1、带着问题看书
- vue响应式原理,为啥修改数据视图会自动更新?
- 虚拟dom的概念和原理,为啥要引入vnode?
- 模板编译原理,vue的模板是如何生效?
- vue整体架构设计和项目结构?
- 不同的生命周期钩子之间的区别,不同的生命周期之间vue内部到底做了什么?
- vue提供全局的api内部原理?
- 过滤器实现原理?
2、vue介绍
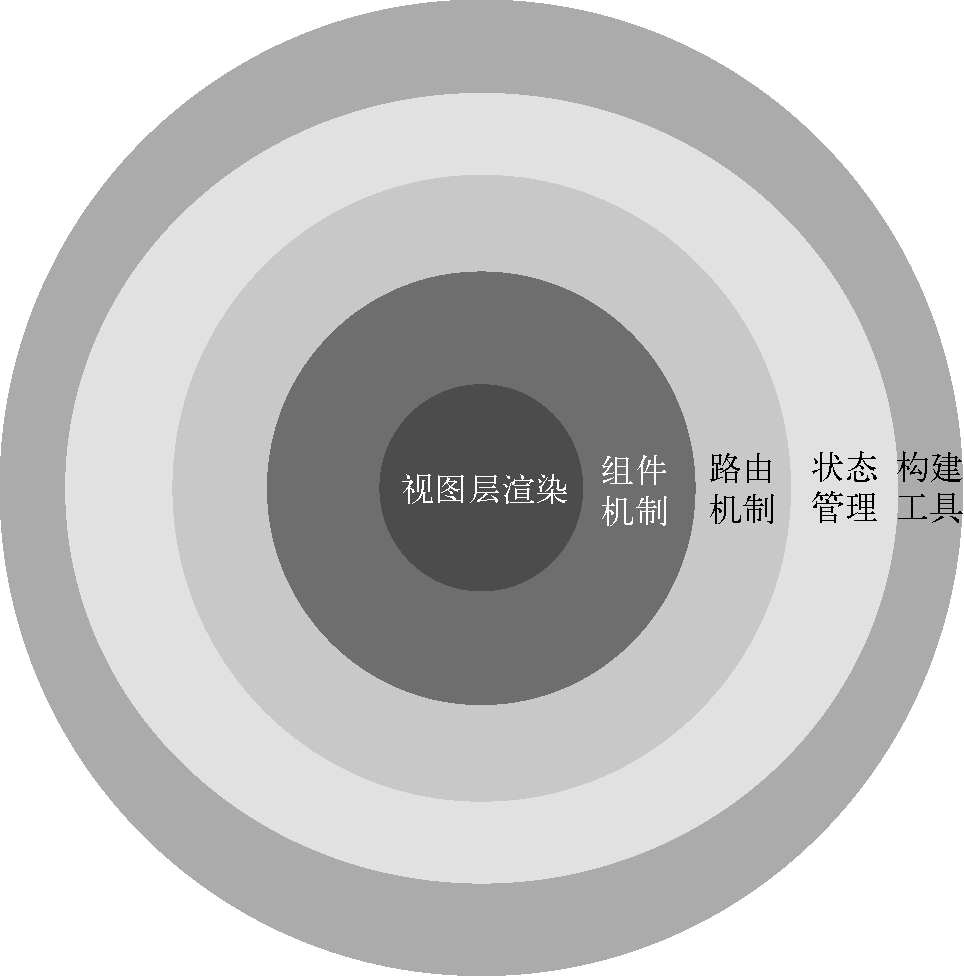
1、什么是渐进式框架
所谓渐进式框架(The Progressive Framework),就是把框架分层。
最核心的部分是视图层渲染,然后往外是组件机制,在这个基础上再加入路由机制,再加入状态管理,最外层是构建工具。
所谓分层,就是说你既可以只用最核心的视图层渲染功能来快速开发一些需求,也可以使用一整套全家桶来开发大型应用。Vue.js有足够的灵活性来适应不同的需求,所以你可以根据自己的需求选择不同的层级。
2、为啥要引入虚拟DOM
Vue.js引入虚拟DOM是有原因的。事实上,并不是引入虚拟DOM后,渲染速度变快了。准确地说,应该是80% 的场景下变得更快了,而剩下的20% 反而变慢了。
任何技术的引入都是在解决一些问题,而通常解决一个问题的同时会引发另外一个问题,这种情况更多的是做权衡,做取舍。
3、变化侦测
1、介绍
**从状态生成DOM,再输出到用户界面显示的一整套流程叫作渲染,应用在运行时会不断地进行重新渲染。**而响应式系统赋予框架重新渲染的能力,其重要组成部分是变化侦测。变化侦测是响应式系统的核心,没有它,就没有重新渲染。框架在运行时,视图也就无法随着状态的变化而变化。
2、Object的变化侦测
大部分人不会想到Object和Array的变化侦测采用不同的处理方式。事实上,它们的侦测方式确实不一样。
2.1 什么是变化侦测
Vue.js会自动通过状态生成DOM,并将其输出到页面上显示出来,这个过程叫渲染。Vue.js的渲染过程是声明式的,我们通过模板来描述状态与DOM之间的映射关系。
变化侦测就是用来解决这个问题的,它分为两种类型:一种是“推”(push),另一种是“拉”(pull)。
Angular和React中的变化侦测都属于“拉”,这就是说当状态发生变化时,它不知道哪个状态变了,只知道状态有可能变了,然后会发送一个信号告诉框架,框架内部收到信号后,会进行一个暴力比对来找出哪些DOM节点需要重新渲染。这在Angular中是脏检查的流程,在React中使用的是虚拟DOM。
而Vue.js的变化侦测属于“推”。当状态发生变化时,Vue.js立刻就知道了,而且在一定程度上知道哪些状态变了。因此,它知道的信息更多,也就可以进行更细粒度的更新。
更细粒度的更新也有一定代价,因为粒度越细,每个状态所绑定的依赖就越多,依赖追踪在内存上的开销就会越大。
2.2 如何追踪变化
两种方法可以侦测到变化:使用Object.defineProperty 和 ES6的Proxy。
1 | function defineReactive(data, key, val){ |
封装好之后,每当从data的key中读取数据时,get函数被触发;每当往data的key中设置数据时,set函数被触发。
2.3 如何依赖收集
如果只是把Object.defineProperty进行封装,那其实并没什么实际用处,真正有用的是收集依赖。
下面例子中,该模板中使用了数据name,所以name它发生变化时,要向使用了它的地方发送通知。
1 | <temple> |
在Vue.js 2.0中,模板使用数据等同于组件使用数据,所以当数据发生变化时,会将通知发送到组件,然后组件内部再通过虚拟DOM重新渲染。
对于上面的问题,我的回答是:先收集依赖,即把用到数据name的地方收集起来,然后等属性发生变化时,把之前收集好的依赖循环触发一遍就好了。总结起来,其实就一句话,在getter中收集依赖,在setter中触发依赖。
2.4 依赖收集在哪里
思考一下,首先想到的是每个key都有一个数组,用来存储当前key的依赖。假设依赖是一个函数,保存在window.target上,现在就可以把defineReactive函数稍微改造一下:
1 | function defineReactive(data, key, val) { |
这里我们新增了数组dep,用来存储被收集的依赖;然后在set被触发时,循环dep以触发收集到的依赖。
但是这样写有点耦合,我们把依赖收集的代码封装成一个Dep类,它专门帮助我们管理依赖。使用这个类,我们可以收集依赖、删除依赖或者向依赖发送通知等。其代码如下:
1 | export default class Dep { |
改造一下defineReactive:
1 | function defineReactive(data, key, val){ |
2.5 依赖是谁
在上面的代码中,我们收集的依赖是window.target,那么它到底是什么?我们究竟要收集谁呢?
收集谁,换句话说,就是当属性发生变化后,通知谁。
我们要通知用到数据的地方,而使用这个数据的地方有很多,而且类型还不一样,既有可能是模板,也有可能是用户写的一个watch,这时需要抽象出一个能集中处理这些情况的类。然后,我们在依赖收集阶段只收集这个封装好的类的实例进来,通知也只通知它一个。接着,它再负责通知其他地方。所以,我们要抽象的这个东西需要先起一个好听的名字。嗯,就叫它Watcher吧。
现在就可以回答上面的问题了,收集谁?Watcher!
2.6 什么是Watcher
Watcher是一个中介的角色,数据发生变化时通知它,然后它再通知其他地方。
1 | // 这段代码表示当data.a.b.c属性发生变化时,触发第二个参数中的函数。 |
思考一下,怎么实现这个功能呢?好像只要把这个watcher实例添加到data.a.b.c属性的Dep中就行了。然后,当data.a.b.c的值发生变化时,通知Watcher。接着,Watcher再执行参数中的这个回调函数。
代码如下:
1 | export default class Watcher { |
2.7 递归侦测所有key
现在,其实已经可以实现变化侦测的功能了,但是前面介绍的代码只能侦测数据中的某一个属性,我们希望把数据中的所有属性(包括子属性)都侦测到,所以要封装一个Observer类。这个类的作用是将一个数据内的所有属性(包括子属性)都转换成getter/setter的形式,然后去追踪它们的变化:
1 | /** |
2.8 关于Object的问题
前面介绍了Object类型数据的变化侦测原理,了解了数据的变化是通过getter/setter来追踪的。也正是由于这种追踪方式,有些语法中即便是数据发生了变化,Vue.js也追踪不到:
- 新增属性:我们在obj上面新增了name属性,Vue.js无法侦测到这个变化,所以不会向依赖发送通知
- 删除属性:我们在action方法中删除了obj中的name属性,而Vue.js无法侦测到这个变化,所以不会向依赖发送通知。
