个模板引擎会将Hello <%= username%>转换为”Hello “ + obj.username。该过程进行以下几个步骤。
❑ 语法分解。提取出普通字符串和表达式,这个过程通常用正则表达式匹配出来,<% =%>的正则表达式为/<%=([\s\S]+?)%>/g。
❑ 处理表达式。将标签表达式转换成普通的语言表达式。
❑ 生成待执行的语句。
❑ 与数据一起执行,生成最终字符串。
1 | var render = function (str, data) { |
模板编译
为了能够最终与数据一起执行生成字符串,我们需要将原始的模板字符串转换成一个函数对象。比如Hello<%=username%>这句模板字符串,最终会生成如下的代码:
1 | function (obj) { |
这个过程称为模板编译,生成的中间函数只与模板字符串相关,与具体的数据无关。如果每次都生成这个中间函数,就会浪费CPU。为了提升模板渲染的性能速度,我们通常会采用模板预编译的方式。
1 | var complie = function (str) { |
通过预编译缓存模板编译后的结果,实际应用中就可以实现一次编译,多次执行,而原始的方式每次执行过程中都要进行一次编译和执行。
模板性能
❑ 缓存模板文件。
❑ 缓存模板文件编译后的函数。
1 | res.render = function (viewname, data) { |
node产品化
项目工程化
- 目录结构
- 构建工具: shell
- 编码规范:lint和typescript
- 代码审查
部署流程
a、部署环境
预发布环境与普通的测试环境的差别在于它的数据较为接近线上真实的数据, 也就是所谓的灰度环境。
b、部署操作
- 以 nohup 和 & 后台方式启动服务
1 | nohup node app.js & |
1 |
|
部署的过程只要执行下面bash脚本:
./appctl.sh start
./appctl.sh stop
./appctl.sh restart
- pm2方式操作进程
性能
a、动静分离
Node尽管也能通过中间件实现静态文件服务,但是Node处理静态文件的能力并不算突出。将图片、脚本、样式表和多媒体等静态文件都引导到专业的静态文件服务器上,让Node只处理动态请求即可。这个过程可以用Nginx或者专业的CDN来处理。静态文件请求分离后,对静态请求使用不同的域名或多个域名还能消除掉不必要的Cookie传输和浏览器对下载线程数的限制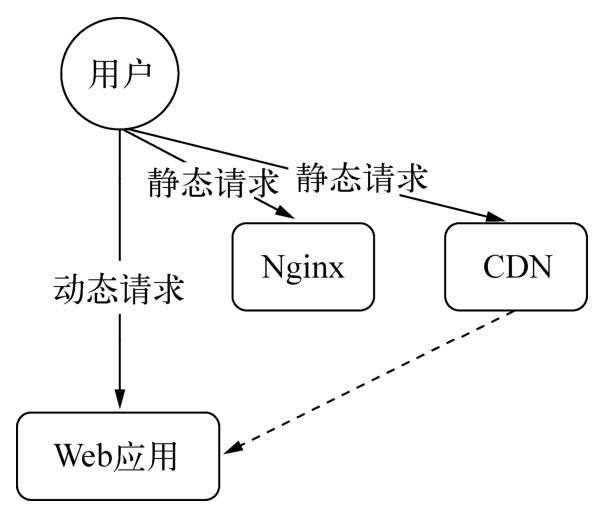
b、启用缓存
提升性能其实差不多只有两个途经,一是提升服务的速度,二是避免不必要的计算。前者提升的性能在海量流量面前终有瓶颈,但后者却能够在访问量越大时收益越多。避免不必要的计算,应用场景最多的就是缓存
c、多进程架构
通过多进程架构,不仅可以充分利用多核CPU,更是可以建立机制让Node进程更加健壮,以保障Web应用持续服务。由于Node是通过自有模块构建HTTP服务器的,不像大多数服务器端技术那样有专有的Web容器,所以需要开发者自己处理多进程的管理。不过好在官方已经有cluster模块,在社区也有pm、forever、pm2这样的模块用于进程管理
d、读写分离
就任意数据库而言,读取的速度远远高于写入的速度。而某些数据库在写入时为了保证数据一致性,会进行锁表操作,这同时会影响到读取的速度。某些系统为了提升性能,通常会进行数据库的读写分离,将数据库进行主从设计,这样读数据操作不再受到写入的影响,降低了性能的影响
e、分布式部署
通过多机器集群化分布式部署,可以加强应用的健壮性
日志
a、访问日志
中间件框架Connect在其众多中间件中提供了一个日志中间件,通过它可以将关键数据按一定格式输出到日志文件中
b、异常日志
❑ console.log:普通日志
❑ console.info:普通信息
❑ console.warn:警告信息
❑ console.error:错误信息
1 | /** |
c、日志和数据库
