Buffer和Stream的区别
Buffer是数据以二进制形式临时存放在内存中的物理映射,stream为搬运数据的传送带和加工器,有方向、状态、缓冲大小
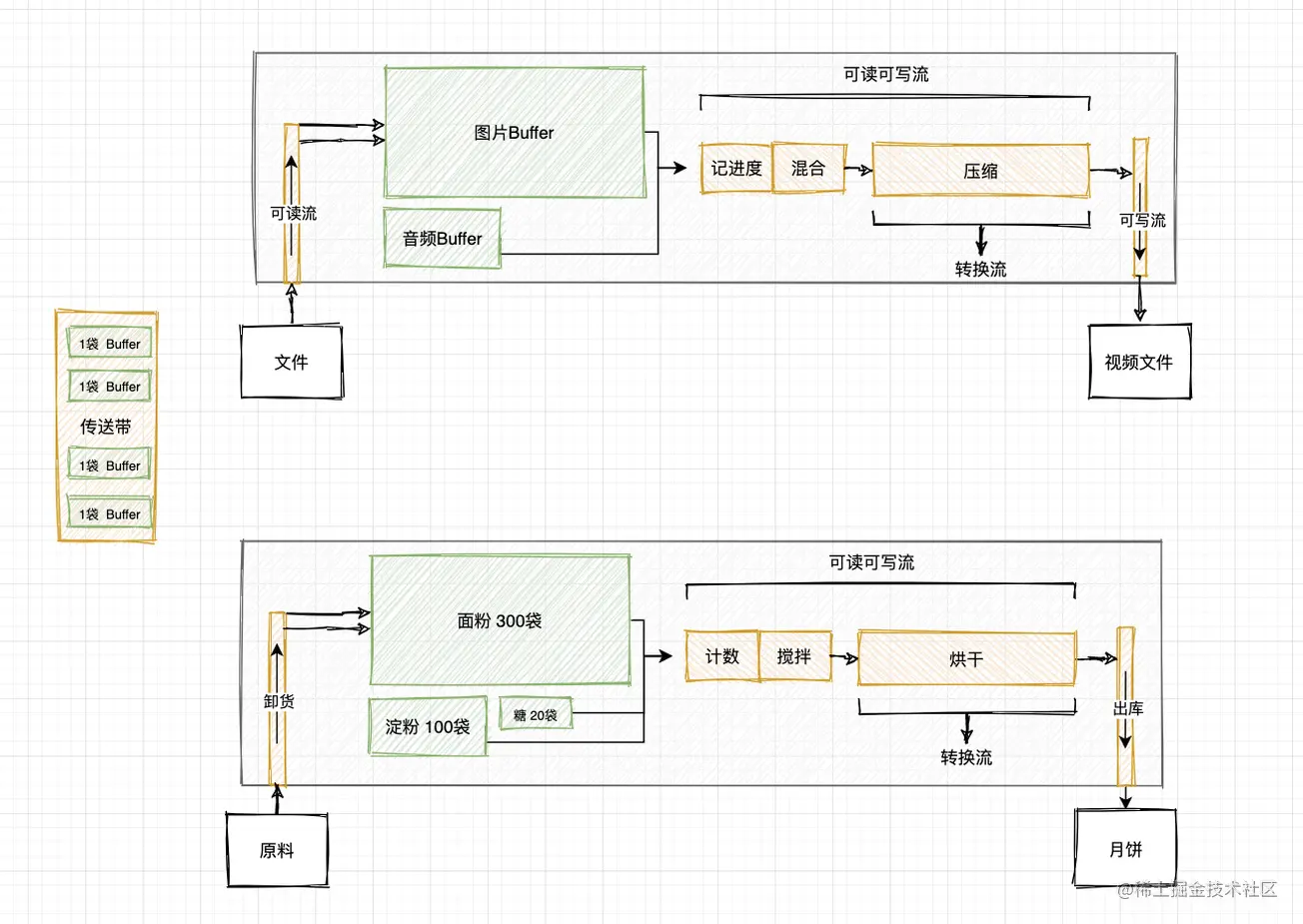
Buffer
介绍
就像摆渡车一样,坐满了20位才发车(程序可以决定何时发生数据),乘客有早到有晚到(程序无法控制数据流到达的时间),必须有一个地方等候,这就是车站(程序中缓冲区[buffer])
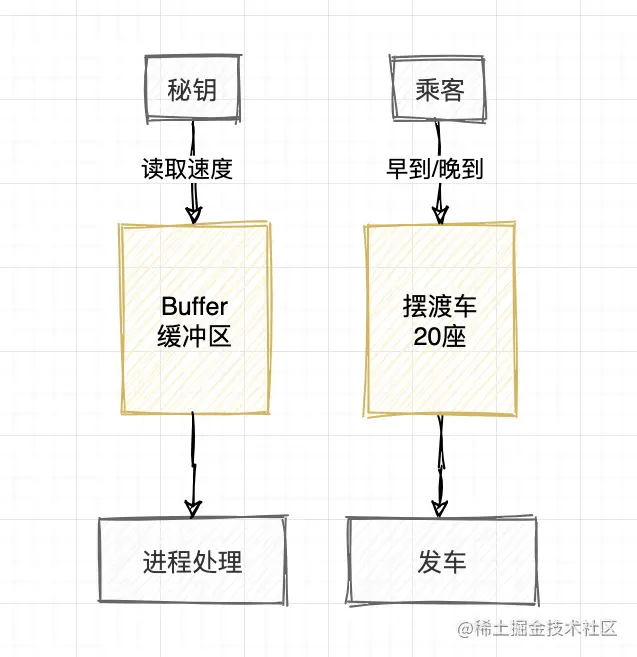
Buffer和Cache
- 缓冲(Buffer)是用于处理二进制流数据,将数据缓冲起来,它是临时性的,对于流式数据,会采用缓冲区将数据临时存储起来,等缓冲到一定的大小之后在存入硬盘中。视频播放器就是一个经典的例子
- 缓存(Cache)我们可以看作是一个中间层,它可以是永久性的将热点数据进行缓存,使得访问速度更快,例如我们通过 Memory、Redis 等将数据从硬盘或其它第三方接口中请求过来进行缓存,目的就是将数据存于内存的缓存区中,这样对同一个资源进行访问,速度会更快,也是性能优化一个重要的点
Buffer和String
1、性能对比
1 | const http = require('http'); |
2、相互转换
1 | // string --> buffer |
- Buffer => utf8:如遇到非UTF-8数据会转换为 �。
- Buffer => utf16le:每个字符会使用2或4个字节进行编码。
- Buffer => latin1:指定了Unicode编码范围,超出会截断并映射为范围内的字符串。
buffer不支持的编码类型,gbk、gb2312等可以借助js工具包iconv-lite实现
使用场景
- I/O 操作:关于 I/O 可以是文件或网络 I/O
- 文件压缩:zlib.js 为 Node.js 的核心库之一,其利用了缓冲区(Buffer)的功能来操作二进制数据流,提供了压缩或解压功能
内存分配机制
由于 Buffer 需要处理的是大量的二进制数据,假如用一点就向系统去申请,则会造成频繁的向系统申请内存调用,所以 Buffer 所占用的内存不再由 V8 分配,而是在 Node.js 的 C++ 层面完成申请,在 JavaScript 中进行内存分配。因此,这部分内存我们称之为堆外内存。