Vue.js通过Object.defineProperty来将对象的key转换成getter/setter的形式来追踪变化,但getter/setter只能追踪一个数据是否被修改,无法追踪新增属性和删除属性,所以才会导致上面例子中提到的问题。
但这也是没有办法的事,因为在ES6之前,JavaScript没有提供元编程的能力,无法侦测到一个新属性被添加到了对象中,也无法侦测到一个属性从对象中删除了。为了解决这个问题,Vue.js提供了两个API——vm.$set与vm.$delete,
2.9 总结
变化侦测就是侦测数据的变化。当数据发生变化时,要能侦测到并发出通知。
Object可以通过Object.defineProperty将属性转换成getter/setter的形式来追踪变化。读取数据时会触发getter,修改数据时会触发setter。
我们需要在getter中收集有哪些依赖使用了数据。当setter被触发时,去通知getter中收集的依赖数据发生了变化。
收集依赖需要为依赖找一个存储依赖的地方,为此我们创建了Dep,它用来收集依赖、删除依赖和向依赖发送消息等。
所谓的依赖,其实就是Watcher。只有Watcher触发的getter才会收集依赖,哪个Watcher触发了getter,就把哪个Watcher收集到Dep中。当数据发生变化时,会循环依赖列表,把所有的Watcher都通知一遍。
Watcher的原理是先把自己设置到全局唯一的指定位置(例如window.target),然后读取数据。因为读取了数据,所以会触发这个数据的getter。接着,在getter中就会从全局唯一的那个位置读取当前正在读取数据的Watcher,并把这个Watcher收集到Dep中去。通过这样的方式,Watcher可以主动去订阅任意一个数据的变化。
此外,我们创建了Observer类,它的作用是把一个object中的所有数据(包括子数据)都转换成响应式的,也就是它会侦测object中所有数据(包括子数据)的变化。
Data、Observer、Dep和Watcher之间的关系:
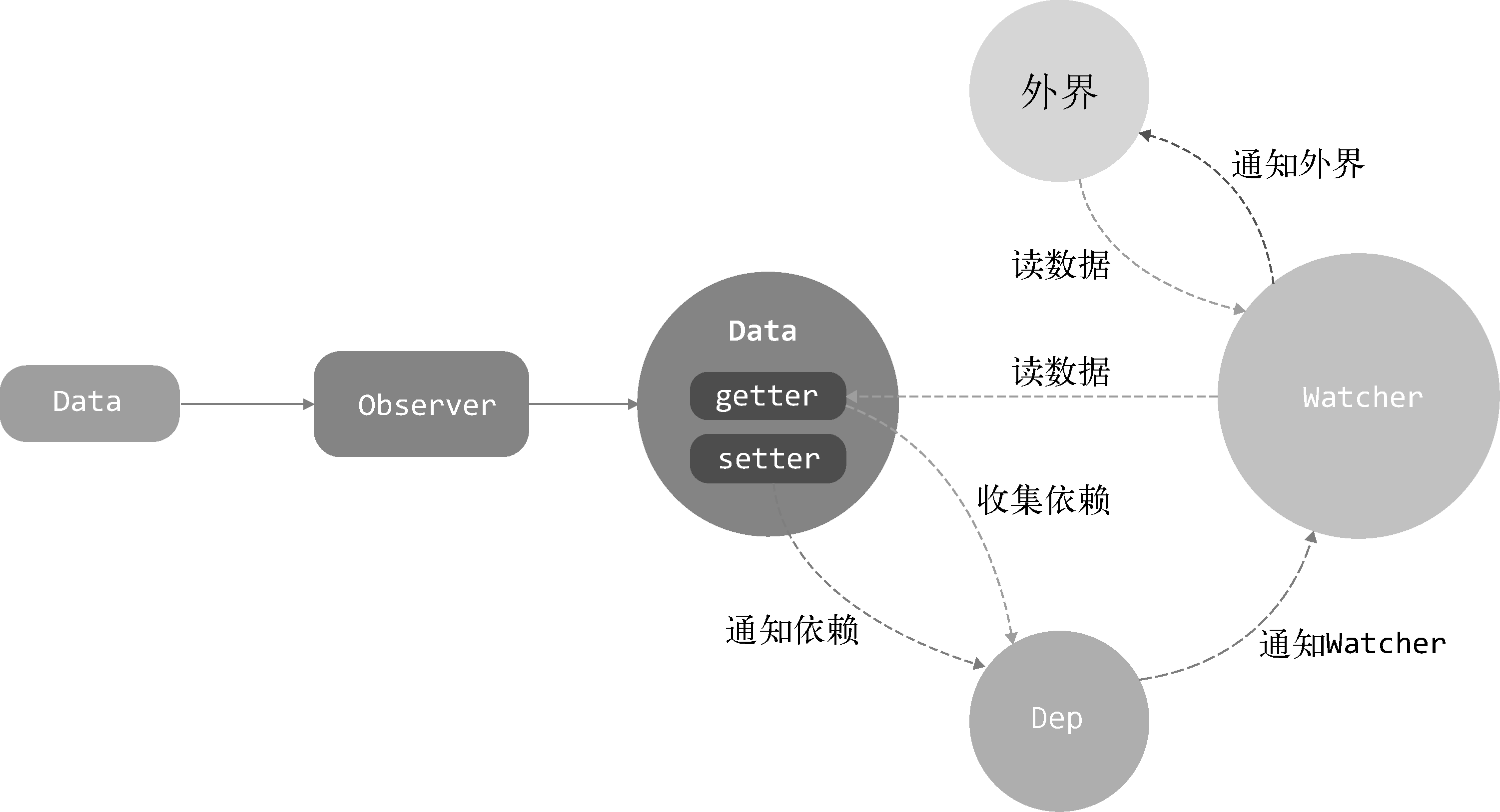
Data通过Observer转换成了getter/setter的形式来追踪变化;
当外界通过Watcher读取数据时,会触发getter从而将Watcher添加到依赖中;
当数据发生了变化时,会触发setter,从而向Dep中的依赖(Watcher)发送通知;
Watcher接收到通知后,会向外界发送通知,变化通知到外界后可能会触发视图更新,也有可能触发用户的某个回调函数等。
3、 Array的变化侦测
3.1 介绍
这个例子使用了push方法来改变数组,并不会触发getter/setter
1 | this.list.push(1); |
正因为我们可以通过Array原型上的方法来改变数组的内容,所以Object那种通过getter/setter的实现方式就行不通了
3.2 如何追踪变化
Object的变化是靠setter来追踪的,只要一个数据发生了变化,一定会触发setter。
在ES6之前,JavaScript并没有提供元编程的能力,也就是没有提供可以拦截原型方法的能力,但是这难不倒聪明的程序员们。我们可以用自定义的方法去覆盖原生的原型方法。
我们可以用一个拦截器覆盖Array.prototype。之后,每当使用Array原型上的方法操作数组时,其实执行的都是拦截器中提供的方法,比如push方法。然后,在拦截器中使用原生Array的原型方法去操作数组。
3.3 拦截器
拦截器其实就是一个和Array.prototype一样的Object,里面包含的属性一模一样,只不过这个Object中某些可以改变数组自身内容的方法是我们处理过的。
我们发现Array原型中可以改变数组自身内容的方法有7个,分别是push、pop、shift、unshift、splice、sort和reverse。
1 | const arrayProto = Array.prototype; |
我们创建了变量arrayMethods,它继承自Array.prototype,具备其所有功能。未来,我们要使用arrayMethods去覆盖Array.prototype
接下来,在arrayMethods上使用Object.defineProperty方法将那些可以改变数组自身内容的方法(push、pop、shift、unshift、splice、sort和reverse)进行封装。
所以,当使用push方法的时候,其实调用的是arrayMethods.push,而arrayMethods.push是函数mutator,也就是说,实际上执行的是mutator函数。(我们就可以在mutator函数中做一些其他的事,比如说发送变化通知)
最后,在mutator中执行original(它是原生Array.prototype上的方法,例如Array.prototype.push)来做它应该做的事,比如push的功能。
3.4 使用拦截器覆盖Array原型
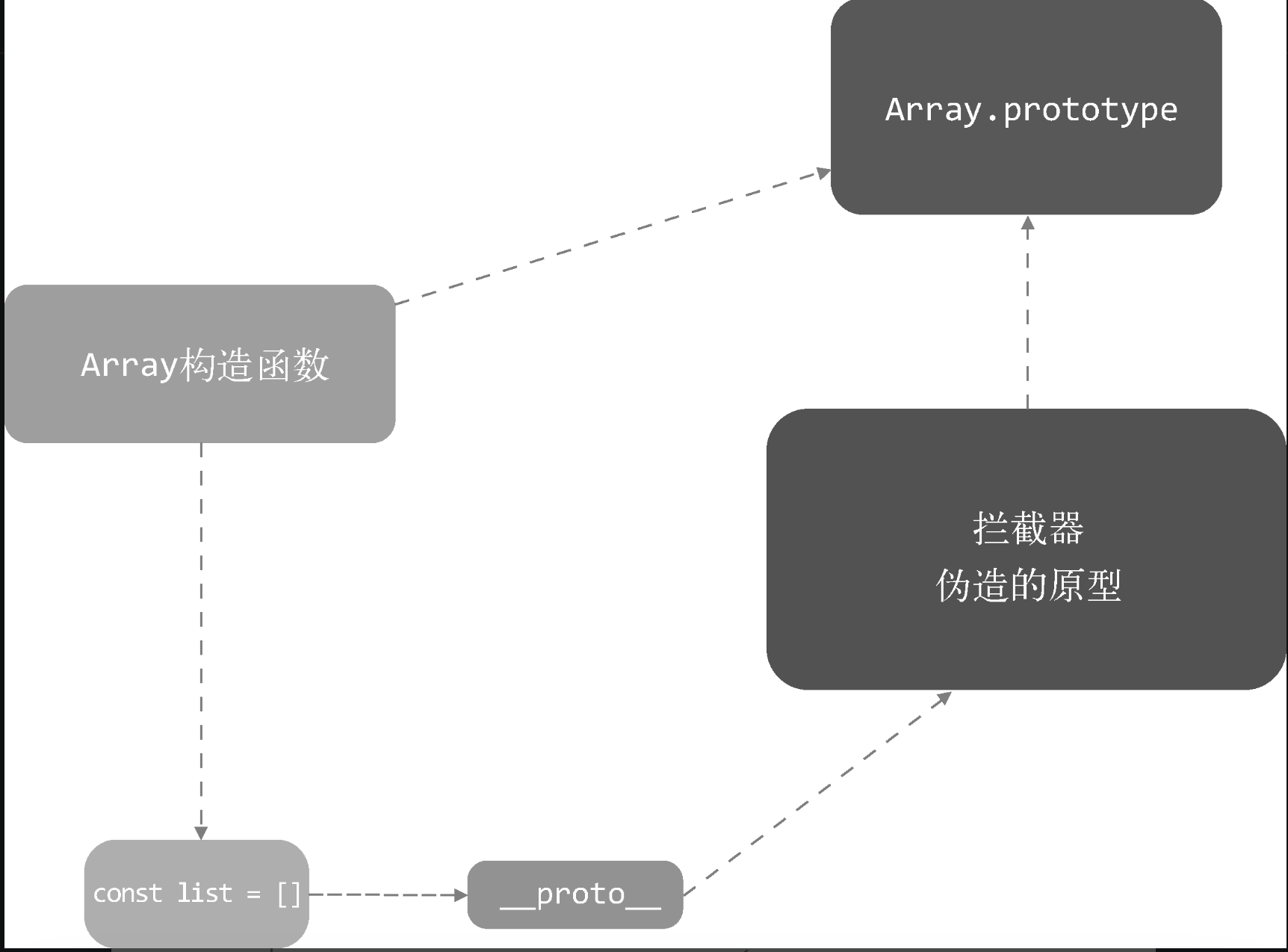
有了拦截器之后,想要让它生效,就需要使用它去覆盖Array.prototype。但是我们又不能直接覆盖,因为这样会污染全局的Array,这并不是我们希望看到的结果。我们希望拦截操作只针对那些被侦测了变化的数据生效,也就是说希望拦截器只覆盖那些响应式数组的原型。
而将一个数据转换成响应式的,需要通过Observer,所以我们只需要在Observer中使用拦截器覆盖那些即将被转换成响应式Array类型数据的原型就好了:
1 | export class Observer { |
通过 _proto_ 可以很巧妙地实现覆盖value原型的功能
3.5 将拦截器方法挂载到数组的属性上
虽然绝大多数浏览器都支持这种非标准的属性(在ES6之前并不是标准)来访问原型,但并不是所有浏览器都支持!因此,我们需要处理不能使用 _proto_ 的情况。
Vue的做法非常粗暴,如果不能使用 _proto_,就直接将arrayMethods身上的这些方法设置到被侦测的数组上
1 | import { arrayMethods } from './array'; |
在浏览器不支持 proto 的情况下,会在数组上挂载一些方法。当用户使用这些方法时,其实执行的并不是浏览器原生提供的Array.prototype上的方法,而是拦截器中提供的方法。
因为当访问一个对象的方法时,只有其自身不存在这个方法,才会去它的原型上找这个方法。
3.6 如何收集依赖
可能你也发现了,如果只有一个拦截器,其实还是什么事都做不了。为什么会这样呢?因为我们之所以创建拦截器,本质上是为了得到一种能力,一种当数组的内容发生变化时得到通知的能力。
而现在我们虽然具备了这样的能力,但是通知谁呢?前面我们介绍Object时说过,答案肯定是通知Dep中的依赖(Watcher),但是依赖怎么收集呢?这就是本节要介绍的内容,如何收集数组的依赖!