有的开发者对日志可能不太了解,会选择将一些日志写入到数据库中。数据库比日志文件好的地方在于它是结构化数据,可以直接编写SQL语句进行分析,日志文件则需要再加工之后才能分析。
但是日志文件与数据库写入在性能上处于两个级别,数据库在写入过程中要经历一系列处理,比如锁表、日志等操作。写日志文件则是直接将数据写到磁盘上。为此,如果有大量的访问,可能会存在写入操作大量排队的状况,数据库的消费速度严重低于生产速度,进而导致内存泄漏等。
相比之下,写日志是轻量的方法,将日志分析和日志记录这两个步骤分离开来是较好的选择。日志记录可以在线写,日志分析则可以借助一些工具同步到数据库中,通过离线分析的方式反馈出来
d、分隔日志
线上业务可能访问量巨大,产生的日志也可能是大量的,上述示例只是简单地将普通日志和异常日志分开放在两个文件中,日志过多时也不便直接查看。为此,将产生的日志按日期分割是一个不错的主意。
监控告警
服务监控的手段, 按层次可以划分为:
- 系统层(CPU、网络状态、IO、机器负载等)
- 应用层(进程状态、错误日志、吞吐量等)
- 业务层(服务/接口的错误码、响应时间)
- 用户层(用户行为、舆情监控、前端埋点)
应用的监控主要有两类,一种是业务逻辑型的监控,一种是硬件型的监控。监控主要通过定时采样来进行记录。除此之外,还要对监控的信息设置上限,一旦出现大的波动,就需要发出警报提醒开发者。
a、监控
- **日志监控:**从访问日志中也能实现PV和UV的监控。同QPS值一样,通过对PV/UV的监控,可以很好地知道应用的使用者们的习惯、预知访问高峰
- **响应时间:**响应时间可以在Nginx一类的反向代理上监控,也可以通过应用自行产生的访问日志来监控
- **进程监控:**监控进程一般是检查操作系统中运行的应用进程数,比如对于采用多进程架构的Web应用,就需要检查工作进程的数量,如果低于预估值,就应当发出报警声
- 磁盘监控:
- **内存监控:**如果内存只升不降,那么铁定存在内存泄漏问题。健康的内存使用应当是有升有降,在访问量大的时候上升,在访问量回落的时候,占用量也随之回落
- **cpu监控:**CPU的使用分为用户态、内核态、IOWait等。如果用户态CPU使用率较高,说明服务器上的应用需要大量的CPU开销;如果内核态CPU使用率较高,说明服务器花费大量时间进行进程调度或者系统调用;IOWait使用率则反应的是CPU等待磁盘I/O操作
- **cpu负载:**CPU load过高说明进程数量过多,这在Node中可能体现在用子进程模块反复启动新的进程
- **I/O负载:**I/O负载指的主要是磁盘I/O。反应的是磁盘上的读写情况,对于Node编写的应用,主要是面向网络服务,是故不太可能出现I/O负载过高的情况,大多数的I/O压力来自于数据库
- **网络监控:**流入流量和流出流量
b、告警
- 邮件或企业微信告警
- 电话告警
稳定性
a、多机器
但是一旦出现分布式,就需要考虑负载均衡、状态共享和数据一致性等问题。
b、多机房
c、容灾备份
测试
1、单元测试
单元测试主要用于检测代码的行为是否符合预期
2、性能测试
在完成代码的行为检测后,还需要对已有代码的性能作出评估,检测已有功能是否能满足生产环境的性能要求,能否承担实际业务带来的压力。换句话说,性能也是功能
- 基准测试
基准测试要统计的就是在多少时间内执行了多少次某个方法。为了增强可比性,一般会以次数作为参照物,然后比较时间,以此来判别性能的差距
1 | // Array.prototype.map |
为了得到更规范和更好的输出结果,这里介绍benchmark这个模块是如何组织基准测试的。
- 压力测试
对网络接口做压力测试需要考查的几个指标有**吞吐率、响应时间和并发数,**这些指标反映了服务器的并发处理能力。最常用的工具是ab、siege、http_load等
[同步与异步、阻塞与非阻塞傻傻分不清楚?你得从linux中的5种IO模型看起](https://juejin.cn/post/7119034398078402568)