一、基本概念
任何语言的核心都必然会描述这门语言最基本的工作原理。而描述的内容通常都要涉及这门语言的语法、操作符、数据类型、内置功能等用于构建复杂解决方案的基本概念。
1、语法
1.1 区分大小写
ECMAScript中的一切(变量、函数名和操作符)都区分大小写。这也就意味着,变量名test和变量名Test分别表示两个不同的变量。
1.2 标识符
第一个字符必须是一个字母、下划线(_)或一个美元符号($);
1.3 语句
ECMAScript中的语句以一个分号结尾;如果省略分号,则由解析器确定语句的结尾。加上分号也会在某些情况下增进代码的性能,因为这样解析器就不必再花时间推测应该在哪里插入分号了。
2、数据类型
JS基本数据类型:String、Number、Boolean、Undefined、Null、Symbol、BigInt;Object本质上是由一组无序的名值对组成的
ECMAScript中也有一种复杂的数据类型,即Object类型,该类型是这门语言中所有对象的基础类型。
2.1 typeof操作符
对一个值使用typeof操作符可能返回下列某个字符串:
- “undefined”——如果这个值未定义;
- “boolean”——如果这个值是布尔值;
- “string”——如果这个值是字符串;
- “symbol”——如果这个值是symbol;
- “number”——如果这个值是数值;
- “object”——如果这个值是对象或null;
- “function”——如果这个值是函数。
2.2 Undefined类型
Undefined类型只有一个值,即特殊的undefined。在使用var声明变量但未对其加以初始化时,这个变量的值就是undefined。
对于尚未声明过的变量,只能执行一项操作,即使用typeof操作符检测其数据类型。
2.3 Null类型
从逻辑角度来看,null值表示一个空对象指针,而这也正是使用typeof操作符检测null值时会返回”object”的原因。
1 | typeof null // 'object' |
尽管null和undefined有这样的关系,但它们的用途完全不同。如前所述,无论在什么情况下都没有必要把一个变量的值显式地设置为undefined,可是同样的规则对null却不适用。换句话说,只要意在保存对象的变量还没有真正保存对象,就应该明确地让该变量保存null值。这样做不仅可以体现null作为空对象指针的惯例,而且也有助于进一步区分null和undefined。
2.4 Number类型
2.4.1 NaN
NaN,即非数值(Not a Number)是一个特殊的数值,这个数值用于表示一个本来要返回数值的操作数未返回数值的情况(这样就不会抛出错误了)。例如,在其他编程语言中,任何数值除以非数值都会导致错误,从而停止代码执行。但在ECMAScript中,任何数值除以非数值会返回NaN,因此不会影响其他代码的执行。
NaN与任何值都不相等,包括NaN本身
2.4.2 数值转换
Number()、parseInt()和parseFloat()
Number()函数的转换规则如下:
- 如果是Boolean值,true和false将分别被转换为1和0。
- 如果是数字值,只是简单的传入和返回
- 如果是null值,返回0
- 如果是undefined,返回NaN。
- 如果是对象,则调用对象的valueOf()方法,然后依照前面的规则转换返回的值。如果转换的结果是NaN,则调用对象的toString()方法,然后再次依照前面的规则转换返回的字符串值
- 如果是字符串,遵循下列规则:
- 如果字符串中只包含数字(包括前面带正号或负号的情况),则将其转换为十进制数值,即”1”会变成1, “123”会变成123,而”011”会变成11(注意:前导的零被忽略了);
- 如果字符串中包含有效的浮点格式,如”1.1”,则将其转换为对应的浮点数值(同样,也会忽略前导零)
- 如果字符串中包含有效的十六进制格式,例如”0xf”,则将其转换为相同大小的十进制整数值。
parseInt()函数
parseInt()函数在转换字符串时,更多的是看其是否符合数值模式。它会忽略字符串前面的空格,直至找到第一个非空格字符。
- 如果第一个字符不是数字字符或者负号,parseInt()就会返回NaN;也就是说,用parseInt()转换空字符串会返回NaN(Number()对空字符返回0)
- 如果第一个字符是数字字符,parseInt()会继续解析第二个字符,直到解析完所有后续字符或者遇到了一个非数字字符
不指定基数意味着让parseInt()决定如何解析输入的字符串,因此为了避免错误的解析,我们建议无论在什么情况下都明确指定基数。
1 | let num1 = parseInt("10", 2) // 2 按二进制解析 |
2.5 String类型
2.5.1 转换为字符串
要把一个值转换为一个字符串有三种方式:
- 第一种是使用几乎每个值都有的toString()方法;
- 在不知道要转换的值是不是null或undefined的情况下,还可以使用转型函数String(),这个函数能够将任何类型的值转换为字符串。String()函数遵循下列转换规则
- 如果值有toString()方法,则调用该方法(没有参数)并返回相应的结果;
- 如果值是null,则返回”null”;
- 如果值是undefined,则返回”undefined”。
- 可以使用加号操作符把它与一个字符串(””)加在一起
2.6 Object类型
对象其实就是一组数据和功能的集合。
Object类型是所有它的实例的基础。换句话说,Object类型所具有的任何属性和方法也同样存在于更具体的对象中。
2.6.1 创建
1 | let o = new Object(); |
2.6.2 Object每个实例具有以下属性和方法
- constructor: 保存着用于创建当前对象函数, 对应当前的例子,构造函数(constructor)就是Object;
- hasOwnProperty(propertyName): 用于检查给定的属性在当前对象实例中(而不是在实例原型中)是否存在;
- isPrototypeOf(object): 用于检查传入的对象是否是当前对象的原型;
- propertyIsEnumerable(propertyName): 用于检查给定的属性是否能够使用for-in语句来枚举;
- toString():返回对象的字符串表示;
- valueOf():返回对象的字符串、数值或布尔值表示。通常与toString()方法的返回值相同。
3、操作符
3.1 一元操作符
3.1.1 递增和递减操作符
前置递增和递减操作时,变量的值都是在语句被求值以前改变的;后置递增和递减与前置递增和递减有一个非常重要的区别,即递增和递减操作是在包含它们的语句被求值之后才执行的
1 | // 前置 |
它们不仅适用于整数,还可以用于字符串、布尔值、浮点数值和对象
- 在应用于一个包含有效数字字符的字符串时,先将其转换为数字值,再执行加减1的操作。字符串变量变成数值变量。
- 在应用于对象时,先调用对象的valueOf()方法以取得一个可供操作的值。然后对该值应用前述规则。如果结果是NaN,则在调用toString()方法后再应用前述规则。对象变量变成数值变量
3.2 位操作符
3.3 乘性操作符
3.3.1 乘法
- 如果有一个操作数是NaN,则结果是NaN;
- 如果是Infinity与0相乘,则结果是NaN;
- 如果是Infinity与非0数值相乘,则结果是Infinity或-Infinity,取决于有符号操作数的符号;
- 如果是Infinity与Infinity相乘,则结果是Infinity;
- 如果有一个操作数不是数值,则在后台调用Number()将其转换为数值,然后再应用上面的规则。
3.3.2 求模
1 | let result = 26 % 5; // 1 |
求模相关规则:
- 如果被除数是零,则结果是零
- 如果有一个操作数不是数值,则在后台调用Number()将其转换为数值,然后再应用上面的规则
3.4 加性操作符
3.4.1 加法
相关规则:
- 如果有一个操作数是对象、数值或布尔值,则调用它们的toString()方法取得相应的字符串值,然后再应用前面关于字符串的规则。对于undefined和null,则分别调用String()函数并取得字符串”undefined”和”null”。
3.4.2 减法
相关规则:
- 如果有一个操作数是字符串、布尔值、null或undefined,则先在后台调用Number()函数将其转换为数值,然后再根据前面的规则执行减法计算。如果转换的结果是NaN,则减法的结果就是NaN;
- 如果有一个操作数是对象,则调用对象的valueOf()方法以取得表示该对象的数值。如果得到的值是NaN,则减法的结果就是NaN。如果对象没有valueOf()方法,则调用其toString()方法并将得到的字符串转换为数值
4、流程控制语句
4.1 do-while语句
do-while语句是一种后测试循环语句,即只有在循环体中的代码执行之后,才会测试出口条件。换句话说,在对条件表达式求值之前,循环体内的代码至少会被执行一次。
1 | var i = 0; |
4.2 for语句
由于ECMAScript中不存在块级作用域,因此在循环内部定义的变量也可以在外部访问到。
1 | for (var i=0; i<10; i++){ |
for语句中的初始化表达式、控制表达式和循环后表达式都是可选的。将这三个表达式全部省略,就会创建一个无限循环
1 | for (; ;){ |
4.3 for-in语句
ECMAScript对象的属性没有顺序。因此,通过for-in循环输出的属性名的顺序是不可预测的。具体来讲,所有属性都会被返回一次,但返回的先后次序可能会因浏览器而异
4.4 break和continue语句
break语句会立即退出循环,强制继续执行循环后面的语句。而continue语句虽然也是立即退出循环,但退出循环后会从循环的顶部继续执行
4.5 with语句
with语句的作用是将代码的作用域设置到一个特定的对象中;定义with语句的目的主要是为了简化多次编写同一个对象的工作
1 | var qs=location.search.substring(1); |
with语句的代码块内部,每个变量首先被认为是一个局部变量,而如果在局部环境中找不到该变量的定义,就会查询location对象中是否有同名的属性。如果发现了同名属性,则以location对象属性的值作为变量的值。 如果locaion没有在window全局对象找。
4.6 switch语句
虽然ECMAScript中的switch语句借鉴自其他语言,但这个语句也有自己的特色。首先,可以在switch语句中使用任何数据类型(在很多其他语言中只能使用数值),无论是字符串,还是对象都没有问题。其次,每个case的值不一定是常量,可以是变量,甚至是表达式。