Array在getter中收集依赖,在拦截器中触发依赖。
3.7 依赖列表存在哪儿
Vue.js把Array的依赖存放在Observer中:
1 | export class Observer { |
3.8 收集依赖
把Dep实例保存在Observer的属性上之后,我们可以在getter中像下面这样访问并收集依赖:
1 | function defineReactive(data, key, val){ |
3.9 在拦截器中获取Observer实例
因为Array拦截器是对原型的一种封装,所以可以在拦截器中访问到this(当前正在被操作的数组)。
而dep保存在Observer中,所以需要在this上读到Observer的实例:
1 | // 工具函数 |
所有被侦测了变化的数据身上都会有一个 _ob_ 属性来表示它们是响应式的。上一节中的observe函数就是通过 _ob_ 属性来判断:如果value是响应,如果value是响应式的,则直接返回 _ob_;如果不是响应式的,则使用new Observer来将数据转换成响应式数据。
当value身上被标记了 _ob_ 之后,就可以通过value._ob_ 来访问Observer实例。如果是Array拦截器,因为拦截器是原型方法,所以可以直接通过this.__ob__来访问Observer实例。例如:
1 | ['push', 'pop', 'shift', 'unshift', 'splice', 'sort', 'reverse']. |
3.10 向数组的依赖发送通知
当侦测到数组发生变化时,会向依赖发送通知。此时,首先要能访问到依赖。前面已经介绍过如何在拦截器中访问Observer实例,所以这里只需要在Observer实例中拿到dep属性,然后直接发送通知就可以了:
1 | ['push', 'pop', 'shift', 'unshift', 'splice', 'sort', 'reverse']. |
在上面的代码中,我们调用了ob.dep.notify()去通知依赖(Watcher)数据发生了改变。
3.11 侦测数组中元素的变化
我们要在Observer中新增一些处理,让它可以将Array也转换成响应式的:
1 | export class Observer { |
这里新增了observeArray方法,其作用是循环Array中的每一项,执行observe函数来侦测变化。前面介绍过observe函数,其实就是将数组中的每个元素都执行一遍new Observer,这很明显是一个递归的过程。
现在只要将一个数据丢进去,Observer就会把这个数据的所有子数据转换成响应式的。接下来,我们介绍如何侦测数组中新增元素的变化。
3.12 侦测新增元素的变化
数组中有一些方法是可以新增数组内容的,比如push,而新增的内容也需要转换成响应式来侦测变化,否则会出现修改数据时无法触发消息等问题。因此,我们必须侦测数组中新增元素的变化。
其实现方式其实并不难,只要能获取新增的元素并使用Observer来侦测它们就行。
3.12.1 获取新增元素
想要获取新增元素,我们需要在拦截器中对数组方法的类型进行判断。如果操作数组的方法是push、unshift和splice(可以新增数组元素的方法),则把参数中新增的元素拿过来,用Observer来侦测:
1 | ['pop', 'push', 'shift', 'splice', 'sort', 'reverse']. |
我们通过switch对method进行判断,如果method是push、unshift、splice这种可以新增数组元素的方法,那么从args中将新增元素取出来,暂存在inserted中。
接下来,我们要使用Observer把inserted中的元素转换成响应式的。
3.12.2 使用Observer侦测新增元素
前面介绍过Observer会将自身的实例附加到value的 _ob_ 属性上。所有被侦测了变化的数据都有一个 _ob_ 属性,数组元素也不例外。
因此,我们可以在拦截器中通过this访问到 _ob,然后调用 _ob 上的observeArray方法就可以了:
1 | ['push', 'pop', 'shift', 'unshift', 'splice', 'sort', 'reverse']. |
3.15 关于Array的问题
1 | this.list[0] = 1; // 即修改数组中第一个元素的值时,无法侦测到数组的变化 |
因为Vue.js的实现方式决定了无法对上面举的两个例子做拦截,也就没有办法响应。在ES6之前,无法做到模拟数组的原生行为,所以拦截不到也是没有办法的事情。ES6提供了元编程的能力,所以有能力拦截,我猜测未来Vue.js很有可能会使用ES6提供的Proxy来实现这部分功能,从而解决这个问题。
3.13 总结
Array追踪变化的方式和Object不一样。因为它是通过方法来改变内容的,所以我们通过创建拦截器去覆盖数组原型的方式来追踪变化。
为了不污染全局Array.prototype,我们在Observer中只针对那些需要侦测变化的数组使用 _proto_ 来覆盖原型方法,但 _proto_ 在ES6之前并不是标准属性,不是所有浏览器都支持它。因此,针对不支持 _proto_ 属性的浏览器,我们直接循环拦截器,把拦截器中的方法直接设置到数组身上来拦截Array.prototype上的原生方法。
Array收集依赖的方式和Object一样,都是在getter中收集。但是由于使用依赖的位置不同,数组要在拦截器中向依赖发消息,所以依赖不能像Object那样保存在defineReactive中,而是把依赖保存在了Observer实例上。
在Observer中,我们对每个侦测了变化的数据都标上印记 _ob,并把this(Observer实例)保存在 _ob 上。这主要有两个作用,一方面是为了标记数据是否被侦测了变化(保证同一个数据只被侦测一次),另一方面可以很方便地通过数据取到 _ob_,从而拿到Observer实例上保存的依赖。当拦截到数组发生变化时,向依赖发送通知。
除了侦测数组自身的变化外,数组中元素发生的变化也要侦测。我们在Observer中判断如果当前被侦测的数据是数组,则调用observeArray方法将数组中的每一个元素都转换成响应式的并侦测变化。
除了侦测已有数据外,当用户使用push等方法向数组中新增数据时,新增的数据也要进行变化侦测。我们使用当前操作数组的方法来进行判断,如果是push、unshift和splice方法,则从参数中将新增数据提取出来,然后使用observeArray对新增数据进行变化侦测。
由于在ES6之前,JavaScript并没有提供元编程的能力,所以对于数组类型的数据,一些语法无法追踪到变化,只能拦截原型上的方法,而无法拦截数组特有的语法,例如使用length清空数组的操作就无法拦截。
4、变化侦测相关的API实现原理
4.1 vm.$watch
4.1.1 用法
用于观察一个表达式或computed函数在Vue.js实例上的变化。回调函数调用时,会从参数得到新数据(new value)和旧数据(old value)。表达式只接受以点分隔的路径,例如a.b.c。如果是一个比较复杂的表达式,可以用函数代替表达式。
1 | let unwatch = vm.$watch('a.b.c', function (newVal, oldVal) { |
deep。为了发现对象内部值的变化,可以在选项参数中指定deep: true:
1 | vm.$watch('someObj', callback, { |
immediate。在选项参数中指定immediate: true,将立即以表达式的当前值触发回调:
1 | vm.$watch('a', callback, { |
4.1.2 原理
vm.$watch其实是对Watcher的一种封装,但vm.$watch中的参数deep和immediate是Watcher中所没有的。下面我们来看一看vm.$watch到底是怎么实现的:
1 | Vue.prototype.$watch = function(expOrFn, cb, options){ |
先执行new Watcher来实现vm.$watch的基本功能。这里有一个细节需要注意,expOrFn是支持函数的,而我们在第2章中并没有介绍。这里我们需要对Watcher进行一个简单的修改:
1 | export default class Watcher { |
当expOrFn是函数时,会发生很神奇的事情。它不只可以动态返回数据,其中读取的所有数据也都会被Watcher观察。当expOrFn是字符串类型的keypath时,Watcher会读取这个keypath所指向的数据并观察这个数据的变化。而当expOrFn是函数时,Watcher会同时观察expOrFn函数中读取的所有Vue.js实例上的响应式数据。也就是说,如果函数从Vue.js实例上读取了两个数据,那么Watcher会同时观察这两个数据的变化,当其中任意一个发生变化时,Watcher都会得到通知。(Vue.js中计算属性 Computed 的实现原理与expOrFn支持函数有很大的关系)
现在要在Watcher中添加该方法来实现unwatch的功能:
首先,需要在Watcher中记录自己都订阅了谁,也就是watcher实例被收集进了哪些Dep里。然后当Watcher不想继续订阅这些Dep时,循环自己记录的订阅列表来通知它们(Dep)将自己从它们(Dep)的依赖列表中移除掉。
1 | export default class Wather { |
执行this.depIds.add来记录当前Watcher已经订阅了这个Dep。
然后执行this.deps.push(dep)记录自己都订阅了哪些Dep。
最后,触发dep.addSub(this)来将自己订阅到Dep中。
在Watcher中新增addDep方法后,Dep中收集依赖的逻辑也需要有所改变:
1 | let uid = 0; |
4.1.3 deep参数的实现原理
要想实现deep的功能,其实就是除了要触发当前这个被监听数据的收集依赖的逻辑之外,还要把当前监听的这个值在内的所有子值都触发一遍收集依赖逻辑。这就可以实现当前这个依赖的所有子数据发生变化时,通知当前Watcher了。
1 | export default class Wather { |
一定要在window.target = undefined之前去触发子值的收集依赖逻辑,这样才能保证子集收集的依赖是当前这个Watcher。如果在window.target = undefined之后去触发收集依赖的逻辑,那么其实当前的Watcher并不会被收集到子值的依赖列表中,也就无法实现deep的功能。
接下来,要递归value的所有子值来触发它们收集依赖的功能:
1 | const seenObjects = new Set(); |
4.2 vm.$set
4.2.1 用法
1 | vm.$set(target, key, value); |
用法:在object上设置一个属性,如果object是响应式的,Vue.js会保证属性被创建后也是响应式的,并且触发视图更新。这个方法主要用来避开Vue.js不能侦测属性被添加的限制。
原因:只有已经存在的属性的变化会被追踪到,新增的属性无法被追踪到。因为在ES6之前,JavaScript并没有提供元编程的能力,所以根本无法侦测object什么时候被添加了一个新属性。
1 | /** |
4.2.2 原理
1 | import { set } from '../observer/index'; |
1、Array处理:
1 | export function set (target, key, val){ |
如果target是数组并且key是一个有效的索引值,就先设置length属性。这样如果我们传递的索引值大于当前数组的length,就需要让target的length等于索引值。
通过splice方法把val设置到target中的指定位置(参数中提供的索引值的位置)。当我们使用splice方法把val设置到target中的时候,数组拦截器会侦测到target发生了变化,并且会自动帮助我们把这个新增的val转换成响应式的。
2、key已经存在target中
1 | export function set(target, key, val){ |
由于key已经存在于target中,所以其实这个key已经被侦测了变化。也就是说,这种情况属于修改数据,直接用key和val改数据就好了。
3、处理新增属性
1 | export function set(target, key, val){ |
要处理文档中所说的“target不能是Vue.js实例或Vue.js实例的根数据对象”的情况。
实现这个功能并不难,只需要使用target._isVue来判断target是不是Vue.js实例,使用ob.vmCount来判断它是不是根数据对象即可。
那么,什么是根数据?this.$data就是根数据。
接下来,我们处理target不是响应式的情况。如果target身上没有 _ob_ 属性,说明它并不是响应式的,并不需要做什么特殊处理,只需要通过key和val在target上设置就行了
4.3 vm.$delete
4.3.1 用法
1 | vm.$delete(target, key); |
删除对象的属性。如果对象是响应式的,需要确保删除能触发更新视图。这个方法主要用于避开Vue.js不能检测到属性被删除的限制,但是你应该很少会使用它。
强烈不推荐这样写代码:
1 | delete this.obj.name; |
4.3.2 原理
1 | import { del } from '../observer/index'; |
1、处理Array
1 | export function del (target, key){ |
只需要使用splice将参数key所指定的索引位置的元素删除即可。因为使用了splice方法,数组拦截器会自动向依赖发送通知。
vm.$delete也不可以在Vue.js实例或Vue.js实例的根数据对象上使用:
1 | export function del (target, key){ |
4.4 总结
待补充吧
4、虚拟DOM
Vue.js 2.0引入了虚拟DOM,比Vue.js 1.0的初始渲染速度提升了2~4倍,并大大降低了内存消耗。
1、虚拟DOM简介
1.1 虚拟DOM背景
虚拟DOM是随着时代发展而诞生的产物。
在Web早期,页面的交互效果比现在简单得多,没有很复杂的状态需要管理,也不太需要频繁地操作DOM,使用jQuery来开发就可以满足我们的需求。
随着时代的发展,页面上的功能越来越多,我们需要实现的需求也越来越复杂,程序中需要维护的状态也越来越多,DOM操作也越来越频繁。
命令式操作DOM:当状态变得越来越多,DOM操作越来越频繁时,我们就会发现如果像之前那样使用jQuery来开发页面,那么代码中会有相当多的代码是在操作DOM,程序中的状态也很难管理,代码中的逻辑也很混乱。
声明式操作DOM: 我们通过描述状态和DOM之间的映射关系是怎样的,就可以将状态渲染成视图。关于状态到视图的转换过程,框架会帮我们做,不需要我们自己手动去操作DOM。
然而通常程序在运行时,状态会不断发生变化(引起状态变化的原因有很多,有可能是用户点击了某个按钮,也可能是某个Ajax请求,这些行为都是异步发生的。理论上,所有异步行为都有可能引起状态变化)。每当状态发生变化时,都需要重新渲染。如何确定状态中发生了什么变化以及需要在哪里更新DOM?