- 在初次加载时就会初始化 1 个 8KB 的内存空间
- 根据申请的内存大小分为 小 Buffer 对象 和 大 Buffer 对象(通过8KB来区分)
- 小 Buffer 情况,会继续判断这个 slab 空间是否足够
- 如果空间足够就去使用剩余空间同时更新 slab 分配状态,偏移量会增加
- 如果空间不足,slab 空间不足,就会去创建一个新的 slab 空间用来分配
- 大Buffer 情况,则会直接走 createUnsafeBuffer(size) 函数
- 不论是小 Buffer 对象还是大 Buffer 对象,内存申请是在 C++ 层面完成,内存管理在 JavaScript 层面,最终还是可以被 V8 的垃圾回收标记所回收
Stream
介绍
流(stream)是 Node.js 中处理流式数据的抽象接口。 stream 模块用于构建实现了流接口的对象。
Node.js 提供了多种流对象。 例如,HTTP 服务器的请求和 process.stdout 都是流的实例。
流可以是可读的(Readable)、可写的(Writable)、可读可写(Duplex)或者操作被写入数据,然后读出结果(Transform)
我们现在有一大罐水需要浇一片菜地,如果我们将水罐的水一下全部倒入菜地,首先得需要有多么大的力气(这里的力气好比计算机中的硬件性能)才可搬得动。如果,我们拿来了水管将水一点一点流入我们的菜地,这个时候不要这么大力气就可完成
使用
常用事件
- data - 当有数据可读时触发。
- end - 没有更多的数据可读时触发。
- error - 在接收和写入过程中发生错误时触发。
- finish - 所有数据已被写入到底层系统时触发
所有的 Stream 对象都是 EventEmitter 的实例
fs
readFile和writeFile
- readFile方法是将要读取的文件内容完整读入缓存区,再从该缓存区中读取文件内容
1 | const readFile = (file) => new Promise((resolve, reject) => { |
- writeFile方法是将要写入的文件内容完整的读入缓存区,然后一次性的将缓存区中的内容写入都文件中