switch语句在比较值时使用的是全等操作符,因此不会发生类型转换(例如,字符串”10”不等于数值10)。
1 | switch ("hello"){ |
5、函数
5.1 参数
ECMAScript函数不介意传递进来多少个参数,也不在乎传进来参数是什么数据类型。也就是说,即便你定义的函数只接收两个参数,在调用这个函数时也未必一定要传递两个参数。可以传递一个、三个甚至不传递参数,而解析器永远不会有什么怨言。之所以会这样,原因是ECMAScript中的参数在内部是用一个数组来表示的。函数接收到的始终都是这个数组,而不关心数组中包含哪些参数(如果有参数的话)。如果这个数组中不包含任何元素,无所谓;如果包含多个元素,也没有问题。实际上,在函数体内可以通过arguments对象来访问这个参数数组,从而获取传递给函数的每一个参数。
arguments对象只是与数组类似(它并不是Array的实例),因为可以使用方括号语法访问它的每一个元素(即第一个元素是arguments[0],第二个元素是arguments[1],以此类推),使用length属性来确定传递进来多少个参数。
1 | function doNum(num1, num2){ |
每次执行这个doAdd()函数都会重写第二个参数,将第二个参数的值修改为10。因为arguments对象中的值会自动反映到对应的命名参数,所以修改arguments[1],也就修改了num2,结果它们的值都会变成10。不过,这并不是说读取这两个值会访问相同的内存空间;它们的内存空间是独立的,但它们的值会同步。
没有传递值的命名参数将自动被赋予undefined值。这就跟定义了变量但又没有初始化一样。例如,如果只给doAdd()函数传递了一个参数,则num2中就会保存undefined值。
重点:ECMAScript中的所有参数传递的都是值,不可能通过引用传递参数。
5.2 没有重载
ECMAScript函数不能像传统意义上那样实现重载。而在其他语言(如Java)中,可以为一个函数编写两个定义,只要这两个定义的签名(接受的参数的类型和数量)不同即可。如前所述,ECMAScirpt函数没有签名,因为其参数是由包含零或多个值的数组来表示的。而没有函数签名,真正的重载是不可能做到的。
二、变量、作用域和内存问题
JavaScript的变量与其他语言的变量有很大区别。JavaScript变量松散类型的本质,决定了它只是在特定时间用于保存特定值的一个名字而已。由于不存在定义某个变量必须要保存何种数据类型值的规则,变量的值及其数据类型可以在脚本的生命周期内改变。尽管从某种角度看,这可能是一个既有趣又强大,同时又容易出问题的特性,
1、基本类型和引用类型的值
1.1 基本类型和引用类型的值
基本类型值指的是简单的数据段,而引用类型值指那些可能由多个值构成的对象。
引用类型的值是保存在内存中的对象。与其他语言不同,JavaScript不允许直接访问内存中的位置,也就是说不能直接操作对象的内存空间。在操作对象时,实际上是在操作对象的引用而不是实际的对象。为此,引用类型的值是按引用访问的。
1.1.1 动态的属性
我们不能给基本类型的值添加属性,尽管这样做不会导致任何错误;
1 | let name = 'cha'; |
1.1.2 复制变量值
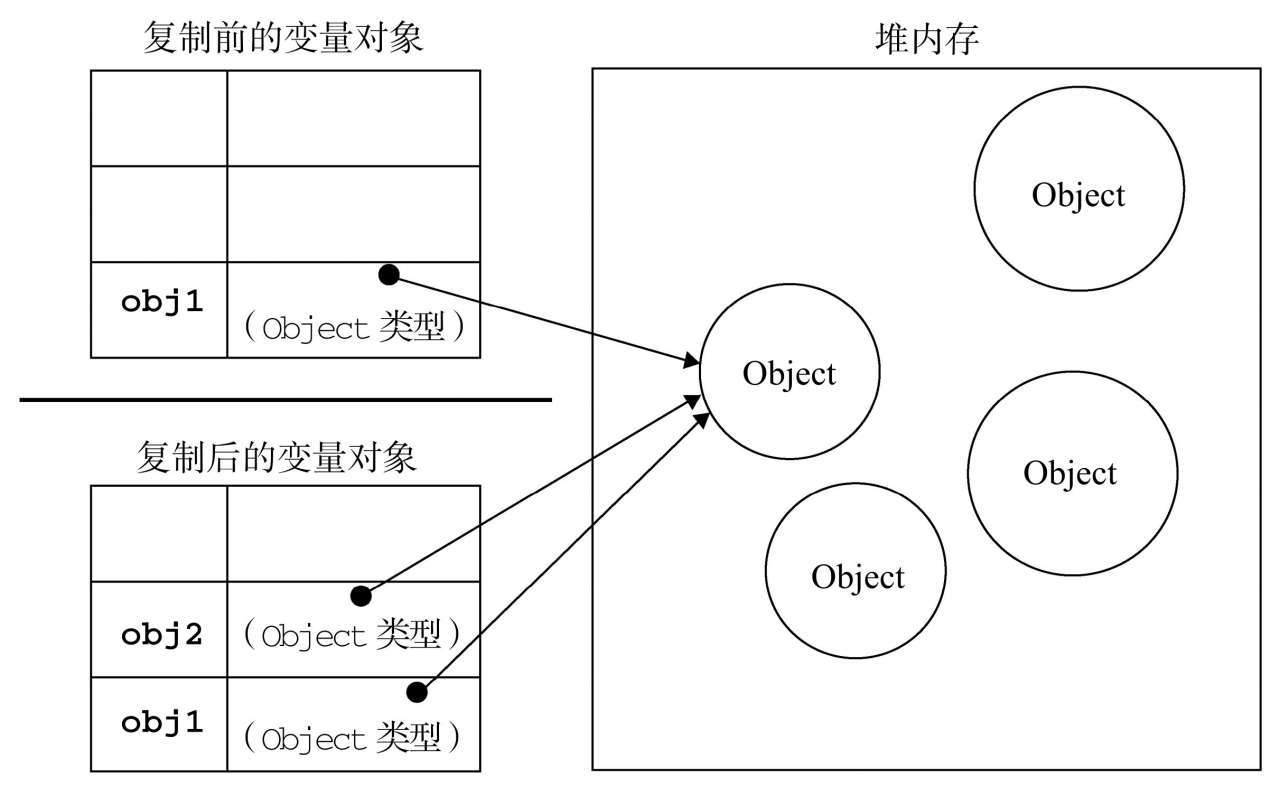
当从一个变量向另一个变量复制引用类型的值时,同样也会将存储在变量对象中的值复制一份放到为新变量分配的空间中。不同的是,这个值的副本实际上是一个指针,而这个指针指向存储在堆中的一个对象。复制操作结束后,两个变量实际上将引用同一个对象。因此,改变其中一个变量,就会影响另一个变量,
1 | var obj1=new Object(); |
1.1.3 传递参数
ECMAScript中所有函数的参数都是按值传递的。也就是说,把函数外部的值复制给函数内部的参数,就和把值从一个变量复制到另一个变量一样。
1 | // 基本类型 |
关于引用类型错误的理解:
因为person指向的对象在堆内存中只有一个,而且是全局对象。有很多开发人员错误地认为:在局部作用域中修改的对象会在全局作用域中反映出来,就说明参数是按引用传递的。
关于引用类型正确理解:
在把person传递给setName()后,其name属性被设置为”Nicholas”。然后,又将一个新对象赋给变量obj,同时将其name属性设置为”Greg”。如果person是按引用传递的,那么person就会自动被修改为指向其name属性值为”Greg”的新对象。但是,当接下来再访问person.name时,显示的值仍然是”Nicholas”
1.1.4 检测类型
typeof操作符是确定一个变量是字符串、数值、布尔值,还是undefined的最佳工具。如果变量的值是一个对象或null,则typeof操作符会像下面例子中所示的那样返回”object”。
所有引用类型的值都是Object的实例。因此,在检测一个引用类型值和Object构造函数时,instanceof操作符始终会返回true。
1 | // 无法区分Object 和 其他类型 |
2、执行环境和作用域
执行环境(execution context,为简单起见,有时也称为“环境”)是JavaScript中最为重要的一个概念。执行环境定义了变量或函数有权访问的其他数据,决定了它们各自的行为。
内部环境可以通过作用域链访问所有的外部环境,但外部环境不能访问内部环境中的任何变量和函数。
2.1 延长作用域链
2.2 没有块级作用域(es6 let实现)
这里是在一个if语句中定义了变量color。如果是在C、C++或Java中,color会在if语句执行完毕后被销毁。但在JavaScript中,if语句中的变量声明会将变量添加到当前的执行环境(在这里是全局环境)中。在使用for语句时尤其要牢记这一差异
1 | for (var i=0; i < 10; i++){ |
3、垃圾回收
这种垃圾收集机制的原理其实很简单:找出那些不再继续使用的变量,然后释放其占用的内存。为此,垃圾收集器会按照固定的时间间隔(或代码执行中预定的收集时间),周期性地执行这一操作。
3.1 标记清除
3.2 引用计数
3.3 性能问题
3.4 管理内存
解除一个值的引用并不意味着自动回收该值所占用的内存。解除引用的真正作用是让值脱离执行环境,以便垃圾收集器下次运行时将其回收。
1 | function createPerson(name){ |
三、引用类型
1、Object类型
2、Array类型
2.1 创建
1 | let color = new Array(3); // 创建包含3项数组 |
2.2 检测数组
1 | // 方法一 |
2.3 数组api
栈方法
具体说来,数组可以表现得就像栈一样,后者是一种可以限制插入和删除项的数据结构。栈是一种LIFO(Last-In-First-Out,后进先出)的数据结构,也就是最新添加的项最早被移除。push(推入最后一项) 和 pop (获取最后一项)
队列方法
队列数据结构的访问规则是FIFO(First-In-First-Out,先进先出) unshift(推入第一项) 和 pop(获取最后一项)
重排序方法
reverse()方法会反转数组项的顺序
sort()方法按升序排列数组项——即最小的值位于最前面,最大的值排在最后面。为了实现排序,sort()方法会调用每个数组项的toString()转型方法,然后比较得到的字符串,以确定如何排序。即使数组中的每一项都是数值,sort()方法比较的也是字符串
1 | [0, 1, 5, 10, 15].sort() // [0, 1, 10, 15, 5] |
操作方法
concat()方法可以基于当前数组中的所有项创建一个新数组,具体来说,这个方法会先创建当前数组一个副本,然后将接收到的参数添加到这个副本的末尾,最后返回新构建的数组。
slice():它能够基于当前数组中的一或多个项创建一个新数组。slice()方法可以接受一或两个参数,即要返回项的起始和结束位置。在只有一个参数的情况下,slice()方法返回从该参数指定位置开始到当前数组末尾的所有项。如果有两个参数,该方法返回起始和结束位置之间的项——但不包括结束位置的项。注意,slice()方法不会影响原始数组。
1 | let color = [1, 2, 3]; |
splice():这个方法恐怕要算是最强大的数组方法了,它有很多种用法。splice()的主要用途是向数组的中部插入项。splice()方法始终都会返回一个数组,该数组中包含从原始数组中删除的项(如果没有删除任何项,则返回一个空数组), 且会改变原数组
- 删除:可以删除任意数量的项,只需指定2个参数:要删除的第一项的位置和要删除的项数。例如,splice(0,2)会删除数组中的前两项。
- 插入:可以向指定位置插入任意数量的项,只需提供3个参数:起始位置、0(要删除的项数)和要插入的项。如果要插入多个项,可以再传入第四、第五,以至任意多个项。例如,splice(2,0, “red”, “green”)会从当前数组的位置2开始插入字符串”red”和”green”
- 替换:可以向指定位置插入任意数量的项,且同时删除任意数量的项,只需指定3个参数:起始位置、要删除的项数和要插入的任意数量的项。插入的项数不必与删除的项数相等。例如,splice (2,1, “red”, “green”)会删除当前数组位置2的项,然后再从位置2开始插入字符串”red”和”green”
1 | // 删除 |
迭代方法
- every():对数组中的每一项运行给定函数,如果该函数对每一项都返回true,则返回true。
- some(): 对数组中的每一项运行给定函数,如果该函数对任一项返回true,则返回true。
- filter():对数组中的每一项运行给定函数,返回该函数会返回true的项组成的数组。
- forEach():对数组中的每一项运行给定函数。这个方法没有返回值
- map():对数组中的每一项运行给定函数,返回每次函数调用的结果组成的数组。
1 | // filter |
归并方法
reduce()和reduceRight()。这两个方法都会迭代数组的所有项,然后构建一个最终返回的值。
1 | // 数组之和 |
3、Date类型
ECMAScript中的Date类型是在早期Java中的java.util.Date类基础上构建的。为此,Date类型使用自UTC(Coordinated Universal Time,国际协调时间)1970年1月1日午夜(零时)开始经过的毫秒数来保存日期。在使用这种数据存储格式的条件下,Date类型保存的日期能够精确到1970年1月1日之前或之后的100000000年。
3.1 Date.now()
ECMAScript 5添加了Date.now()方法,返回表示调用这个方法时的日期和时间的毫秒数。
1 | //取得开始时间 |