在这种情况下,最简单粗暴的解决方式是,既不需要关心状态发生了什么变化,也不需要关心在哪里更新DOM,我们只需要把所有DOM全删了,然后使用状态重新生成一份DOM,并将其输出到页面上显示出来就好了。
但是访问DOM是非常昂贵的。按照上面说的方式做,会造成相当多的性能浪费。状态变化通常只有有限的几个节点需要重新渲染,所以我们不仅需要找出哪里需要更新,还需要尽可能少地访问DOM。
业界3大框架解决方案:
- Angular中就是脏检查的流程
- React中使用虚拟DOM
- Vue.js 1.0通过细粒度的绑定
虚拟DOM的解决方式是通过状态生成一个虚拟节点树,然后使用虚拟节点树进行渲染。在渲染之前,会使用新生成的虚拟节点树和上一次生成的虚拟节点树进行对比,只渲染不同的部分。
1.2 为什么要引入虚拟DOM
事实上,Angular和React的变化侦测有一个共同点,那就是它们都不知道哪些状态(state)变了。因此,就需要进行比较暴力的比对,React是通过虚拟DOM的比对,Angular是使用脏检查的流程。
Vue.js的变化侦测和它们都不一样,它在一定程度上知道具体哪些状态发生了变化,这样就可以通过更细粒度的绑定来更新视图。也就是说,在Vue.js中,当状态发生变化时,它在一定程度上知道哪些节点使用了这个状态,从而对这些节点进行更新操作,根本不需要比对。事实上,在Vue.js 1.0的时候就是这样实现的。
但是这样做其实也有一定的代价。因为粒度太细,每一个绑定都会有一个对应的watcher来观察状态的变化,这样就会有一些内存开销以及一些依赖追踪的开销。当状态被越多的节点使用时,开销就越大。对于一个大型项目来说,这个开销是非常大的。
因此,Vue.js 2.0开始选择了一个中等粒度的解决方案,那就是引入了虚拟DOM。组件级别是一个watcher实例,就是说即便一个组件内有10个节点使用了某个状态,但其实也只有一个watcher在观察这个状态的变化。所以当这个状态发生变化时,只能通知到组件,然后组件内部通过虚拟DOM去进行比对与渲染。这是一个比较折中的方案。
Vue.js之所以能随意调整绑定的粒度,本质上还要归功于变化侦测。
1.3 vue.js中的虚拟dom
在Vue.js中,我们使用模板来描述状态与DOM之间的映射关系。Vue.js通过编译将模板转换成渲染函数(render),执行渲染函数就可以得到一个虚拟节点树,使用这个虚拟节点树就可以渲染页面:
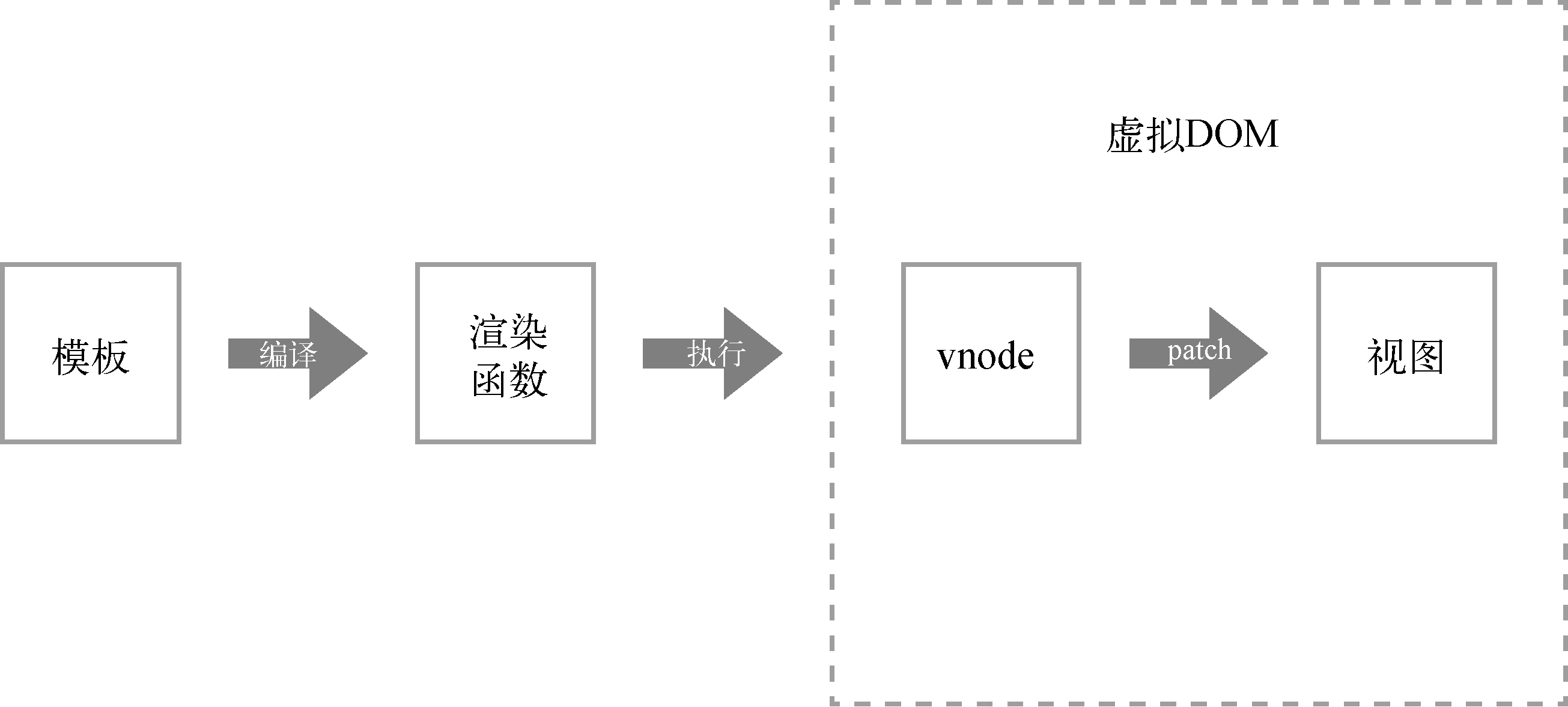
由于DOM操作比较慢,所以这些DOM操作在性能上会有一定的浪费,避免这些不必要的DOM操作会提升很大一部分性能。
为了避免不必要的DOM操作,虚拟DOM在虚拟节点映射到视图的过程中,将虚拟节点与上一次渲染视图所使用的旧虚拟节点(oldVnode)做对比,找出真正需要更新的节点来进行DOM操作,从而避免操作其他无任何改动的DOM。
虚拟DOM的执行流程:
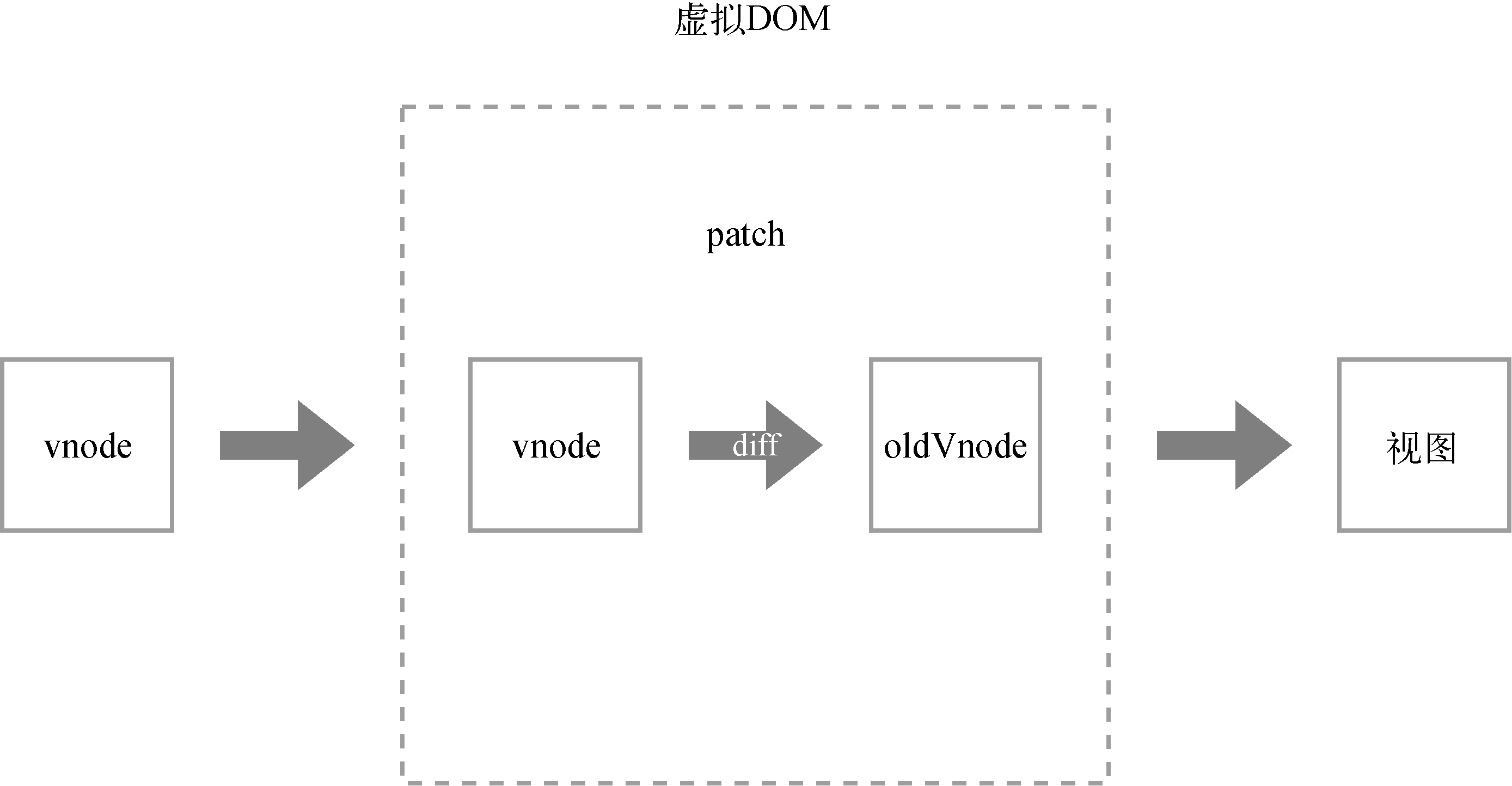
虚拟DOM在Vue.js中所做的事情其实并没有想象中那么复杂,它主要做了两件事:
- 提供与真实DOM节点所对应的虚拟节点vnode。
- 将虚拟节点vnode和旧虚拟节点oldVnode进行比对,然后更新视图
1.4 总结
虚拟DOM是将状态映射成视图的众多解决方案中的一种,它的运作原理是使用状态生成虚拟节点,然后使用虚拟节点渲染视图。
之所以需要先使用状态生成虚拟节点,是因为如果直接用状态生成真实DOM,会有一定程度的性能浪费。而先创建虚拟节点再渲染视图,就可以将虚拟节点缓存,然后使用新创建的虚拟节点和上一次渲染时缓存的虚拟节点进行对比,然后根据对比结果只更新需要更新的真实DOM节点,从而避免不必要的DOM操作,节省一定的性能开销。