1 | const writeFile = (file, contents) => new Promise((resolve, reject) => { |
以上的读写操作,Node.js将文件内容视为一个整体,为其分配缓存区并且一次性将文件内容读取到缓存区中,在这个期间,Node.js将不能执行任何其他处理。所以当读写大文件的时候,有可能造成缓存区“爆仓”
read和write
- read方法读取文件内容是不断地将文件中的一小块内容读入缓存区,最后从该缓存区中读取文件内容
1 | const read = (file) => new Promise((resolve, reject) => { |
- write方法执行过程:1将需要写入的数据写入到一个内存缓存区;2待缓存区写满后再将缓存区中的内容写入到文件中;3重复执行步骤1和步骤2,直到数据全部写入文件为止
1 | var fs = require('fs'); |
以上读写操作,node.js会将文件分成一块一块逐步操作,在读写文件过程中允许执行其他操作
createReadStream和createWriteStream
- createReadStream方法创建一个将文件内容读取为流数据的ReadStream对象
1 | // 创建一个可以读的流,读取文件 file 内容 |
- createWriteStream方法创建一个将流数据写入文件中的WriteStream对象
1 | // 创建一个可以写入的流,写入到文件 file 中 |
- pipe
1 | var fs = require("fs"); |
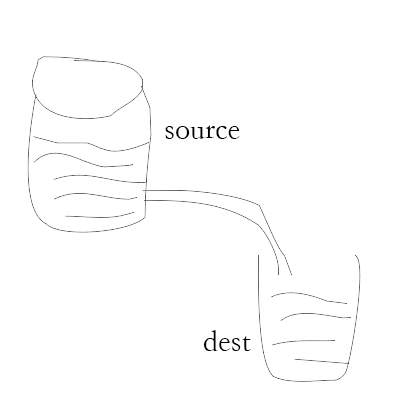
如上面的图片所示,我们把文件比作装水的桶,而水就是文件里的内容,我们用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就慢慢的实现了大文件的复制过程
[文章来源于1](https://juejin.cn/post/6955331683499376676#heading-1) [文章来源于2](https://mp.weixin.qq.com/s/UU-Gug_Dx-OmXVL-99rWRg) [文章来源于3](https://mp.weixin.qq.com/s/huPERCsDnDpk6jRnbD6n-Q)