支持Date.now()方法的浏览器包括IE9+、Firefox 3+、Safari 3+、Opera 10.5和Chrome。在不支持它的浏览器中,使用+操作符获取Date对象的时间戳,也可以达到同样的目的。
1 | //取得开始时间 |
3.2 继承
与其他引用类型一样,Date类型也重写了**toLocaleString()、toString()和valueOf()**方法;但这些方法返回的值与其他类型中的方法不同。Date类型的toLocaleString()方法会按照与浏览器设置的地区相适应的格式返回日期和时间。这大致意味着时间格式中会包含AM或PM,但不会包含时区信息(当然,具体的格式会因浏览器而异)。而toString()方法则通常返回带有时区信息的日期和时间,其中时间一般以军用时间(即小时的范围是0到23)表示。下面给出了在不同浏览器中调用toLocaleString()和toString()方法,输出PST(Pacific Standard Time,太平洋标准时间)时间2007年2月1日午夜零时的结果。
4、RegExp类型
4.1 RegExp类型
1 | let expression = /pattern/flags; |
其中的模式(pattern)部分可以是任何简单或复杂的正则表达式,可以包含字符类、限定符、分组、向前查找以及反向引用。每个正则表达式都可带有一或多个标志(flags),用以标明正则表达式的行为。正则表达式的匹配模式支持下列3个标志。
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止;
i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写;
m:表示多行(multiline)模式,即在到达一行文本末尾时还会继续查找下一行中是否存在与模式匹配的项。
与其他语言中的正则表达式类似,模式中使用的所有元字符都必须转义。正则表达式中的元字符包括:
1 | ( [ { \ ^ $ | ) ? * + . ] } |
4.2 RegExp实例属性
global:布尔值,表示是否设置了g标志。
ignoreCase:布尔值,表示是否设置了i标志。
lastIndex:整数,表示开始搜索下一个匹配项的字符位置,从0算起。
multiline:布尔值,表示是否设置了m标志。
source:正则表达式的字符串表示,按照字面量形式而非传入构造函数中的字符串模式返回。
1 | let pattern1 = /\[bc\]at/i |
4.3 RegExp实例方法
exec()
1 | // 待补充 |
test()
1 | let text = "000-00-0000"; |
5、Function类型
函数实际上是对象。每个函数都是Function类型的实例,而且都与其他引用类型一样具有属性和方法。由于函数是对象,因此函数名实际上也是一个指向函数对象的指针,不会与某个函数绑定。
1 | // 创建函数方法一 |
5.1 没有重载
这个例子中声明了两个同名函数,而结果则是后面的函数覆盖了前面的函数。在创建第二个函数时,实际上覆盖了引用第一个函数的变量addSomeNumber。
1 | function addSomeNumber(num){ |
5.2 函数声明和函数表达式
解析器在向执行环境中加载数据时,对函数声明和函数表达式并非一视同仁。解析器会率先读取函数声明,并使其在执行任何代码之前可用(可以访问);至于函数表达式,则必须等到解析器执行到它所在的代码行,才会真正被解释执行。
1 | /** |
1 | /** |
5.3 作为值的函数
5.4 函数内部属性
在函数内部,有两个特殊的对象:arguments和this。其中,arguments在第3章曾经介绍过,它是一个类数组对象,包含着传入函数中的所有参数。虽然arguments的主要用途是保存函数参数,但这个对象还有一个名叫callee的属性,该属性是一个指针,指向拥有这个arguments对象的函数。请看下面这个非常经典的阶乘函数。
1 | function factorial(num){ |
this的指向:由于在调用函数之前,this的值并不确定,因此this可能会在代码执行过程中引用不同的对象。
1 | window.color = 'red'; |
5.5 函数的属性和方法
ECMAScript中的函数是对象,因此函数也有属性和方法。每个函数都包含两个属性:length和prototype。其中,length属性表示函数希望接收的命名参数的个数。
在ECMAScript核心所定义的全部属性中,最耐人寻味的就要数prototype属性了。对于ECMAScript中的引用类型而言,prototype是保存它们所有实例方法的真正所在。换句话说,诸如toString()和valueOf()等方法实际上都保存在prototype名下,只不过是通过各自对象的实例访问罢了。在创建自定义引用类型以及实现继承时,prototype属性的作用是极为重要的(第6章将详细介绍)。在ECMAScript 5中,prototype属性是不可枚举的,因此使用for-in无法发现。
5.1.1 call 和 apply
每个函数都包含两个非继承而来的方法:apply()和call()。这两个方法的用途都是在特定的作用域中调用函数,实际上等于设置函数体内this对象的值。
1 | // apply |
5.1.2 bind
ECMAScript 5还定义了一个方法:bind()。这个方法会创建一个函数的实例,其this值会被绑定到传给bind()函数的值。
1 | window.color = 'red'; |
6、基本包装类型
为了便于操作基本类型值,ECMAScript还提供了3个特殊的引用类型:Boolean、Number和String。这些类型与本章介绍的其他引用类型相似,但同时也具有与各自的基本类型相应的特殊行为。实际上,每当读取一个基本类型值的时候,后台就会创建一个对应的基本包装类型的对象,从而让我们能够调用一些方法来操作这些数据。
1 | let s1 = 'some text'; |
我们知道,基本类型值不是对象,因而从逻辑上讲它们不应该有方法(尽管如我们所愿,它们确实有方法)。
其实,为了让我们实现这种直观的操作,后台已经自动完成了一系列的处理。当第二行代码访问s1时,访问过程处于一种读取模式,也就是要从内存中读取这个字符串的值。而在读取模式中访问字符串时,后台都会自动完成下列处理:
(1) 创建String类型的一个实例;
(2) 在实例上调用指定的方法;
(3) 销毁这个实例。
1 | var s1=new String("some text"); |
引用类型与基本包装类型的主要区别就是对象的生存期。使用new操作符创建的引用类型的实例,在执行流离开当前作用域之前都一直保存在内存中。而自动创建的基本包装类型的对象,则只存在于一行代码的执行瞬间,然后立即被销毁。这意味着我们不能在运行时为基本类型值添加属性和方法。
1 | var s1="some text"; |
Object构造函数也会像工厂方法一样,根据传入值的类型返回相应基本包装类型的实例。
1 | var obj=new Object("some text"); |
使用new调用基本包装类型的构造函数,与直接调用同名的转型函数是不一样的。
在下面例子中,变量number中保存的是基本类型的值25,而变量obj中保存的是Number的实例。
1 | var value="25"; |
6.1 Boolean类型
6.2 Number类型
具体来讲,就是在使用typeof和instanceof操作符测试基本类型数值与引用类型数值时,得到的结果完全不同。
1 | var numberObject=new Number(10); |
6.3 String类型
7、单体内置对象
由ECMAScript实现提供的、不依赖于宿主环境的对象,这些对象在ECMAScript程序执行之前就已经存在了。
意思就是说,开发人员不必显式地实例化内置对象,因为它们已经实例化了。前面我们已经介绍了大多数内置对象,例如Object、Array和String。ECMA-262还定义了两个单体内置对象:Global和Math。
7.1 Global对象
所有在全局作用域中定义的属性和函数,都是Global对象的属性。本书前面介绍过的那些函数,诸如isNaN()、isFinite()、parseInt()以及parseFloat(),实际上全都是Global对象的方法。除此之外,Global对象还包含其他一些方法:
- URI编码方法:encodeURI()和encodeURIComponent()
encodeURI()不会对本身属于URI的特殊字符进行编码,例如冒号、正斜杠、问号和井字号;而encodeURIComponent()则会对它发现的任何非标准字符进行编码。
一般来说,我们使用encodeURIComponent()方法的时候要比使用encodeURI()更多,因为在实践中更常见的是对查询字符串参数而不是对基础URI进行编码。
eval()方法
Global对象的属性
window对象
ECMAScript虽然没有指出如何直接访问Global对象,但Web浏览器都是将这个全局对象作为window对象的一部分加以实现的。因此,在全局作用域中声明的所有变量和函数,就都成为了window对象的属性
JavaScript中的window对象除了扮演ECMAScript规定的Global对象的角色外,还承担了很多别的任务。第8章在讨论浏览器对象模型时将详细介绍window对象.
7.2 Math对象
- min()和max()方法
1 | var values=[1, 2, 3, 4, 5, 6, 7, 8]; |
- Math.ceil()执行向上舍入
- Math.floor()执行向下舍入
- Math.round()执行标准舍入
8、总结
Object是一个基础类型,其他所有类型都从Object继承了基本的行为
函数实际上是Function类型的实例,因此函数也是对象;而这一点正是JavaScript最有特色的地方。由于函数是对象,所以函数也拥有方法,可以用来增强其行为。
在所有代码执行之前,作用域中就已经存在两个内置对象:Global和Math。在大多数ECMAScript实现中都不能直接访问Global对象;不过,Web浏览器实现了承担该角色的window对象。
四、面向对象程序设计(重要知识点)
1、理解对象
早期的JavaScript开发人员经常使用这个模式创建新对象。几年后,对象字面量成为创建这种对象的首选模式。
1 | let person = new Object(); |
1.1 属性类型
- 数据属性
要修改属性默认的特性,必须使用ECMAScript 5的Object.defineProperty()方法。这个方法接收三个参数:属性所在的对象、属性的名字和一个描述符对象。
1 | let person = {}; |