Vue.js中通过模板来描述状态与视图之间的映射关系,所以它会先将模板编译成渲染函数,然后执行渲染函数生成虚拟节点,最后使用虚拟节点更新视图。
因此,虚拟DOM在Vue.js中所做的事是提供虚拟节点vnode和对新旧两个vnode进行比对,并根据比对结果进行DOM操作来更新视图。
2、VNode
2.1 VNode简介
在Vue.js中存在一个VNode类,使用它可以实例化不同类型的vnode实例,而不同类型的vnode实例各自表示不同类型的DOM元素。
例如,DOM元素有元素节点、文本节点和注释节点等,vnode实例也会对应着有元素节点、文本节点和注释节点等。
1 | export default class VNode { |
简单地说,vnode可以理解成节点描述对象,它描述了应该怎样去创建真实的DOM节点。
vnode表示一个真实的DOM元素,所有真实的DOM节点都使用vnode创建并插入到页面中:
Vnode –create–> DOM –insert–> 视图
2.2 VNode作用
由于每次渲染视图时都是先创建vnode,然后使用它创建真实DOM插入到页面中,所以可以将上一次渲染视图时所创建的vnode缓存起来,之后每当需要重新渲染视图时,将新创建的vnode和上一次缓存的vnode进行对比,查看它们之间有哪些不一样的地方,找出这些不一样的地方并基于此去修改真实的DOM。
Vue.js目前对状态的侦测策略采用了中等粒度。当状态发生变化时,只通知到组件级别,然后组件内使用虚拟DOM来渲染视图。
也就是说,只要组件使用的众多状态中有一个发生了变化,那么整个组件就要重新渲染。
如果组件只有一个节点发生了变化,那么重新渲染整个组件的所有节点,很明显会造成很大的性能浪费。因此,对vnode进行缓存,并将上一次缓存的vnode和当前新创建的vnode进行对比,只更新发生变化的节点就变得尤为重要。这也是vnode最重要的一个作用。
2.3 VNode类型
vnode的类型有以下几种:
- 注释节点
- 文本节点
- 元素节点
- 组件节点
- 函数式组件
- 克隆节点
2.3.1 注释节点
1 | <!-- 注释节点 --> |
1 | { |
2.3.2 文本节点
当文本类型的vnode被创建时,它只有一个text属性:
1 | export function createTextVNode(val){ |
2.3.3 克隆节点
克隆节点是将现有节点的属性复制到新节点中,让新创建的节点和被克隆节点的属性保持一致,从而实现克隆效果。它的作用是优化静态节点和插槽节点(slot node)。
以静态节点为例,当组件内的某个状态发生变化后,当前组件会通过虚拟DOM重新渲染视图,静态节点因为它的内容不会改变,所以除了首次渲染需要执行渲染函数获取vnode之外,后续更新不需要执行渲染函数重新生成vnode。因此,这时就会使用创建克隆节点的方法将vnode克隆一份,使用克隆节点进行渲染。这样就不需要重新执行渲染函数生成新的静态节点的vnode,从而提升一定程度的性能
1 | export function cloneVNode(vnode, depp){ |
2.3.4 元素节点
元素节点通常会存在以下4种有效属性。
- tag:顾名思义,tag就是一个节点的名称,例如p、ul、li和div等。
- data:该属性包含了一些节点上的数据,比如attrs、class和style等。
- children:当前节点的子节点列表。
- context:它是当前组件的Vue.js实例。
1 | <p><span>Hello</span><span>Berwin</span></p> |
1 | { |
2.3.5 组件节点