- 访问器属性
访问器属性不包含数据值;它们包含一对儿getter和setter函数(不过,这两个函数都不是必需的)。在读取访问器属性时,会调用getter函数,这个函数负责返回有效的值;在写入访问器属性时,会调用setter函数并传入新值,这个函数负责决定如何处理数据。
不一定非要同时指定getter和setter。只指定getter意味着属性是不能写,尝试写入属性会被忽略。在严格模式下,尝试写入只指定了getter函数的属性会抛出错误。类似地,只指定setter函数的属性也不能读,否则在非严格模式下会返回undefined,而在严格模式下会抛出错误。
1.2 Object.definePropert
1 | let person = { |
1.3 Object.getOwnPropertyDescriptor
这个方法接收两个参数:属性所在的对象和要读取其描述符的属性名称。返回值是一个对象,如果是访问器属性,这个对象的属性有configurable、enumerable、get和set;如果是数据属性,这个对象的属性有configurable、enumerable、writable和value。
2、创建对象
虽然Object构造函数或对象字面量都可以用来创建单个对象,**但这些方式有个明显的缺点:使用同一个接口创建很多对象,会产生大量的重复代码。**为解决这个问题,人们开始使用工厂模式的一种变体。
2.1 工厂模式
1 | function createPerson(name, age, job){ |
可以无数次地调用这个函数,而每次它都会返回一个包含三个属性一个方法的对象。工厂模式虽然解决了创建多个相似对象的问题,但却没有解决对象识别的问题(即怎样知道一个对象的类型)
2.2 构造函数模式
1 | // 按照惯例,构造函数始终都应该以一个大写字母开头 |
2.2.1 构造函数模式和工厂模式区别
- 没显示地创建对象
- 直接将属性和方法赋给this对象
- 没有return语句
创建Person新实例,必须使用new操作符。调用构造函数会经历一下4个步骤:
- 创建一个新对象
- 将构造函数的作用域赋给新对象(因此this就指向了这个新对象)
- 执行构造函数的代码(为这个新对象添加属性)
- 返回新对象
2.2.2 constructor
1 | // p1和p2分别保存着Person的一个不同的实例。这两个对象都有一个constructor(构造函数)属性,该属性指向Person |
2.2.3 instanceof
1 | alert(p1 instanceof Object); //true |
创建自定义的构造函数意味着将来可以将它的实例标识为一种特定的类型;而这正是构造函数模式胜过工厂模式的地方。在这个例子中,p1和p2之所以同时是Object的实例,是因为所有对象均继承自Object。
2.2.4 将构造函数当作函数
构造函数与其他函数的唯一区别,就在于调用它们的方式不同。不过,构造函数毕竟也是函数,不存在定义构造函数的特殊语法。任何函数,只要通过new操作符来调用,那它就可以作为构造函数;而任何函数,如果不通过new操作符来调用,那它跟普通函数也不会有什么两样。
1 | // 当做构造函数使用 |
2.2.5 构造函数的问题
- 每个方法都要在每个实例上重新创建一遍。在前面的例子中,p1和p2都有一个名为sayName()方法。
1 | function Person(name, age, job){ |
1 | function Person(name, age, job){ |
2.3 原型模式
我们创建的每个函数都有一个prototype(原型)属性,这个属性是一个指针,指向一个对象,而这个对象的用途是包含可以由特定类型的所有实例共享的属性和方法。使用原型对象的好处是可以让所有对象实例共享它所包含的属性和方法。
1 | function Person() { |
2.3.1 理解原型对象
在默认情况下,所有原型对象都会自动获得一个constructor(构造函数)属性,这个属性是一个指向prototype属性所在函数的指针。就拿前面的例子来说,Person.prototype.constructor指向Person。而通过这个构造函数,我们还可继续为原型对象添加其他属性和方法。
使用hasOwnProperty()方法可以检测一个属性是存在于实例中,还是存在于原型中。
1 | function Person() { |
2.3.2 原型与in操作符
有两种方式使用in操作符:单独使用和在for-in循环中使用。在单独使用时,in操作符会在通过对象能够访问给定属性时返回true,无论该属性存在于实例中还是原型中。
1 | // 判断属性是否在原型中 |
要取得对象上所有可枚举的实例属性,可以使用ECMAScript 5的Object.keys()方法。
1 | function Person() { |
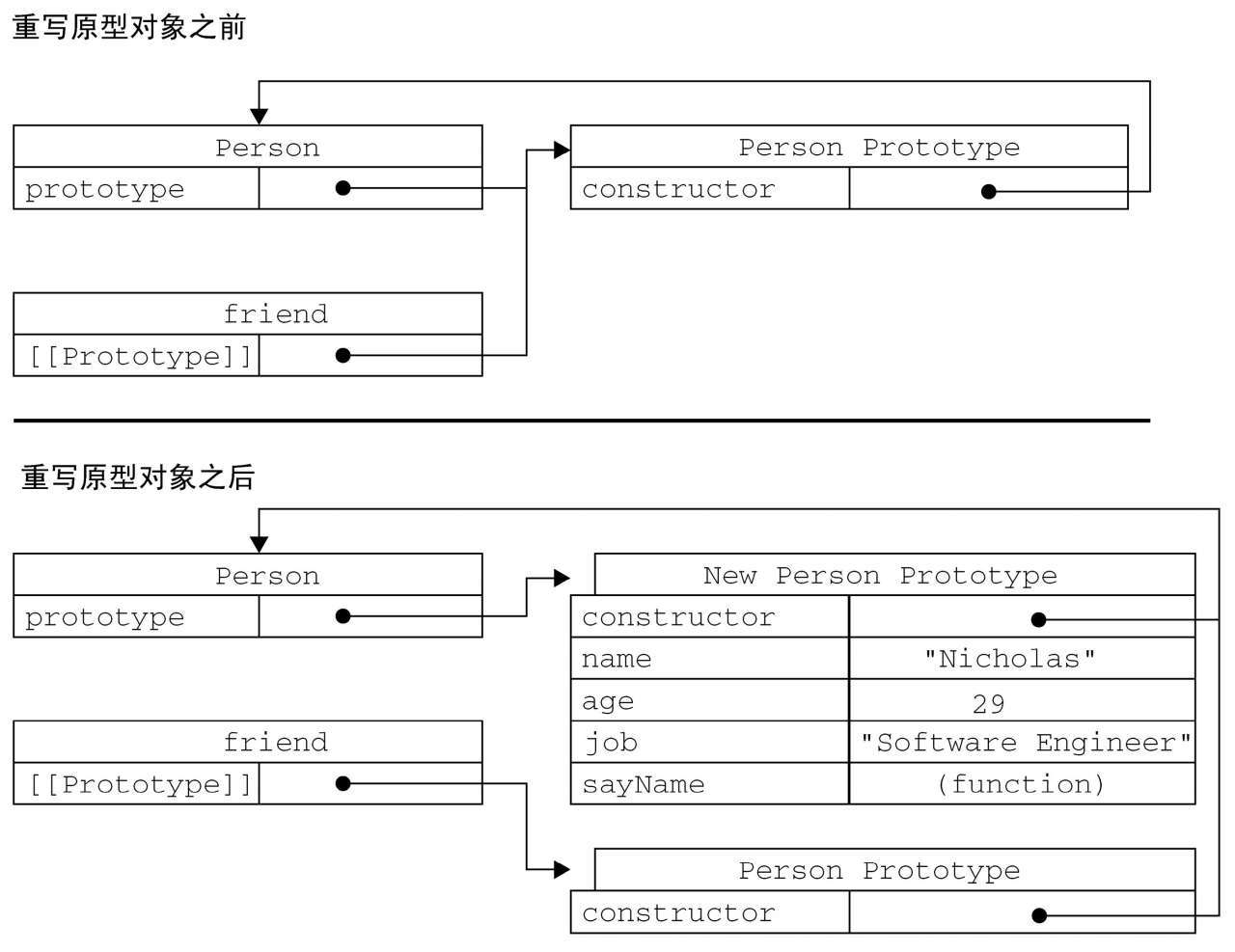
2.3.3 更简单的原型语法
constructor属性不再指向Person了。前面曾经介绍过,每创建一个函数,就会同时创建它的prototype对象,这个对象也会自动获得constructor属性。而我们在这里使用的语法,本质上完全重写了默认的prototype对象,因此constructor属性也就变成了新对象的constructor属性(指向Object构造函数),不再指向Person函数。 此时,尽管instanceof操作符还能返回正确的结果,但通过constructor已经无法确定对象的类型了。
1 | function Person(name, age, job){ |
以这种方式重设constructor属性会导致它的[[Enumerable]]特性被设置为true。默认情况下,原生的constructor属性是不可枚举的,因此如果你使用兼容ECMAScript 5的JavaScript引擎,可以试一试Object.defineProperty()。
1 | //重设构造函数,只适用于ECMAScript 5兼容的浏览器 |
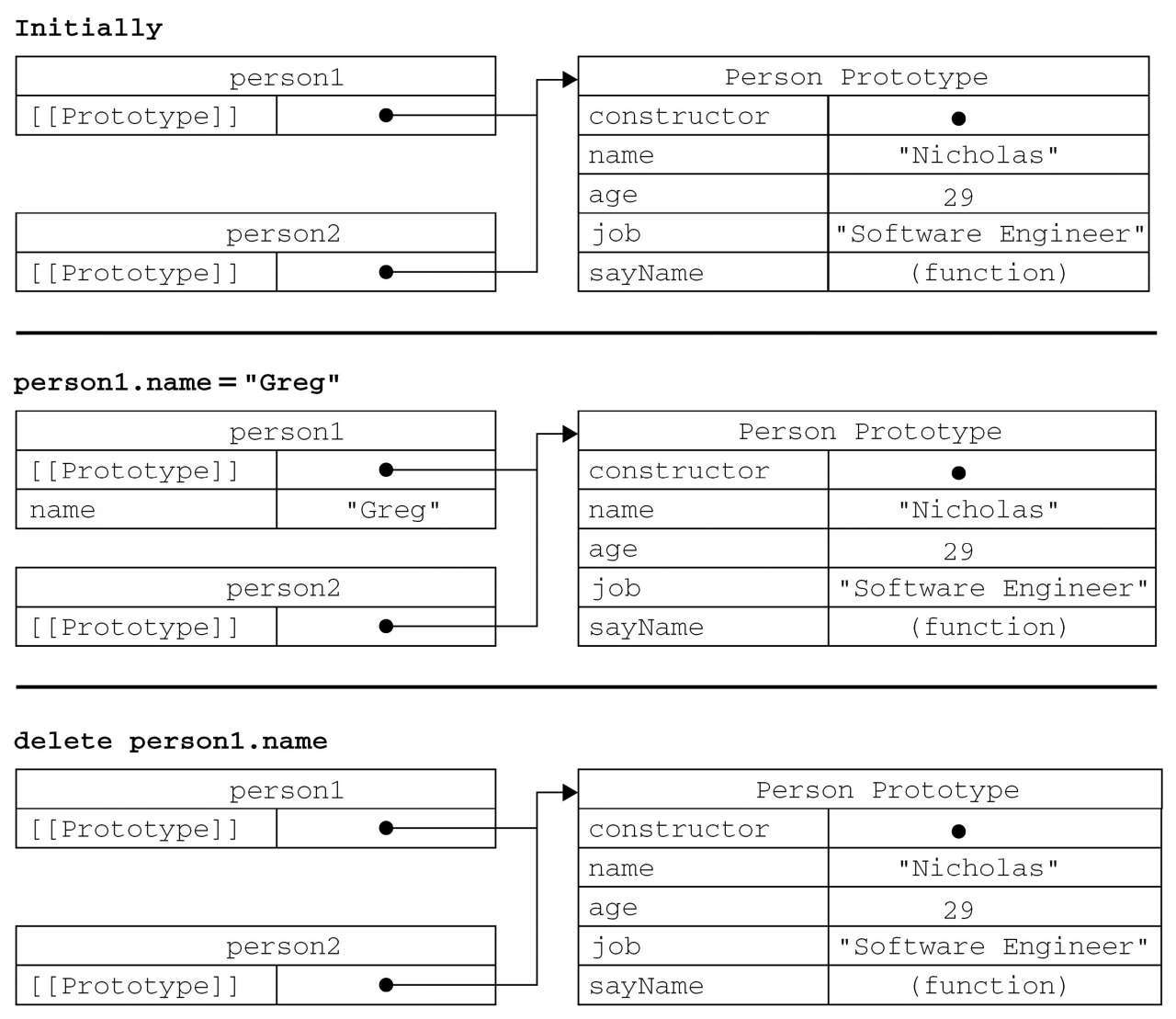
2.3.4 原型的动态性
由于在原型中查找值的过程是一次搜索,因此我们对原型对象所做的任何修改都能够立即从实例上反映出来——即使是先创建了实例后修改原型也照样如此。
原因可以归结为实例与原型之间的松散连接关系。当我们调用p1.say()时,首先会在实例中搜索名为say的属性,在没找到的情况下,会继续搜索原型。因为实例与原型之间的连接只不过是一个指针,而非一个副本,因此就可以在原型中找到新的say属性并返回保存在那里的函数。
1 | function Person(){} |
如果重写原型对象呢?
1 | function Person(){ |
调用构造函数时会为实例添加一个指向最初原型的[[Prototype]]指针,而把原型修改为另外一个对象就等于切断了构造函数与最初原型之间的联系。请记住:实例中的指针仅指向原型,而不指向构造函数。
从上图可见,重写原型对象切断了现有原型与任何之前已经存在的对象实例之间的联系;它们引用的仍然是最初的原型。
2.3.5 原生对象的原型
原型模式的重要性不仅体现在创建自定义类型方面,就连所有原生的引用类型,都是采用这种模式创建的。所有原生引用类型(Object、Array、String,等等)都在其构造函数的原型上定义了方法。例如,在Array.prototype中可以找到sort()方法,而在String.prototype中可以找到substring()方法。
通过原生对象的原型,不仅可以取得所有默认方法的引用,而且也可以定义新方法。可以像修改自定义对象的原型一样修改原生对象的原型,因此可以随时添加方法。
尽管可以这样做,但我们不推荐在产品化的程序中修改原生对象的原型。如果因某个实现中缺少某个方法,就在原生对象的原型中添加这个方法,那么当在另一个支持该方法的实现中运行代码时,就可能会导致命名冲突。而且,这样做也可能会意外地重写原生方法。
2.3.6 原型对象的问题
原型模式的最大问题是由其共享的本性所导致的。
原型中所有属性是被很多实例共享的,这种共享对于函数非常合适。对于那些包含基本值的属性倒也说得过去,毕竟(如前面的例子所示),通过在实例上添加一个同名属性,可以隐藏原型中的对应属性。然而,对于包含引用类型值的属性来说,问题就比较突出了。
1 | function Person(){ |
由于friends数组存在于Person.prototype而非p1中,所以刚刚提到的修改也会通过p2.friends(与p1.friends指向同一个数组)反映出来。
3、继承
许多OO语言都支持两种继承方式:接口继承和实现继承。接口继承只继承方法签名,而实现继承则继承实际的方法。如前所述,由于函数没有签名,在ECMAScript中无法实现接口继承。ECMAScript只支持实现继承,而且其实现继承主要是依靠原型链来实现的。
3.1 原型链继承
ECMAScript中描述了原型链的概念,并将原型链作为实现继承的主要方法。其基本思想是利用原型让一个引用类型继承另一个引用类型的属性和方法。
构造函数、原型、实例的关系:每个构造函数都有一个原型对象,原型对象都包含一个指向构造函数的指针,而实例都包含一个指向原型对象的内部指针
1 | // 原型链继承模型如下: |
**原型链继承实现的本质是重写原型对象,代之以一个新类型的实例。**换句话说,原来存在于SuperType的实例中的所有属性和方法,现在也存在于SubType.prototype中了。
原型链继承实现的本质是重写原型对象,代之以一个新类型的实例。换句话说,原来存在于SuperType的实例中的所有属性和方法,现在也存在于SubType.prototype中了。
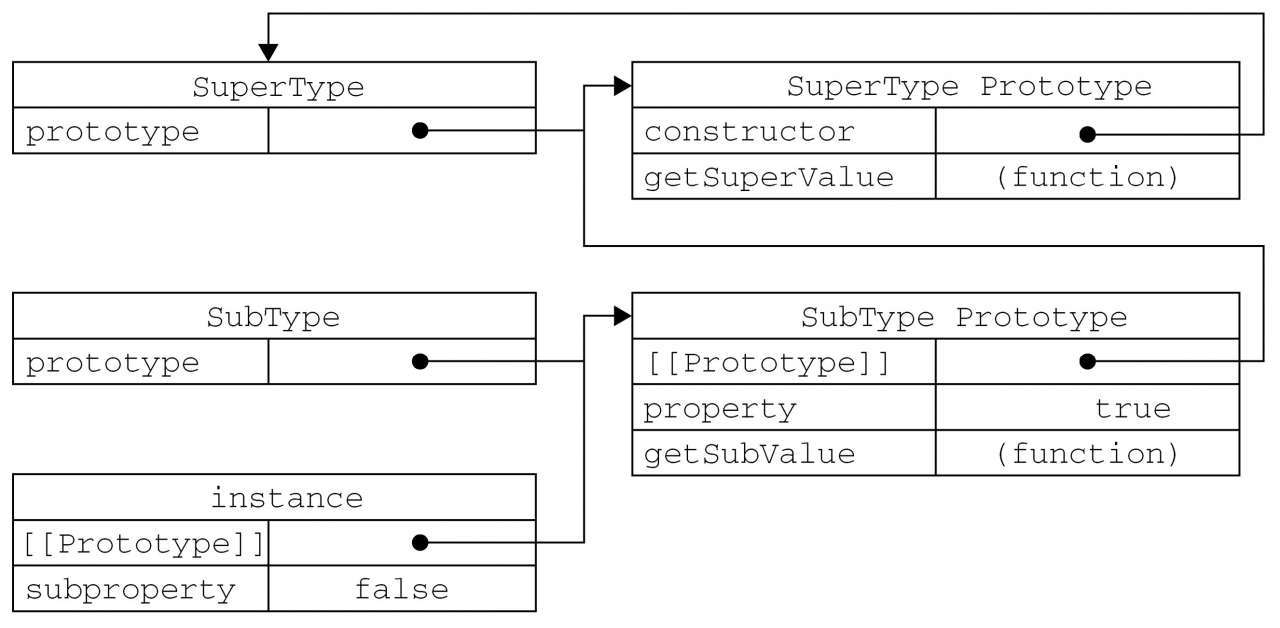
调用instance.getSuperValue()会经历三个搜索步骤:1)搜索实例;2)搜索SubType.prototype;3)搜索SuperType.prototype,最后一步才会找到该方法。在找不到属性或方法的情况下,搜索过程总是要一环一环地前行到原型链末端才会停下来。
3.1.1 对象默认的原型
我们知道,所有引用类型默认都继承了Object,而这个继承也是通过原型链实现的。
所有函数的默认原型都是Object的实例,因此默认原型都会包含一个内部指针,指向Object.prototype。这也正是所有自定义类型都会继承toString()、valueOf()等默认方法的根本原因。
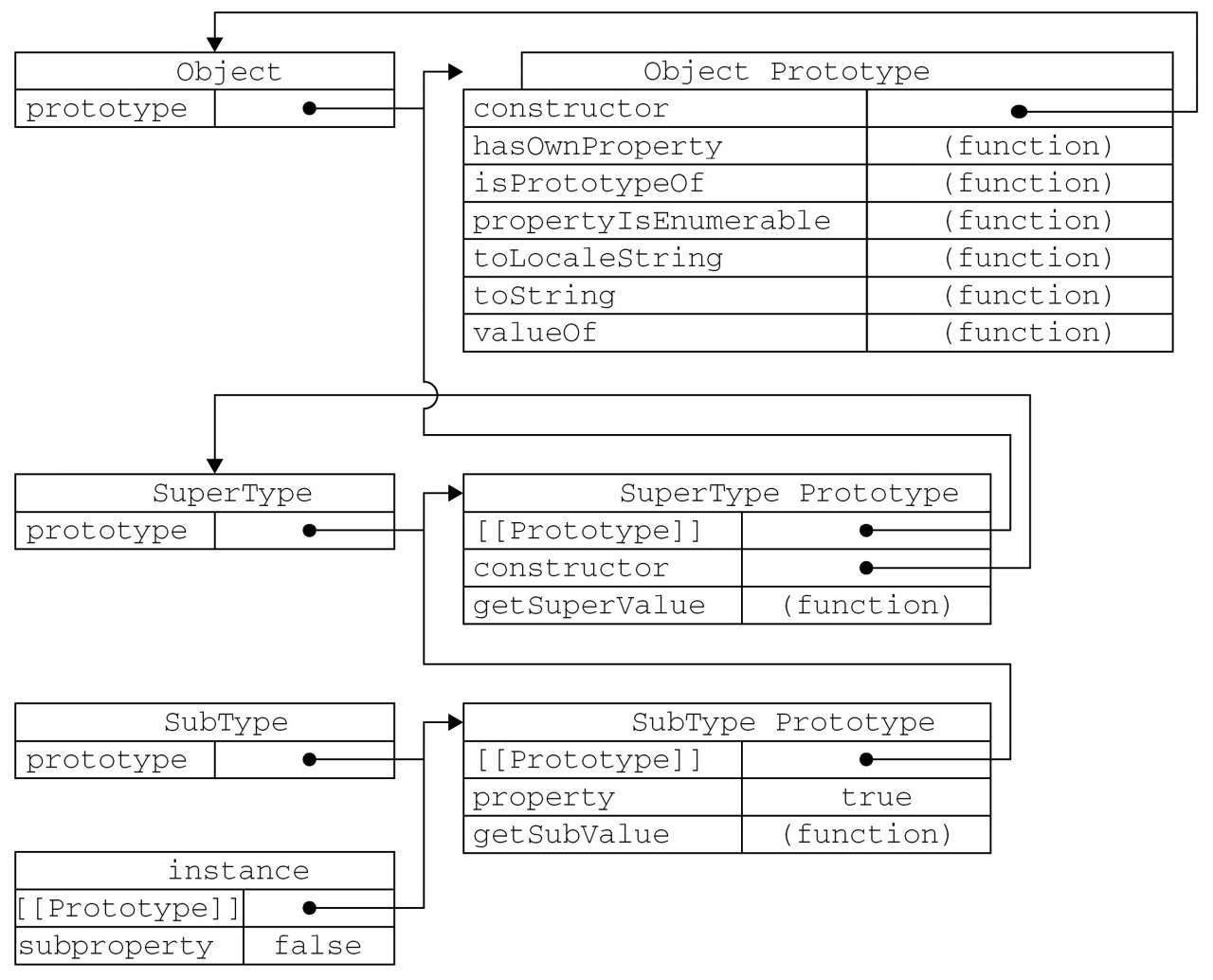
SubType继承了SuperType,而SuperType继承了Object。当调用instance.toString()时,实际上调用的是保存在Object.prototype中的那个方法
3.1.2 原型和实例的关系
1 | // 1、instanceof |
3.1.3 谨慎地定义方法
1 | // 1、覆盖父类的方法和属性 |
以上代码展示了刚刚把SuperType的实例赋值给原型,紧接着又将原型替换成一个对象字面量而导致的问题。由于现在的原型包含的是一个Object的实例,而非SuperType的实例,因此我们设想中的原型链已经被切断——SubType和SuperType之间已经没有关系了。
3.1.4 原型链的问题
问题一:原型中包含引用类型值(数组)的原型属性会被所有实例共享。想必大家还记得,我们前面介绍过包含引用类型值的原型属性会被所有实例共享;而这也正是为什么要在构造函数中,而不是在原型对象中定义属性的原因。在通过原型来实现继承时,原型实际上会变成另一个类型的实例。于是,原先的实例属性也就顺理成章地变成了现在的原型属性了。 (这里需要仔细思考下)
问题二:在创建子类型的实例时,不能向超类型的构造函数中传递参数。实际上,应该说是没有办法在不影响所有对象实例的情况下,给超类型的构造函数传递参数。
1 | function SuperType(){ |
3.2 借用构造函数继承(call/apply)
在解决原型中包含引用类型值所带来问题的过程中,开发人员开始使用一种叫做借用构造函数的技术(有时候也叫做伪造对象或经典继承)。这种技术的基本思想相当简单,即在子类型构造函数的内部调用超类型构造函数。
1 | function SuperType(){ |
我们实际上是在(未来将要)新创建的SubType实例的环境下调用了SuperType构造函数。这样一来,就会在新SubType对象上执行SuperType()函数中定义的所有对象初始化代码。结果,SubType的每个实例就都会具有自己的colors属性的副本了。
3.2.1 好处(相对于原型支持传参)
1 | function SuperType(colors){ |
3.2.2 问题
如果仅仅是借用构造函数,那么也将无法避免构造函数模式存在的问题——方法都在构造函数中定义,因此函数复用就无从谈起了。而且,在超类型的原型中定义的方法,对子类型而言也是不可见的,结果所有类型都只能使用构造函数模式
3.3 组合继承 (最常见)
组合继承,有时候也叫做伪经典继承,指的是将原型链和借用构造函数的技术组合到一块,从而发挥二者之长的一种继承模式。其背后的思路是使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又能够保证每个实例都有它自己的属性。
1 | function SuperType(name, colors){ |
组合继承避免了原型链和借用构造函数的缺陷,融合了它们的优点,成为JavaScript中最常用的继承模式。而且,instanceof和isPrototypeOf()也能够用于识别基于组合继承创建的对象。
3.4 原型式继承(es6实现Object.create())
1 | function myObject(o){ |
在没有必要兴师动众地创建构造函数,而只想让一个对象与另一个对象保持类似的情况下,原型式继承是完全可以胜任的。不过别忘了,包含引用类型值的属性始终都会共享相应的值,就像使用原型模式一样。
3.5 寄生式继承
待补充…
3.6 寄生组合继承
前面说过,组合继承是JavaScript最常用的继承模式;不过,它也有自己的不足。组合继承最大的问题就是无论什么情况下,都会调用两次超类型构造函数:一次是在创建子类型原型的时候,另一次是在子类型构造函数内部。没错,子类型最终会包含超类型对象的全部实例属性,但我们不得不在调用子类型构造函数时重写这些属性。
1 | function SuperType(name){ |
寄生组合继承:
1 | function inheritPrototype(subType, superType){ |
这个例子的高效率体现在它只调用了一次SuperType构造函数,并且因此避免了在SubType.prototype上面创建不必要的、多余的属性。与此同时,原型链还能保持不变;因此,还能够正常使用instanceof和isPrototypeOf()。开发人员普遍认为寄生组合式继承是引用类型最理想的继承范式。
4、总结
ECMAScript支持面向对象(OO)编程,但不使用类或者接口。对象可以在代码执行过程中创建和增强,因此具有动态性而非严格定义的实体。
- 工厂模式,使用简单的函数创建对象,为对象添加属性和方法,然后返回对象。这个模式后来被构造函数模式所取代。
- 构造函数模式,可以创建自定义引用类型,可以像创建内置对象实例一样使用new操作符。不过,构造函数模式也有缺点,即它的每个成员都无法得到复用,包括函数。由于函数可以不局限于任何对象(即与对象具有松散耦合的特点),因此没有理由不在多个对象间共享函数。
- 原型模式,使用构造函数的prototype属性来指定那些应该共享的属性和方法。组合使用构造函数模式和原型模式时,使用构造函数定义实例属性,而使用原型定义共享的属性和方法。
JavaScript主要通过原型链实现继承。原型链的构建是通过将一个类型的实例赋值给另一个构造函数的原型实现的。这样,子类型就能够访问超类型的所有属性和方法,这一点与基于类的继承很相似。
原型链的问题是对象实例共享所有继承的属性和方法,因此不适宜单独使用。解决这个问题的技术是借用构造函数,即在子类型构造函数的内部调用超类型构造函数。这样就可以做到每个实例都具有自己的属性,同时还能保证只使用构造函数模式来定义类型。
五、函数表达式
1、函数创建
定义函数的方式有两种:一种是函数声明,另一种就是函数表达式。
**关于函数声明,它的一个重要特征就是函数声明提升(function declaration hoisting),意思是在执行代码之前会先读取函数声明。**这就意味着可以把函数声明放在调用它的语句后面。
理解函数提升的关键,就是理解函数声明与函数表达式之间的区别。
1 | // 1、函数声明 |
2、递归
arguments.callee是一个指向正在执行的函数的指针
1 | function factorial(num){ |
但在严格模式下,不能通过脚本访问arguments.callee,访问这个属性会导致错误。
1 | var factorial=(function f(num){ |
3、闭包
有不少开发人员总是搞不清匿名函数和闭包这两个概念,因此经常混用。闭包是指有权访问另一个函数作用域中的变量的函数。创建闭包的常见方式,就是在一个函数内部创建另一个函数。
当createComparisonFunction()函数返回后,其执行环境的作用域链会被销毁,但它的活动对象仍然会留在内存中;直到匿名函数被销毁后,createComparisonFunction()的活动对象才会被销毁。 如下:
1 | function createComparisonFunction(propertyName) { |
由于闭包会携带包含它的函数的作用域,因此会比其他函数占用更多的内存。过度使用闭包可能会导致内存占用过多
3.1 闭包与变量
作用域链的这种配置机制引出了一个值得注意的副作用,即闭包只能取得包含函数中任何变量的最后一个值
1 | function createFunctions(){ |
上面函数实际上,每个函数都返回10。因为每个函数的作用域链中都保存着createFunctions()函数的活动对象,所以它们引用的都是同一个变量i。当createFunctions()函数返回后,变量i的值是10,此时每个函数都引用着保存变量i的同一个变量对象,所以在每个函数内部i的值都是10
1 | function createFunctions(){ |
在这个版本中,我们没有直接把闭包赋值给数组,而是定义了一个匿名函数,并将立即执行该匿名函数的结果赋给数组。这里的匿名函数有一个参数num,也就是最终的函数要返回的值。在调用每个匿名函数时,我们传入了变量i。由于函数参数是按值传递的,所以就会将变量i的当前值复制给参数num。而在这个匿名函数内部,又创建并返回了一个访问num的闭包。这样一来,result数组中的每个函数都有自己num变量的一个副本,因此就可以返回各自不同的数值了
3.2 this对象
,this对象是在运行时基于函数的执行环境绑定的:在全局函数中,this等于window,而当函数被作为某个对象的方法调用时,this等于那个对象。不过,匿名函数的执行环境具有全局性,因此其this对象通常指向window(但call/apply指向其他对象)。但有时候由于编写闭包的方式不同,这一点可能不会那么明显。
1 | let name = 'this window'; |
3.3 内存泄露
如果闭包的作用域链中保存着一个HTML元素,那么就意味着该元素将无法被销毁。
1 | function assignHandler(){ |
以上代码创建了一个作为element元素事件处理程序的闭包,而这个闭包则又创建了一个循环引用。由于匿名函数保存了一个对assignHandler()的活动对象的引用,因此就会导致无法减少element的引用数。只要匿名函数存在,element的引用数至少也是1,因此它所占用的内存就永远不会被回收
1 | function assignHandler(){ |
把element.id的一个副本保存在一个变量中,并且在闭包中引用该变量消除了循环引用。但仅仅做到这一步,还是不能解决内存泄漏的问题。必须要记住:闭包会引用包含函数的整个活动对象,而其中包含着element。即使闭包不直接引用element,包含函数的活动对象中也仍然会保存一个引用。因此,有必要把element变量设置为null
4、模仿块级作用域
匿名函数可以用来模仿块级作用域并避免这个问题。
1 | /** |
1 | function(){ |
这段代码会导致语法错误,是因为JavaScript将function关键字当作一个函数声明的开始,**而函数声明后面不能跟圆括号。然而,函数表达式的后面可以跟圆括号。**要将函数声明转换成函数表达式,只要像下面这样给它加上一对圆括号即可。
5、私有变量
严格来讲,JavaScript中没有私有成员的概念;所有对象属性都是公有的。不过,倒是有一个私有变量的概念。任何在函数中定义的变量,都可以认为是私有变量,因为不能在函数的外部访问这些变量。私有变量包括函数的参数、局部变量和在函数内部定义的其他函数。
我们把有权访问私有变量和私有函数的公有方法称为特权方法(privileged method)
1 | function MyObject(){ |
5.1 静态私有变量
初始化未经声明的变量,总是会创建一个全局变量。因此,MyObject就成了一个全局变量,能够在私有作用域之外被访问到。但也要知道,在严格模式下给未经声明的变量赋值会导致错误。
1 | (function(){ |
5.2 模块模式