组件节点和元素节点类似,有以下两个独有的属性。
- componentOptions:顾名思义,就是组件节点的选项参数,其中包含propsData、tag和children等信息
- componentInstance:组件的实例,也是Vue.js的实例。事实上,在Vue.js中,每个组件都是一个Vue.js实例
1 | <child></child> |
2.3.6 函数式组件
函数式组件和组件节点类似,它有两个独有的属性functionalContext和functionalOptions
3、patch
虚拟DOM最核心的部分是patch,它可以将vnode渲染成真实的DOM。
之所以要这么做,主要是因为DOM操作的执行速度远不如JavaScript的运算速度快。因此,把大量的DOM操作搬运到JavaScript中,使用patching算法来计算出真正需要更新的节点,最大限度地减少DOM操作,从而显著提升性能。这本质上其实是使用JavaScript的运算成本来替换DOM操作的执行成本,而JavaScript的运算速度要比DOM快很多,这样做很划算,所以才会有虚拟DOM。
3.1 patch介绍
对现有DOM进行修改需要做三件事:
- 创建新增的节点;
- 删除已经废弃的节点;
- 修改需要更新的节点。
之所以需要通过算法来比对两个节点之间的差异,并针对不同的节点进行更新,主要是为了性能考虑。
我们完全可以把整个旧节点从DOM中删除,然后使用最新的状态(state)重新生成一份全新的节点并插入到DOM中,这种方式完全可以实现功能。
3.1.1 新增节点
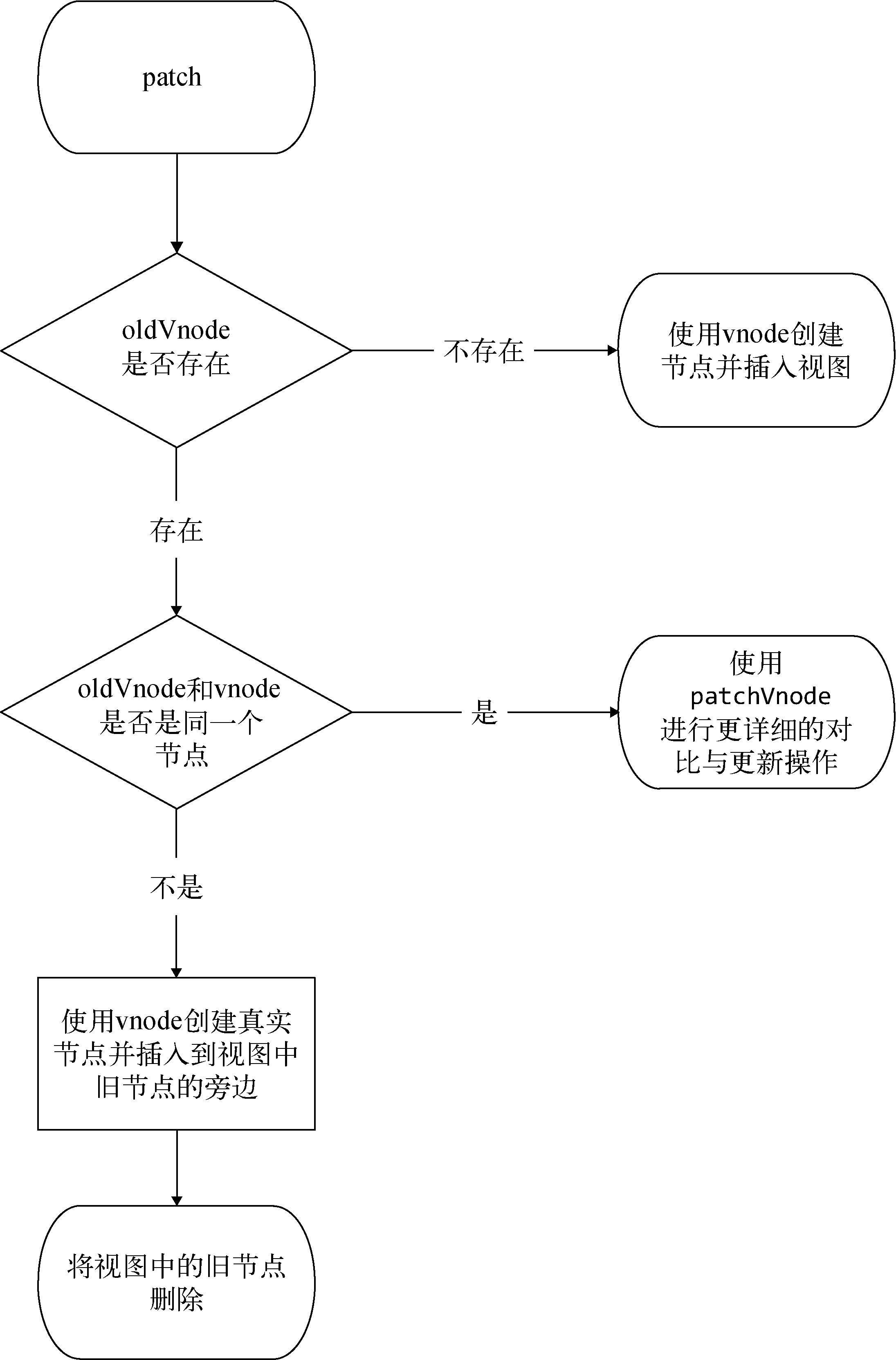
首先,新增节点的一个很明显的场景就是,当oldVnode不存在而vnode存在时,就需要使用vnode生成真实的DOM元素并将其插入到视图当中去。
- **1、这通常会发生在首次渲染中。**因为首次渲染时,DOM中不存在任何节点,所以oldVnode是不存在的。
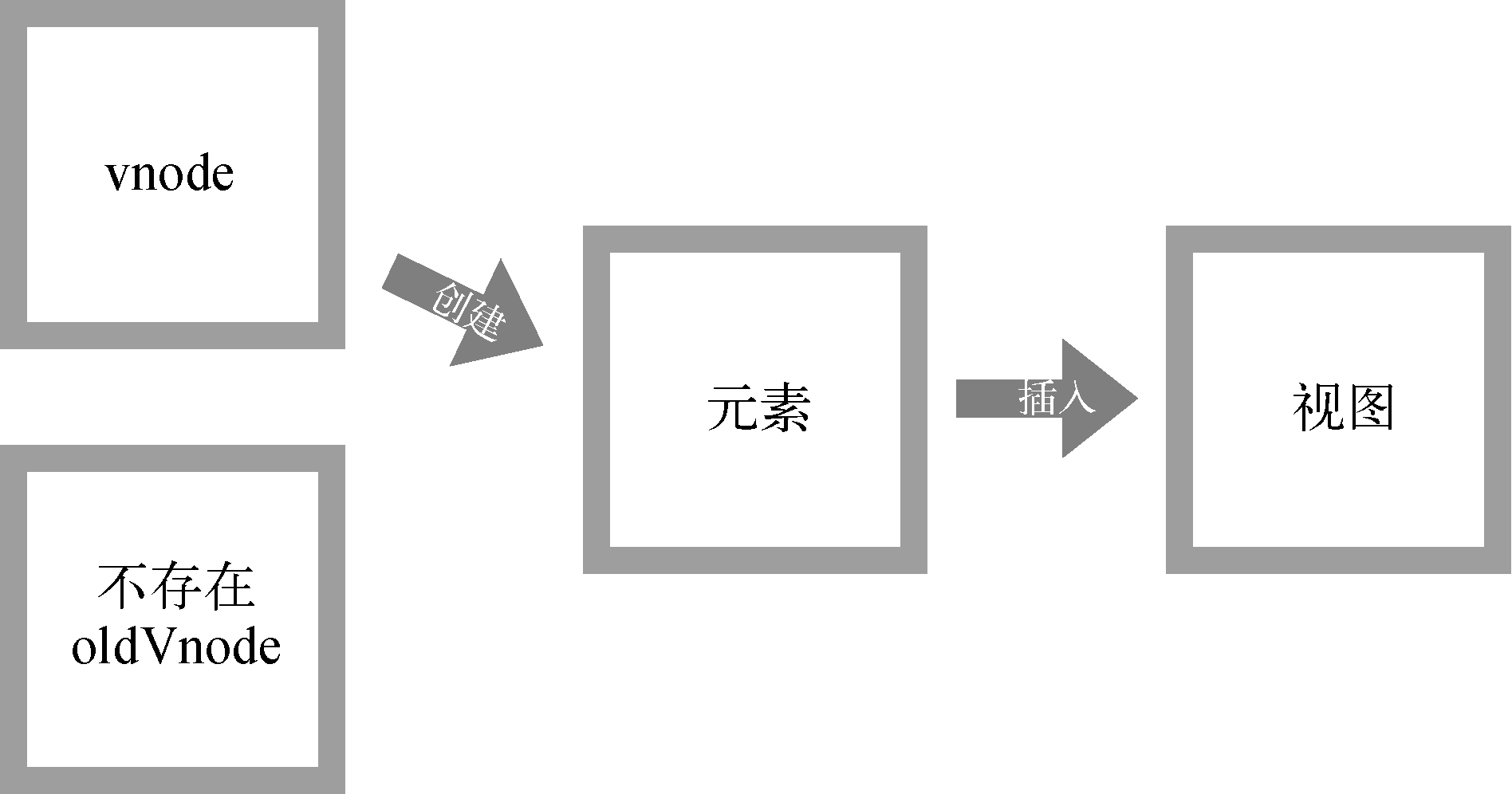
- **2、还有一种情况也需要新增节点。**当vnode和oldVnode完全不是同一个节点时,需要使用vnode生成真实的DOM元素并将其插入到视图当中。
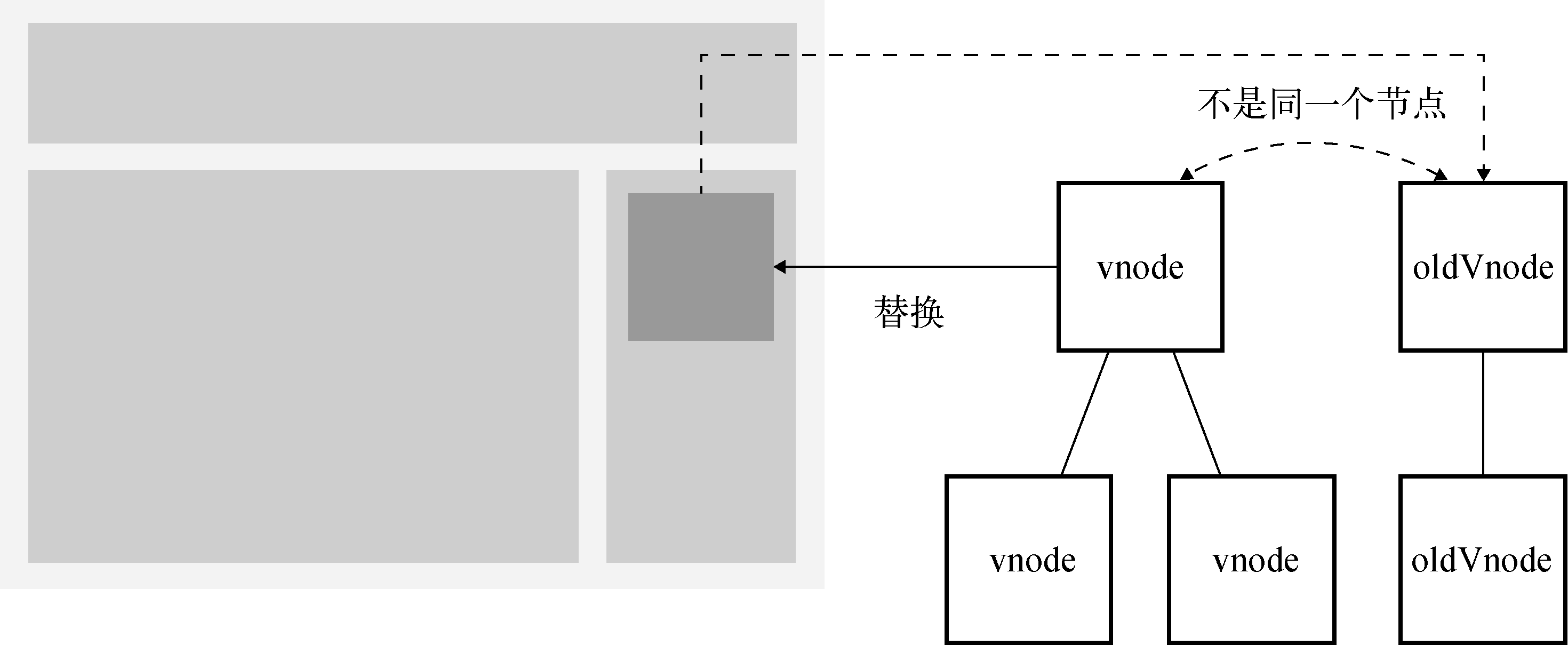
3.1.2 删除节点
就是当一个节点只在oldVnode中存在时,我们需要把它从DOM中删除。因为渲染视图时,需要以vnode为标准,所以vnode中不存在的节点都属于被废弃的节点,而被废弃的节点需要从DOM中删除。
3.1.3 更新节点
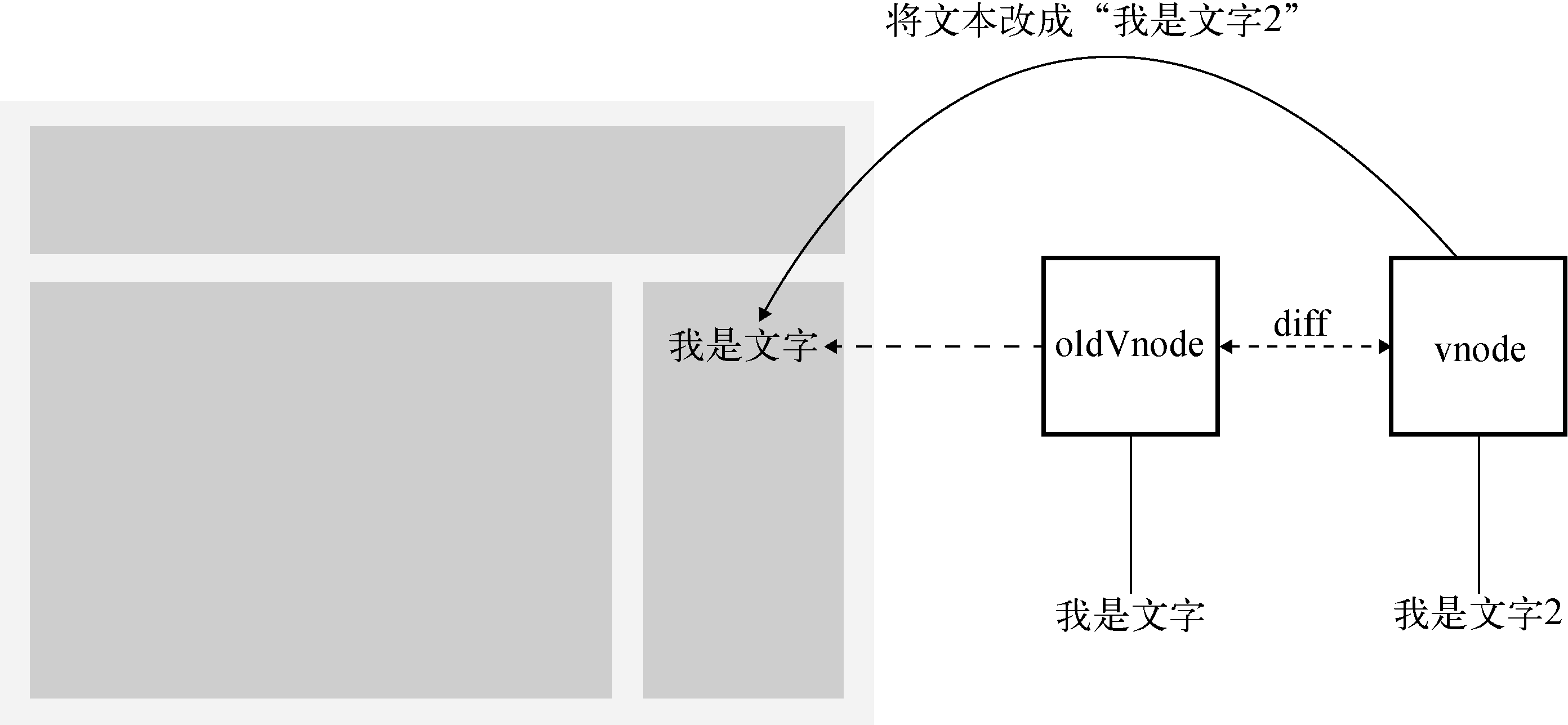
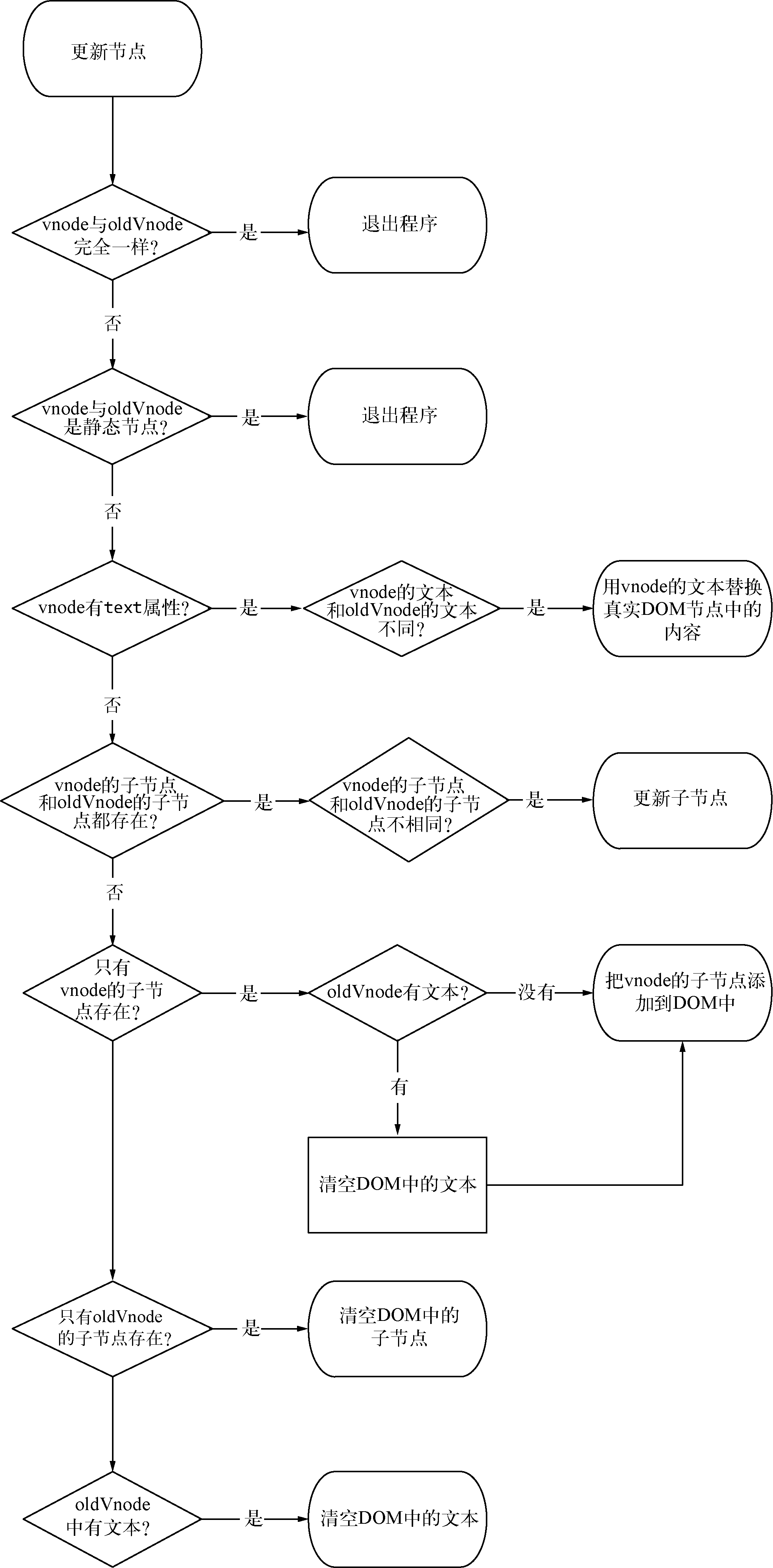
新旧两个节点是同一个节点。当新旧两个节点是相同的节点时,我们需要对这两个节点进行比较细致的比对,然后对oldVnode在视图中所对应的真实节点进行更新。
举个简单的例子,当新旧两个节点是同一个文本节点,但是两个节点的文本不一样时,我们需要重新设置oldVnode在视图中所对应的真实DOM节点的文本。
3.1.4 总结
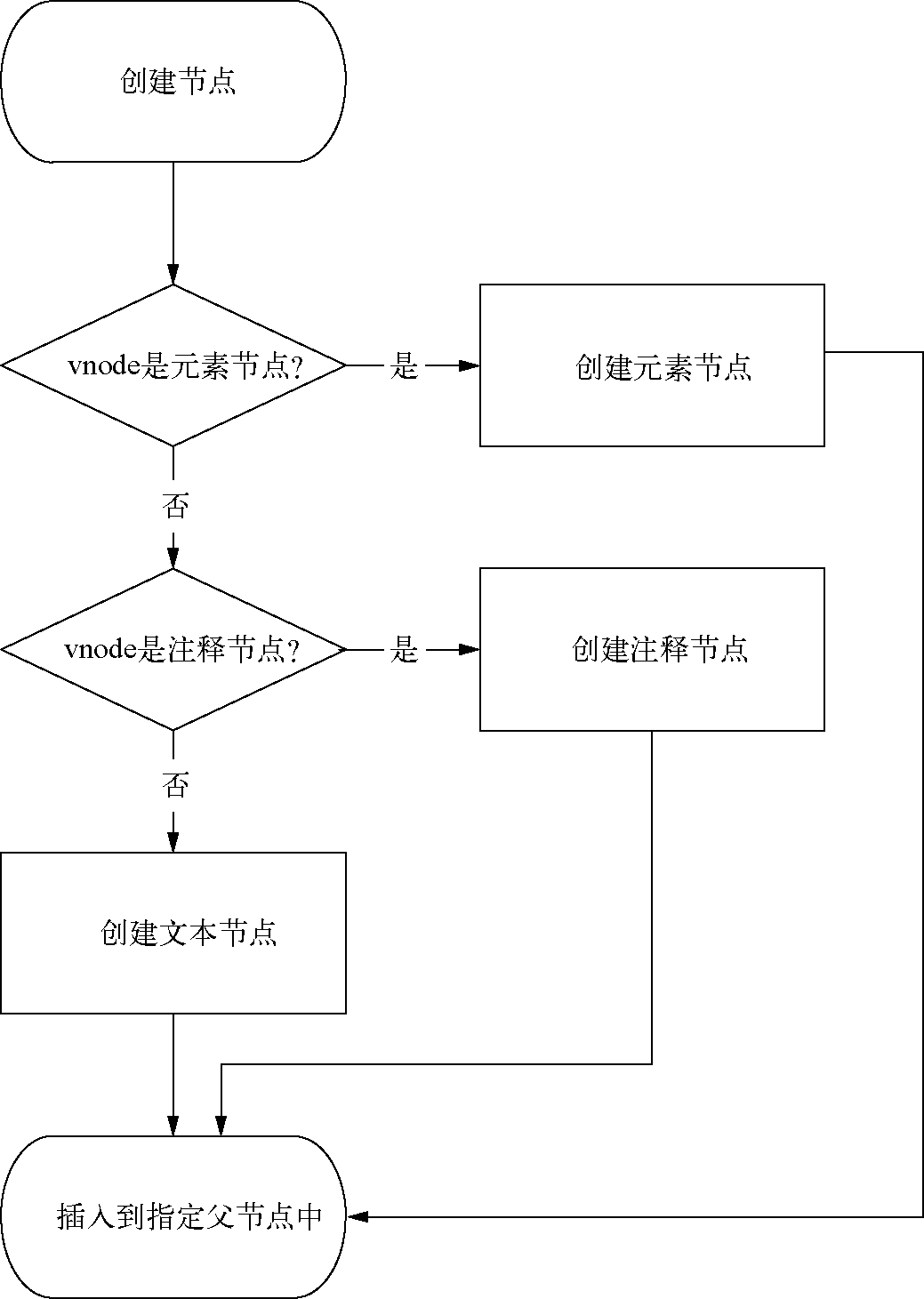
3.2 创建节点
只有三种类型的节点会被创建并插入到DOM中:元素节点、注释节点和文本节点。
创建一个节点并将其渲染到视图的全过程:
3.2 删除节点
1 | // removeVnodes 删除一组指定的节点 |
有同学可能会对nodeOps感到奇怪,为什么不直接使用parent.removeChild(child)删除节点,而是将这个节点操作封装成函数放在nodeOps里呢?
其实这涉及跨平台渲染的知识,我们知道阿里开发的Weex可以让我们使用相同的组件模型为iOS和Android编写原生渲染的应用。也就是说,我们写的Vue.js组件可以分别在iOS和Android环境中进行原生渲染。
**跨平台渲染的本质是在设计框架的时候,要让框架的渲染机制和DOM解耦。**只要把框架更新DOM时的节点操作进行封装,就可以实现跨平台渲染,在不同平台下调用节点的操作。
如果我们把这些平台下节点操作的封装看成渲染引擎,那么将这些渲染引擎所提供的节点操作的API和框架的运行时对接一下,就可以实现将框架中的代码进行原生渲染的目的。
3.3 更新节点
只有两个节点是同一个节点时,才需要更新元素节点,而更新节点并不是很暴力地使用新节点覆盖旧节点,而是通过比对找出新旧两个节点不一样的地方,针对那些不一样的地方进行更新。
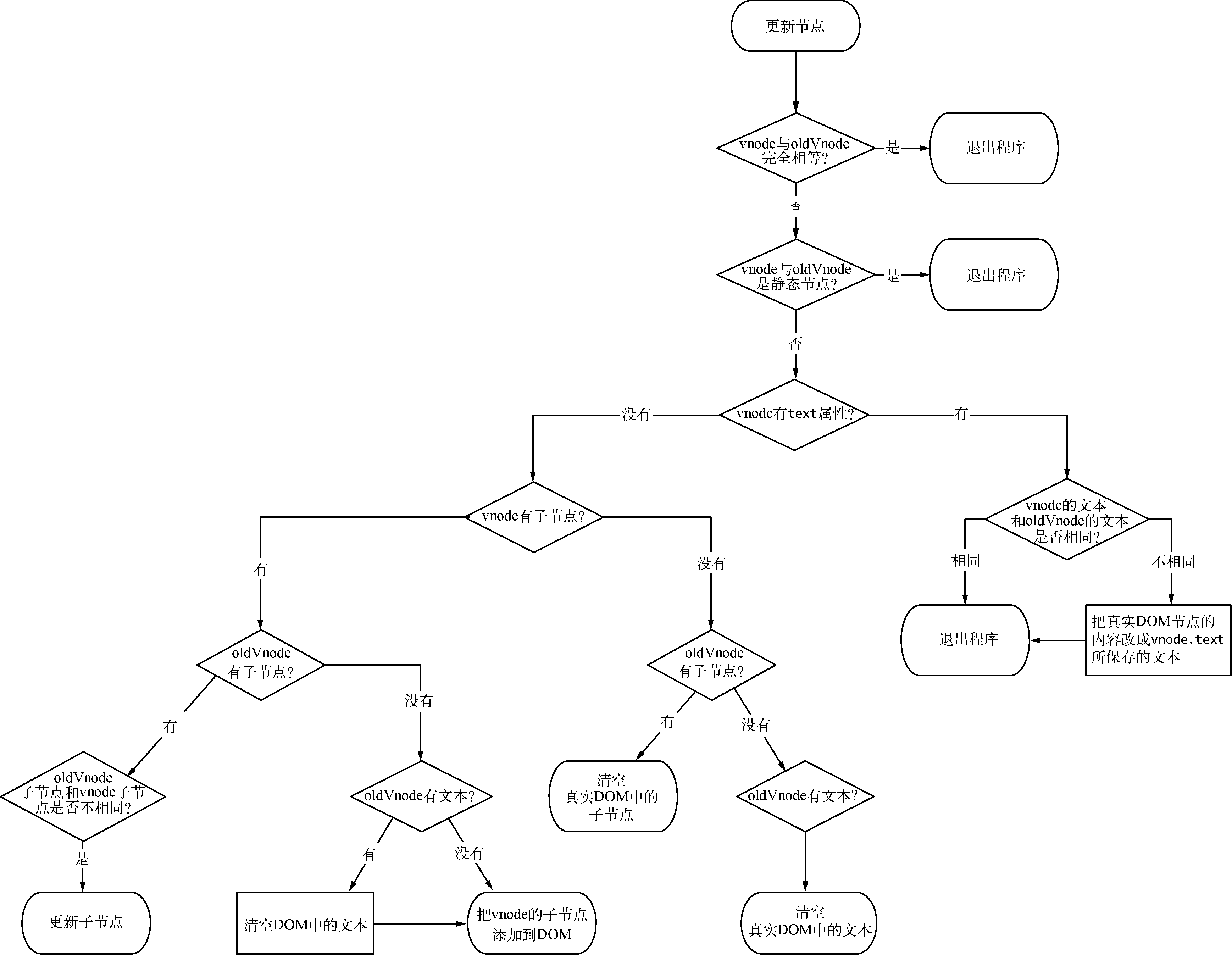
3.3.1 静态节点
在更新节点时,首先需要判断新旧两个虚拟节点是否是静态节点,如果是,就不需要进行更新操作,可以直接跳过更新节点的过程。
静态节点指的是那些一旦渲染到界面上之后,无论日后状态如何变化,都不会发生任何变化的节点。
1 | <span>我是静态节点,我不需要改变</span> |
3.3.2 新虚拟节点有文本属性
当新旧两个虚拟节点(vnode和oldVnode)不是静态节点,并且有不同的属性时,要以新虚拟节点(vnode)为准来更新视图。根据新节点(vnode)是否有text属性,更新节点可以分为两种不同的情况。
简单来说,就是当新虚拟节点有文本属性,并且和旧虚拟节点的文本属性不一样时,我们可以直接把视图中的真实DOM节点的内容改成新虚拟节点的文本。
3.3.3 新虚拟节点无文本属性
如果新创建的虚拟节点没有text属性,那么它就是一个元素节点。元素节点通常会有子节点,也就是children属性,但也有可能没有子节点,所以存在两种不同的情况。
一种情况,有children情况
a、如果旧虚拟节点也有children属性,那么我们要对新旧两个虚拟节点的children进行一个更详细的对比并更新。b、如果旧虚拟节点没有children属性,那么说明旧虚拟节点要么是一个空标签,要么是有文本的文本节点。
二种情况,无children情况
当新创建的虚拟节点既没有text属性也没有children属性时,这说明这个新创建的节点是一个空节点,它下面既没有文本也没有子节点,这时如果旧虚拟节点(oldVnode)中有子节点就删除子节点,有文本就删除文本。有什么删什么,最后达到视图中是空标签的目的。
3.3.4 总结
3.4 更新子节点策略
之前我们详细讨论了更新节点的过程,其中讨论了当新节点的子节点和旧节点的子节点都存在并且不相同时,会进行子节点的更新操作。但我们并没有详细讨论子节点是如何更新的。