前面的模式是用于为自定义类型创建私有变量和特权方法的。而道格拉斯所说的模块模式(module pattern)则是为单例创建私有变量和特权方法。所谓单例(singleton),指的就是只有一个实例的对象。
由于这个对象是在匿名函数内部定义的,因此它的公有方法有权访问私有变量和函数。从本质上来讲,这个对象字面量定义的是单例的公共接口。这种模式在需要对单例进行某些初始化,同时又需要维护其私有变量时是非常有用的。
1 | var singleton=function(){ |
5.3 增强的模块模式
有人进一步改进了模块模式,即在返回对象之前加入对其增强的代码。这种增强的模块模式适合那些单例必须是某种类型的实例,同时还必须添加某些属性和(或)方法对其加以增强的情况。
1 | var singleton=function(){ |
6、总结
匿名函数,也称为拉姆达函数,是一种使用JavaScript函数的强大方式。 以下总结了函数表达式的特点:
- 函数表达式不同于函数声明。函数声明要求有名字,但函数表达式不需要。没有名字的函数表达式也叫做匿名函数。
- 递归函数应该始终使用arguments.callee来递归地调用自身,不要使用函数名——函数名可能会发生变化。
**当在函数内部定义了其他函数时,就创建了闭包。闭包有权访问包含函数内部的所有变量,**原理如下:
- 在后台执行环境中,闭包的作用域链包含着它自己的作用域、包含函数的作用域和全局作用域。
- 通常,函数的作用域及其所有变量都会在函数执行结束后被销毁。
- 但是,当函数返回了一个闭包时,这个函数的作用域将会一直在内存中保存到闭包不存在为止。
使用闭包可以在JavaScript中模仿块级作用域(JavaScript本身没有块级作用域的概念),要点如下:
- 创建并立即调用一个函数,这样既可以执行其中的代码,又不会在内存中留下对该函数的引用。
- 结果就是函数内部的所有变量都会被立即销毁——除非将某些变量赋值给了包含作用域(即外部作用域)中的变量。
因为创建闭包必须维护额外的作用域,所以过度使用它们可能会占用大量内存。
六、DOM
1、DOM节点和操作
1.1 节点类型
每个节点都有一个nodeType属性,用于表明节点的类型。
1 | if (someNode.nodeType==1){ //适用于所有浏览器 |
1.2 节点关系
每个节点都有一个childNodes属性,其中保存着一个NodeList对象。NodeList是一种类数组对象,用于保存一组有序的节点,可以通过位置来访问这些节点。
1 | var firstChild=someNode.childNodes[0]; |
我们在本书前面介绍过,对arguments对象使用Array.prototype.slice()方法可以将其转换为数组。而采用同样的方法,也可以将NodeList对象转换为数组。
1 | //在IE8及之前版本中无效 |
DOM节点关系图:
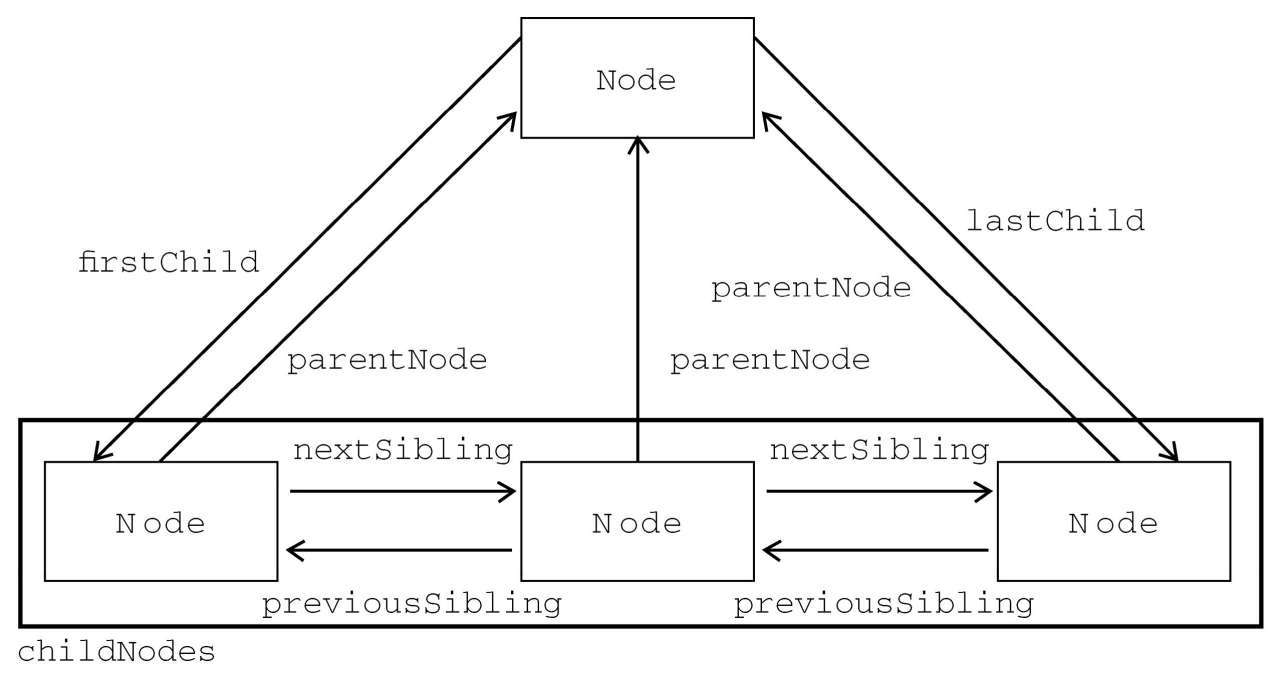
1 | if(someNode.nextSibling === null){ |
1.3 操作节点
如果传入到appendChild()中的节点已经是文档的一部分了,那结果就是将该节点从原来的位置转移到新位置。
1 | var returnedNode=someNode.appendChild(newNode); |
如果需要把节点放在childNodes列表中某个特定的位置上,而不是放在末尾,那么可以使用insertBefore()方法。这个方法接受两个参数:要插入的节点和作为参照的节点。
1 | //插入后成为最后一个子节点 |
appendChild()和insertBefore()方法都只插入节点,不会移除节点。而下面要介绍的**replaceChild()方法接受的两个参数是:要插入的节点和要替换的节点。**要替换的节点将由这个方法返回并从文档树中被移除,同时由要插入的节点占据其位置。
1 | //替换第一个子节点 |
如果只想移除而非替换节点,可以使用removeChild()方法。这个方法接受一个参数,即要移除的节点。
1 | //移除第一个子节点 |
1.4 其他方法
cloneNode()方法接受一个布尔值参数,表示是否执行深复制。在参数为true的情况下,执行深复制,也就是复制节点及其整个子节点树;在参数为false的情况下,执行浅复制,即只复制节点本身。
cloneNode()方法不会复制添加到DOM节点中的JavaScript属性,例如事件处理程序等。这个方法只复制特性、(在明确指定的情况下也复制)子节点,其他一切都不会复制。
1.5 Document类型
document对象还有一个body属性,直接指向body。
当页面中包含来自其他子域的框架或内嵌框架时,能够设置document.domain就非常方便了。由于跨域安全限制,来自不同子域的页面无法通过JavaScript通信。而通过将每个页面的document.domain设置为相同的值,这些页面就可以互相访问对方包含的JavaScript对象了。
1 | //假设页面来自p2p.wrox.com域 |
1.6 DOM操作技术
1 | // 动态加载js |
1.7 总结
DOM操作往往是JavaScript程序中开销最大的部分,而因访问NodeList导致的问题为最多。NodeList对象都是“动态的”,这就意味着每次访问NodeList对象,都会运行一次查询。有鉴于此,最好的办法就是尽量减少DOM操作。
2、DOM扩展
2.1 选择符
众多JavaScript库中最常用的一项功能,就是根据CSS选择符选择与某个模式匹配的DOM元素。实际上,jQuery的核心就是通过CSS选择符查询DOM文档取得元素的引用,从而抛开了getElementById()和getElementsByTagName()。
2.1.1 querySelector()方法
querySelector()方法接收一个CSS选择符,返回与该模式匹配的第一个元素,如果没有找到匹配的元素,返回null。
1 | // body元素 |
通过Document类型调用querySelector()方法时,会在文档元素的范围内查找匹配的元素。而通过Element类型调用querySelector()方法时,只会在该元素后代元素的范围内查找匹配的元素。如果传入了不被支持的选择符,querySelector()会抛出错误。
2.1.2 querySelectorAll()方法
querySelectorAll()方法接收的参数与querySelector()方法一样,都是一个CSS选择符,但返回的是所有匹配的元素而不仅仅是一个元素。这个方法返回的是一个NodeList的实例。
具体来说,返回的值实际上是带有所有属性和方法的NodeList,而其底层实现则类似于一组元素的快照,而非不断对文档进行搜索的动态查询。这样实现可以避免使用NodeList对象通常会引起的大多数性能问题。
1 | // 取得p元素中所有strong元素 |
2.2 遍历元素
对于元素间的空格,IE9及之前版本不会返回文本节点,而其他所有浏览器都会返回文本节点。这样,就导致了在使用childNodes和firstChild等属性时的行为不一致。
- childElementCount:返回子元素(不包括文本节点和注释)的个数
- firstElementChild:指向第一个子元素;firstChild的元素版。
- lastElementChild:指向最后一个子元素;lastChild的元素版
- previousElementSibling:指向前一个同辈元素;previousSibling的元素版
- nextElementSibling:指向后一个同辈元素;nextSibling的元素版。
利用这些元素不必担心空白文本节点,从而可以更方便地查找DOM元素。
1 | var i, |
使用元素版为:
1 | var i, |
2.3 HTML5
2.3.1 getElementsByClassName()方法
1 | //取得所有类中包含"username"和"current"的元素,类名的先后顺序无所谓 |
2.3.2 classList属性
在操作类名时,需要通过className属性添加、删除和替换类名。因为className中是一个字符串,所以即使只修改字符串一部分,也必须每次都设置整个字符串的值。
1 | // 删除 disable 类 |
2.3.3 焦点管理
HTML5也添加了辅助管理DOM焦点的功能。首先就是document.activeElement属性,这个属性始终会引用DOM中当前获得了焦点的元素。
另外就是新增了document.hasFocus()方法,这个方法用于确定文档是否获得了焦点。
1 | var button=document.getElementById("myButton"); |
2.3.4 HTMLDocument的变化
1、readyState属性
IE4最早为document对象引入了readyState属性。然后,其他浏览器也都陆续添加这个属性,最终HTML5把这个属性纳入了标准当中。Document的readyState属性有两个可能的值:
❏ loading,正在加载文档;
❏ complete,已经加载完文档。
2、自定义数据属性
HTML5规定可以为元素添加非标准的属性,但要添加前缀data-,目的是为元素提供与渲染无关的信息,或者提供语义信息。这些属性可以任意添加、随便命名,只要以data-开头即可。然后通过dataset来获取: div.dataset.myname
3、scrollIntoView()方法
scrollIntoView()可以在所有HTML元素上调用,通过滚动浏览器窗口或某个容器元素,调用元素就可以出现在视口中。
1 | //让元素可见 |
当页面发生变化时,一般会用这个方法来吸引用户的注意力。实际上,为某个元素设置焦点也会导致浏览器滚动并显示出获得焦点的元素。
2.3.5 专有扩展
1、innerText属性
设置innerText永远只会生成当前节点的一个子文本节点,而为了确保只生成一个子文本节点,就必须要对文本进行HTML编码。利用这一点,可以通过innerText属性过滤掉HTML标签。方法是将innerText设置为等于innerText,这样就可以去掉所有HTML标签: div.innerText = div.innerText
2、滚动
scrollIntoView()和scrollIntoViewIfNeeded()的作用对象是元素的容器,而scrollByLines()和scrollByPages()影响的则是元素自身。
1 | //将页面主体滚动5行 |
由于scrollIntoView()是唯一一个所有浏览器都支持的方法,因此还是这个方法最常用。
3、DOM2和DOM3
3.1 DOM变化
DOM2级核心”没有引入新类型,它只是在DOM1级的基础上通过增加新方法和新属性来增强了既有类型。
没啥特别要介绍的….
3.2 样式
3.2.1 计算的样式
虽然style对象能够提供支持style特性的任何元素的样式信息,但它不包含那些从其他样式表层叠而来并影响到当前元素的样式信息。“DOM2级样式”增强了document.defaultView,提供了getComputedStyle()方法。这个方法接受两个参数:要取得计算样式的元素和一个伪元素字符串(例如”:after”)。如果不需要伪元素信息,第二个参数可以是null。getComputedStyle()方法返回一个CSSStyleDeclaration对象(与style属性的类型相同)。
1 | let elem1 = document.getElementById("elemId"); |
3.2.2 元素大小
1、偏移量
- offsetHeight:元素在垂直方向上占用的空间大小,以像素计。包括元素的高度、(可见的)水平滚动条的高度、上边框高度和下边框高度。
- offsetWidth:元素在水平方向上占用的空间大小,以像素计。包括元素的宽度、(可见的)垂直滚动条的宽度、左边框宽度和右边框宽度。
- offsetLeft:元素的左外边框至包含元素的左内边框之间的像素距离。
- offsetTop:元素的上外边框至包含元素的上内边框之间的像素距离。
要想知道某个元素在页面上的偏移量,将这个元素的offsetLeft和offsetTop与其offsetParent的相同属性相加,如此循环直至根元素,就可以得到一个基本准确的值
1 | // 元素左边偏移量 |
这些偏移量属性都是只读的,而且每次访问它们都需要重新计算。因此,应该尽量避免重复访问这些属性;如果需要重复使用其中某些属性的值,可以将它们保存在局部变量中,以提高性能。
2、客户区大小
1 | function getViewport(){ |
3、滚动大小
- scrollHeight:在没有滚动条的情况下,元素内容的总高度。
- scrollWidth:在没有滚动条的情况下,元素内容的总宽度
- scrollLeft:被隐藏在内容区域左侧的像素数。通过设置这个属性可以改变元素的滚动位置。
- scrollTop:被隐藏在内容区域上方的像素数。通过设置这个属性可以改变元素的滚动位置。
scrollWidth和scrollHeight主要用于确定元素内容的实际大小。例如,通常认为<html>元素是在Web浏览器的视口中滚动的元素(IE6之前版本运行在混杂模式下时是<body>元素)。因此,带有垂直滚动条的页面总高度就是document.documentElement.scrollHeight。
3.3 遍历
- parentNode(): 遍历到当前节点的父节点;
- firstChild(): 遍历到当前节点的第一个子节点;
- lastChild()
- nextSibling()
- previousSibling()
3.4 范围
“DOM2级遍历和范围”模块定义了“范围”(range)接口。通过范围可以选择文档中的一个区域,而不必考虑节点的界限(选择在后台完成,对用户是不可见的)。
var range=document.createRange();
❏ startContainer:包含范围起点的节点(即选区中第一个节点的父节点)
❏ startOffset:范围在startContainer中起点的偏移量。如果startContainer是文本节点、注释节点或CDATA节点,那么startOffset就是范围起点之前跳过的字符数量。否则,startOffset就是范围中第一个子节点的索引。
❏ endContainer:包含范围终点的节点(即选区中最后一个节点的父节点)。
❏ endOffset:范围在endContainer中终点的偏移量(与startOffset遵循相同的取值规则)。
3.4.1 用DOM范围实现简单选择
要使用范围来选择文档中的一部分,最简的方式就是使用selectNode()或selectNodeContents()。这两个方法都接受一个参数,即一个DOM节点,然后使用该节点中的信息来填充范围。其中,selectNode()方法选择整个节点,包括其子节点;而selectNodeContents()方法则只选择节点的子节点。
1 | // html |
3.4.2 用DOM范围实现复杂选择
要创建复杂的范围就得使用setStart()和setEnd()方法。这两个方法都接受两个参数:一个参照节点和一个偏移量值。对setStart()来说,参照节点会变成startContainer,而偏移量值会变成startOffset。对于setEnd()来说,参照节点会变成endContainer,而偏移量值会变成endOffset。
可以使用这两个方法来模仿selectNode()和selectNodeContents()。来看下面的例子:
1 | let range1 = document.createRange(); |
3.4.3 操作DOM范围中的内容
在创建范围时,内部会为这个范围创建一个文档片段,范围所属的全部节点都被添加到了这个文档片段中。
1 | // html |
3.4.4 插入DOM范围中的内容
利用范围,可以删除或复制内容,还可以像前面介绍的那样操作范围中的内容。使用insertNode()方法可以向范围选区的开始处插入一个节点。
1 | // 假设我们想在前面例子中的HTML前面插入以下HTML代码: |
除了向范围内部插入内容之外,还可以环绕范围插入内容,此时就要使用surroundContents()方法。这个方法接受一个参数,即环绕范围内容的节点。在环绕范围插入内容时,后台会执行下列步骤:
- 提取出范围中的内容(类似执行extractContent())
- 将给定节点插入到文档中原来范围所在的位置上
- 将文档片段的内容添加到给定节点中
可以使用这种技术来突出显示网页中的某些词句,例如下列代码:
1 | let p1 = document.getElementById('p1'); |
3.4.5 折叠DOM范围
所谓折叠范围,就是指范围中未选择文档的任何部分。使用collapse()方法来折叠范围,这个方法接受一个参数,一个布尔值,表示要折叠到范围的哪一端。参数true表示折叠到范围的起点,参数false表示折叠到范围的终点。要确定范围已经折叠完毕,可以检查collapsed属性。
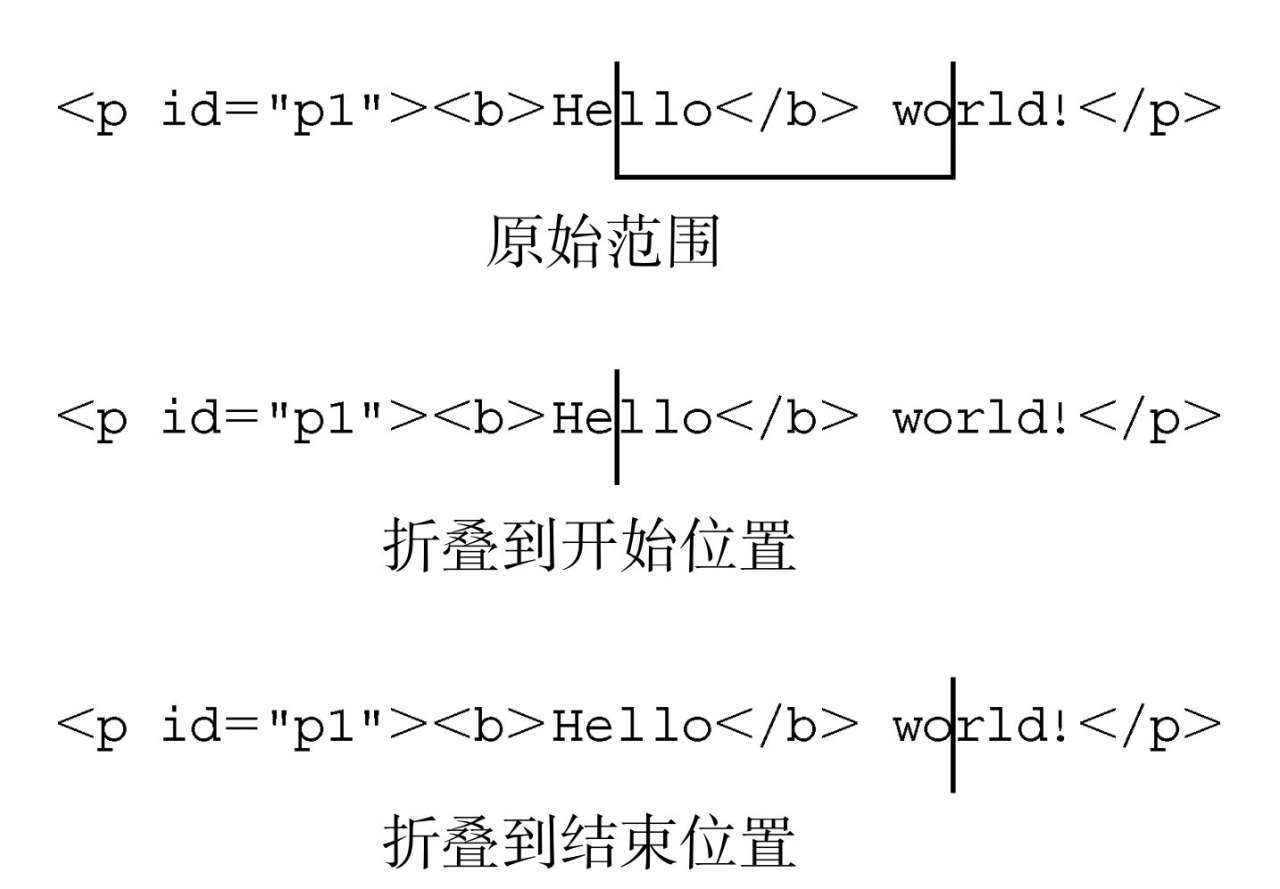
1 | range.collapse(true); //折叠到起点 |
检测某个范围是否处于折叠状态,可以帮我们确定范围中的两个节点是否紧密相邻, 如下:
1 | // html |
在这个例子中,新创建的范围是折叠的,因为p1的后面和p2的前面什么也没有。
3.4.6 比较DOM范围
在有多个范围的情况下,可以使用compareBoundaryPoints()方法来确定这些范围是否有公共的边界(起点或终点)。
❏ Range.START_TO_START(0):比较第一个范围和第二个范围的起点;
❏ Range.START_TO_END(1):比较第一个范围的起点和第二个范围的终点;
❏ Range.END_TO_END(2):比较第一个范围和第二个范围的终点;
❏ Range.END_TO_START(3):比较第一个范围的终点和第一个范围的起点。
compareBoundaryPoints()方法可能的返回值如下:
- 如果第一个范围中的点位于第二个范围中的点之前,返回-1;
- 如果两个点相等,返回0;
- 如果第一个范围中的点位于第二个范围中的点之后,返回1。
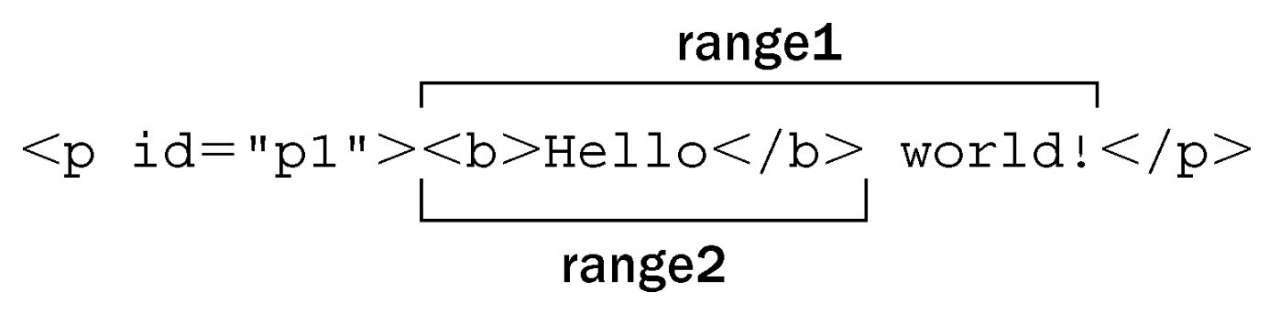
1 | // html |
在这个例子中,两个范围的起点实际上是相同的,因为它们的起点都是由selectNodeContents()方法设置的默认值来指定的。因此,第一次比较返回0。但是,range2的终点由于调用setEndBefore()已经改变了,结果是range1的终点位于range2的终点后面,因此第二次比较返回1。
3.4.7 复制DOM范围
var newRange=range.cloneRange(); 方法会创建调用它的范围的一个副本。新创建的范围与原来的范围包含相同的属性,而修改它的端点不会影响原来的范围。
3.4.8 清理DOM范围
1 | range.detach(); //从文档中分离 |
七、事件
JavaScript与HTML之间的交互是通过事件实现的。事件,就是文档或浏览器窗口中发生的一些特定的交互瞬间。可以使用侦听器(或处理程序)来预订事件,以便事件发生时执行相应的代码。这种在传统软件工程中被称为观察员模式的模型,支持页面的行为(JavaScript代码)与页面的外观(HTML和CSS代码)之间的松散耦合。
1、事件流
如果你单击了某个按钮,他们都认为单击事件不仅仅发生在按钮上。换句话说,在单击按钮的同时,你也单击了按钮的容器元素,甚至也单击了整个页面。
**事件流描述的是从页面中接收事件的顺序。**但有意思的是,IE和Netscape开发团队居然提出了差不多是完全相反的事件流的概念。IE的事件流是事件冒泡流,而Netscape Communicator的事件流是事件捕获流。
1.1 事件冒泡
IE的事件流叫做事件冒泡(event bubbling),即事件开始时由最具体的元素(文档中嵌套层次最深的那个节点)接收,然后逐级向上传播到较为不具体的节点(文档)
如果你单击了页面中的div元素,那么这个click事件会按照如下顺序传播:
(1) <div>
(2) <body>
(3) <html>
(4) document
1.2 事件捕获
事件捕获的思想是不太具体的节点应该更早接收到事件,而最具体的节点应该最后接收到事件。事件捕获的用意在于在事件到达预定目标之前捕获它。
点击div按一下顺序触发click:
(1) document
(2) <html>
(3) <body>
(4) <div>
1.3 DOM事件流
“DOM2级事件”规定的事件流包括三个阶段:事件捕获阶段、处于目标阶段和事件冒泡阶段。首先发生的是事件捕获,为截获事件提供了机会。然后是实际的目标接收到事件。最后一个阶段是冒泡阶段,可以在这个阶段对事件做出响应
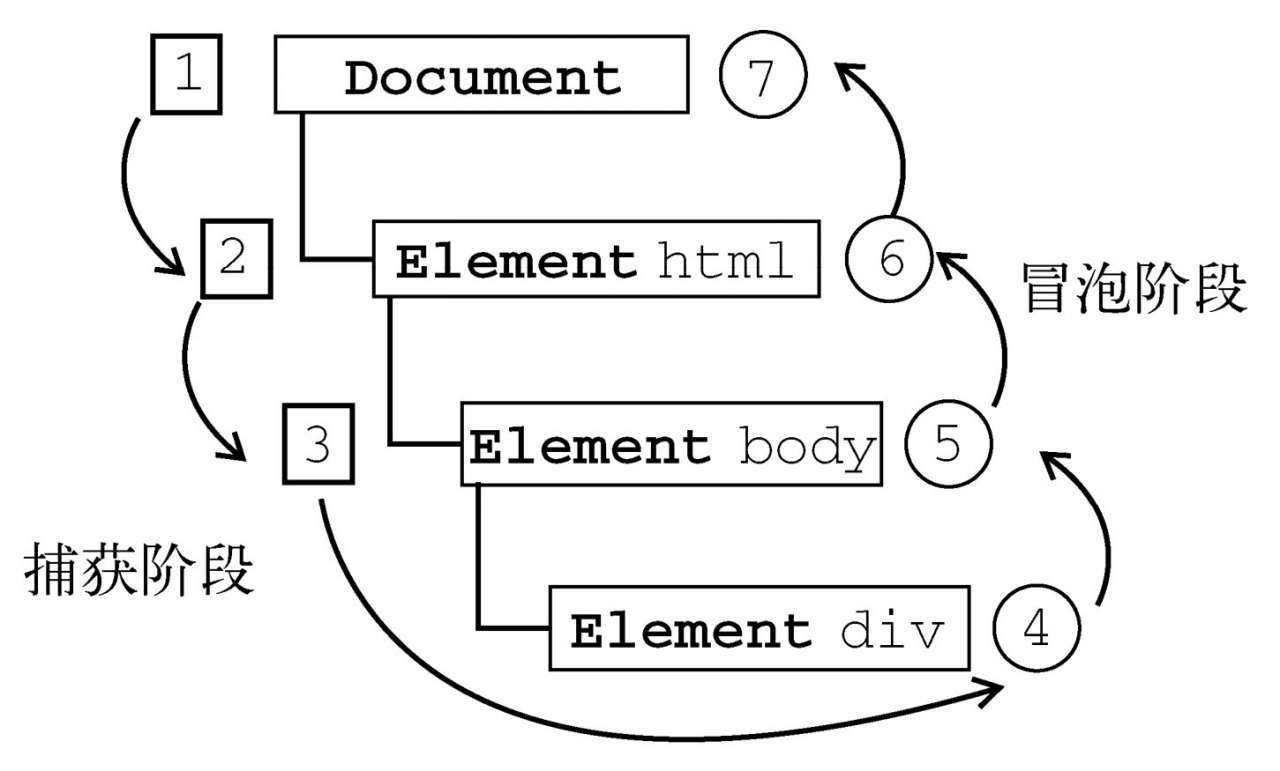
在DOM事件流中,实际的目标(div元素)在捕获阶段不会接收到事件。这意味着在捕获阶段,事件从document到html再到body后就停止了。下一个阶段是“处于目标”阶段,于是事件在div上发生,并在事件处理(后面将会讨论这个概念)中被看成冒泡阶段的一部分。然后,冒泡阶段发生,事件又传播回文档。
2、事件处理程序
事件就是用户或浏览器自身执行的某种动作。诸如click、load和mouseover,都是事件的名字。而响应某个事件的函数就叫做事件处理程序(或事件侦听器)。事件处理程序的名字以”on”开头,因此click事件的事件处理程序就是onclick, load事件的事件处理程序就是onload
2.1 html事件处理程序
1 | // 在这个函数内部,this值等于事件的目标元素,例如: |
2.2 DOM0级事件处理程序
使用DOM0级方法指定的事件处理程序被认为是元素的方法。因此,这时候的事件处理程序是在元素的作用域中运行;换句话说,程序中的this引用当前元素。来看一个例子。
1 | var btn=document.getElementById("myBtn"); |
2.3 DOM2级事件处理程序
“DOM2级事件”定义了两个方法,用于处理指定和删除事件处理程序的操作:addEventListener()和removeEventListener()。所有DOM节点中都包含这两个方法,并且它们都接受3个参数:要处理的事件名、作为事件处理程序的函数和一个布尔值。最后这个布尔值参数如果是true,表示在捕获阶段调用事件处理程序;如果是false,表示在冒泡阶段调用事件处理程序。
通过addEventListener()添加的事件处理程序只能使用removeEventListener()来移除;移除时传入的参数与添加处理程序时使用的参数相同。这也意味着通过addEventListener()添加的匿名函数将无法移除,如下面的例子所示:
1 | var btn=document.getElementById("myBtn"); |
**大多数情况下,都是将事件处理程序添加到事件流的冒泡阶段,这样可以最大限度地兼容各种浏览器。**最好只在需要在事件到达目标之前截获它的时候将事件处理程序添加到捕获阶段。如果不是特别需要,我们不建议在事件捕获阶段注册事件处理程序。
3、事件对象
在触发DOM上的某个事件时,会产生一个事件对象event,这个对象中包含着所有与事件有关的信息。包括导致事件的元素、事件的类型以及其他与特定事件相关的信息。例如,鼠标操作导致的事件对象中,会包含鼠标位置的信息,而键盘操作导致的事件对象中,会包含与按下的键有关的信息
3.1 DOM中的事件对象
1 | let btn = document.getElementById('btn'); |
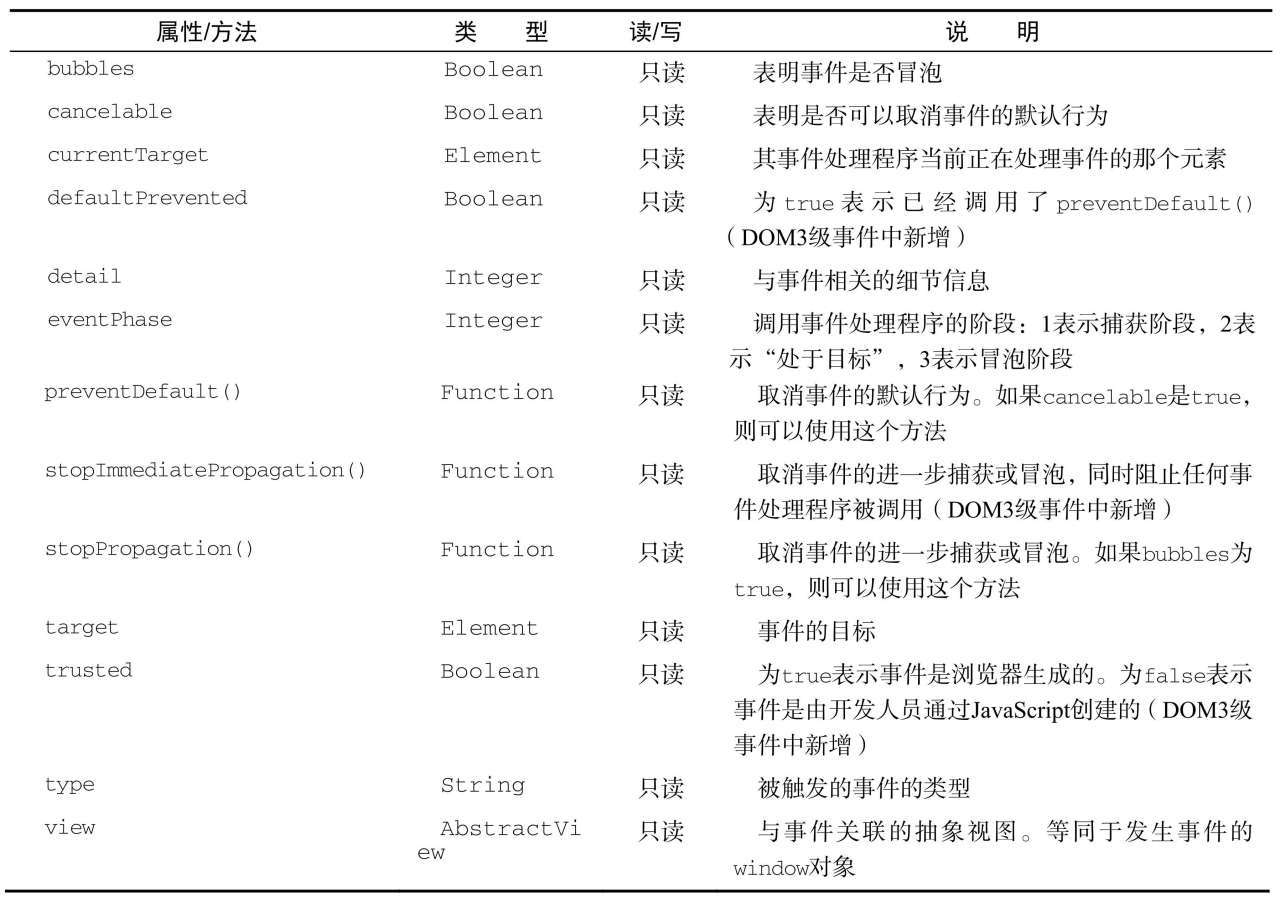
event对象包含与创建它的特定事件有关的属性和方法。触发的事件类型不一样,可用的属性和方法也不一样:
下面例子检测了currentTarget和target与this的值。由于click事件的目标是按钮,因此这三个值是相等的
1 | document.body.onclick = function(event){ |
要阻止特定事件的默认行为,可以使用preventDefault()方法。例如,链接的默认行为就是在被单击时会导航到其href特性指定的URL。如果你想阻止链接导航这一默认行为,那么通过链接的onclick事件处理程序可以取消它。
1 | let link = document.getElementById('myLink'); |
stopPropagation()方法用于立即停止事件在DOM层次中的传播,即取消进一步的事件捕获或冒泡。例如,直接添加到一个按钮的事件处理程序可以调用stopPropagation(),从而避免触发注册在document.body上面的事件处理程序。
1 | let btn = document.getElementById('myBtn'); |
事件对象的eventPhase属性,可以用来确定事件当前正位于事件流的哪个阶段。
如果是在捕获阶段调用的事件处理程序,那么eventPhase等于1;
如果事件处理程序处于目标对象上,则eventPhase等于2;
如果是在冒泡阶段调用的事件处理程序,eventPhase等于3。
这里要注意的是,尽管“处于目标”发生在冒泡阶段,但eventPhase仍然一直等于2。
1 | let btn = document.getElementById('btn'); |
4、事件类型
4.1 UI事件
- load:当页面完全加载后在window上面触发,当所有框架都加载完毕时在框架集上面触发,当图像加载完毕时在img元素上面触发,或者当嵌入的内容加载完毕时在object元素上面触发。
- error:当发生JavaScript错误时在window上面触发,当无法加载图像时在img元素上面触发,当无法加载嵌入内容时在object元素上面触发,或者当有一或多个框架无法加载时在框架集上面触发。
- unload:与load事件对应的是unload事件,这个事件在文档被完全卸载后触发。只要用户从一个页面切换到另一个页面,就会发生unload事件。而利用这个事件最多的情况是清除引用,以避免内存泄漏。
4.2 焦点事件
焦点事件会在页面元素获得或失去焦点时触发。利用这些事件并与document.hasFocus()方法及document.activeElement属性配合。
focus和blur,它们都是JavaScript早期就得到所有浏览器支持的事件。这些事件的最大问题是它们不冒泡。
4.3 鼠标事件
页面上的所有元素都支持鼠标事件。除了mouseenter和mouseleave,所有鼠标事件都会冒泡,也可以被取消,而取消鼠标事件将会影响浏览器的默认行为。取消鼠标事件的默认行为还会影响其他事件,因为鼠标事件与其他事件是密不可分的关系。
4.4 滚轮事件
4.5 文本事件
4.6 键盘事件
4.7 合成事件
4.8 变动事件
5、内存和性能
可是在JavaScript中,添加到页面上的事件处理程序数量将直接关系到页面的整体运行性能。导致这一问题的原因是多方面的。首先,每个函数都是对象,都会占用内存;内存中的对象越多,性能就越差。其次,必须事先指定所有事件处理程序而导致的DOM访问次数,会延迟整个页面的交互就绪时间。
5.1 事件委托
**对“事件处理程序过多”问题的解决方案就是事件委托。事件委托利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。**例如,click事件会一直冒泡到document层次。也就是说,我们可以为整个页面指定一个onclick事件处理程序,而不必给每个可单击的元素分别添加事件处理程序。
事件委派的优点:
- document对象很快就可以访问,而且可以在页面生命周期的任何时点上为它添加事件处理程序(无需等待DOMContentLoaded或load事件)。换句话说,只要可单击的元素呈现在页面上,就可以立即具备适当的功能。
- 整个页面占用的内存空间更少,能够提升整体性能
- 在页面中设置事件处理程序所需的时间更少。只添加一个事件处理程序所需的DOM引用更少,所花的时间也更少。
最适合采用事件委托技术的事件包括click、mousedown、mouseup、keydown、keyup和keypress。虽然mouseover和mouseout事件也冒泡,但要适当处理它们并不容易,而且经常需要计算元素的位置。
5.2 移除事件处理程序
1 | <div id="myDiv"> |
采用事件委托也有助于解决这个问题。如果事先知道将来有可能使用innerHTML替换掉页面中的某一部分,那么就可以不直接把事件处理程序添加到该部分的元素中。而通过把事件处理程序指定给较高层次的元素,同样能够处理该区域中的事件。
6、模拟事件
6.1 DOM中的事件模拟
6.1.1 模拟鼠标事件
6.1.2 模拟键盘事件
6.1.3 模拟其他事件
1 | // 模拟了DOMNodeInserted事件 |
6.1.4 自定义事件
DOM3级还定义了“自定义事件”。自定义事件不是由DOM原生触发的,它的目的是让开发人员创建自己的事件。要创建新的自定义事件,可以调用createEvent(“CustomEvent”)。
6.2 IE中的事件模拟
待梳理,todo
7、总结
在使用事件时,需要考虑如下一些内存与性能方面的问题:
- 有必要限制一个页面中事件处理程序的数量,数量太多会导致占用大量内存,而且也会让用户感觉页面反应不够灵敏。
- 建立在事件冒泡机制之上的事件委托技术,可以有效地减少事件处理程序的数量。
- 建议在浏览器卸载页面之前移除页面中的所有事件处理程序。