更新子节点大概可以分为4种操作:更新节点、新增节点、删除节点、移动节点位置。
3.4.1 创建子节点
最上面的DOM节点是视图中的真实DOM节点。左下角的节点是新创建的虚拟节点。 右下角的节点是旧的虚拟节点。
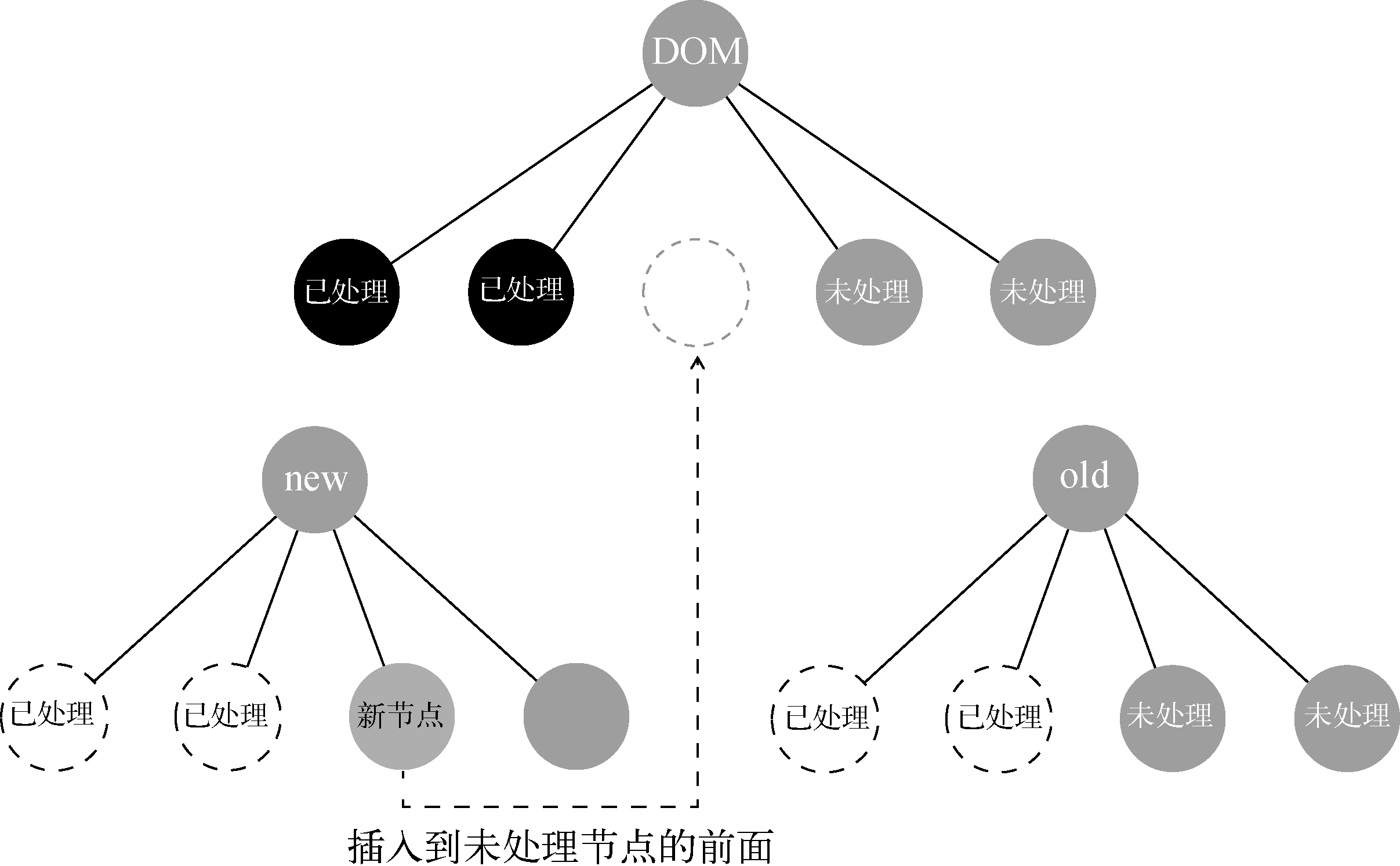
上图已经对前两个子节点进行了更新,当前正在处理第三个子节点。当在右下角的虚拟子节点中找不到与左下角的第三个节点相同的节点时,证明它是新增节点,这时候需要创建节点并插入到真实DOM中,插入的位置是所有未处理节点的前面,也就是虚线所指定的位置。
下图插入到未处理节点的前面:
下图插入到已处理节点的后面: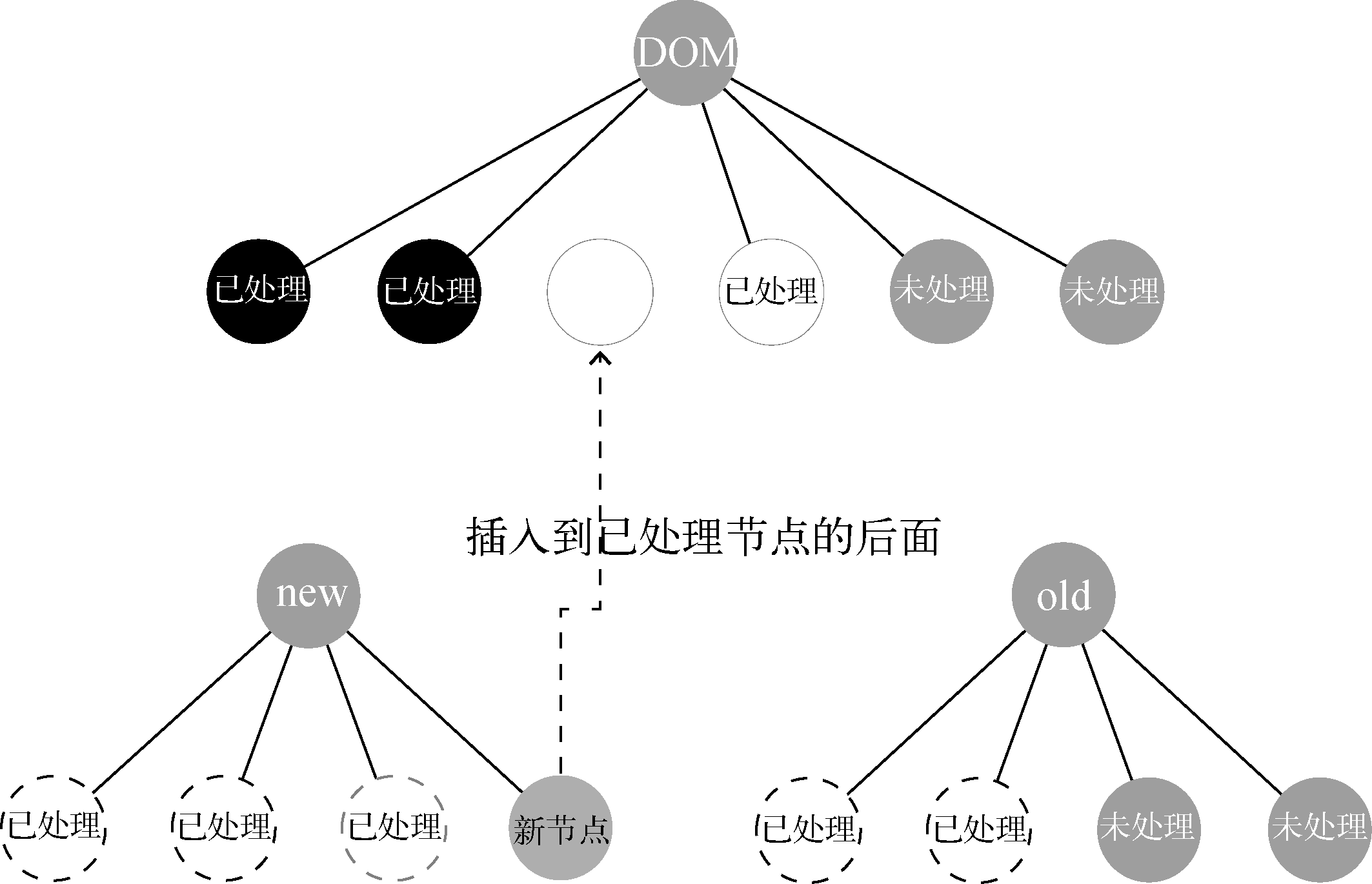
可能你现在又有疑问了,节点插入进真实DOM中后,真实DOM中的节点越来越多,为什么没看见删除节点的逻辑? 关于删除节点的逻辑,我们将在后面详细介绍
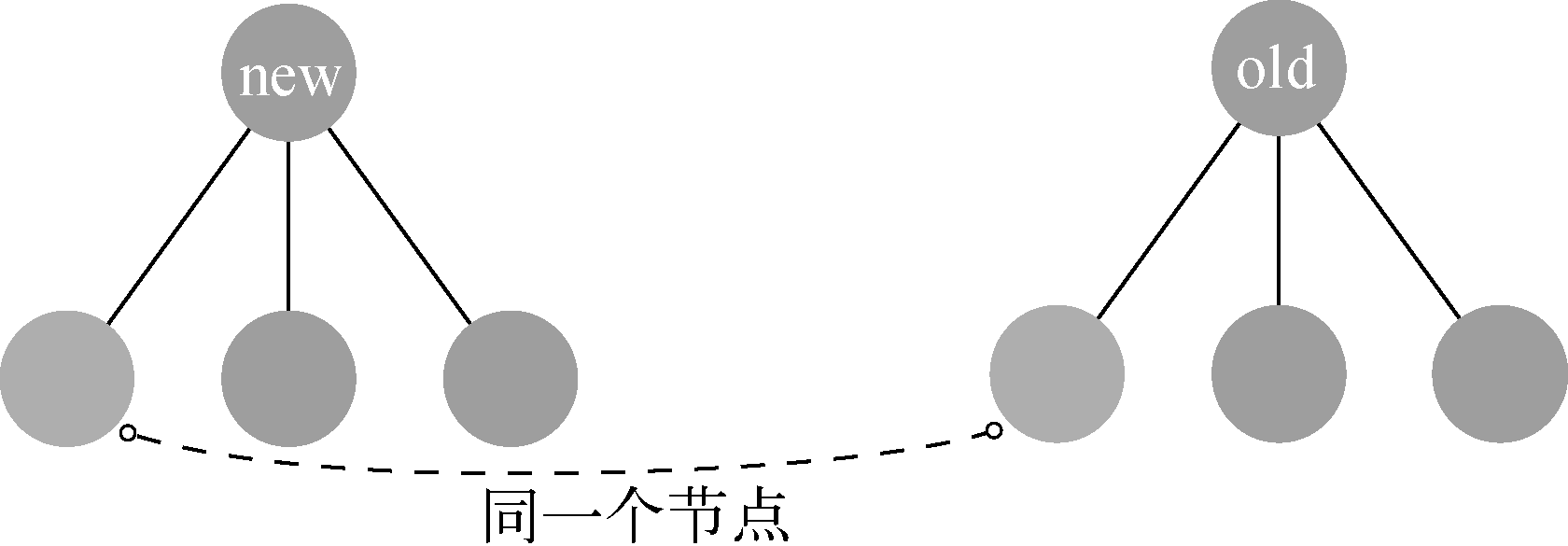
3.4.2 更新子节点
两个节点是同一个节点并且位置相同,这种情况下只需要进行更新节点的操作即可
3.4.3 移动子节点
移动节点通常发生在newChildren中的某个节点和oldChildren中的某个节点是同一个节点,但是位置不同,所以在真实的DOM中需要将这个节点的位置以新虚拟节点的位置为基准进行移动。
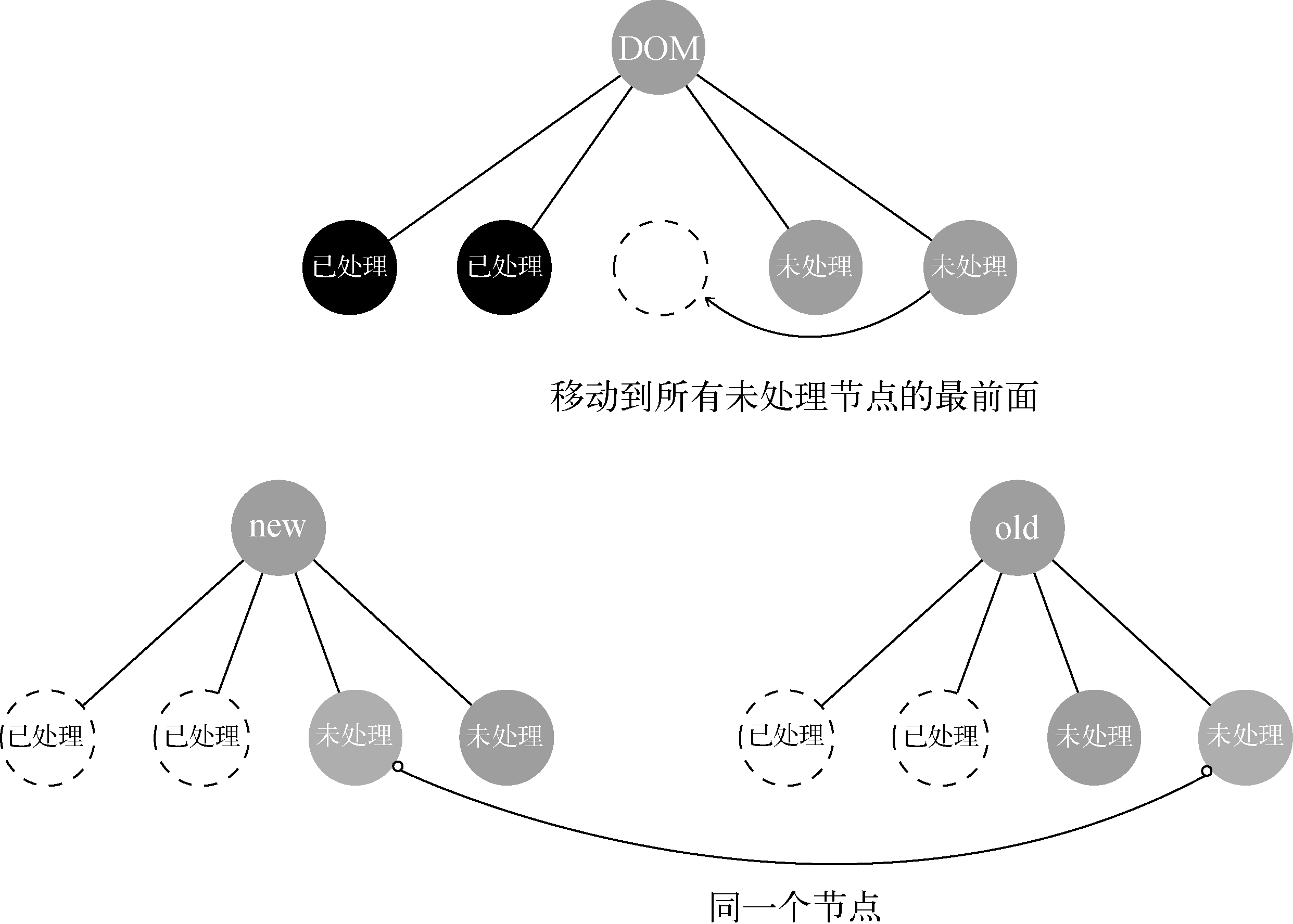
上图表示正在处理第三个节点,这时在oldChildren中找到的相同节点是第四个节点。由于位置不同,所以需要移动节点,移动节点的位置是所有未处理节点的最前面。本例中,将第四个节点移动到所有未处理节点的最前面,就是将节点从第四个变成了第三个。
节点更新并且移动完位置后,开始进行下一轮循环,也就是开始处理newChildren中的第四个节点。
关于怎么分辨哪些节点是处理过的,哪些节点是未处理的,我们将在后面章节详细讨论
3.4.4 删除子节点
删除子节点,本质上是删除那些oldChildren中存在但newChildren中不存在的节点
当newChildren中的所有节点都被循环了一遍后,也就是循环结束后,如果oldChildren中还有剩余的没有被处理的节点,那么这些节点就是被废弃、需要删除的节点。
3.4.5 优化策略
通常情况下,并不是所有子节点的位置都会发生移动,一个列表中总有几个节点的位置是不变的。针对这些位置不变的或者说位置可以预测的节点,我们不需要循环来查找,因为我们有一个更快捷的查找方式
只需要尝试使用相同位置的两个节点来比对是否是同一个节点:如果恰巧是同一个节点,直接就可以进入更新节点的操作;如果尝试失败了,再用循环的方式来查找节点。
这样做可以很大程度地避免循环oldChildren来查找节点,从而使执行速度得到很大的提升。
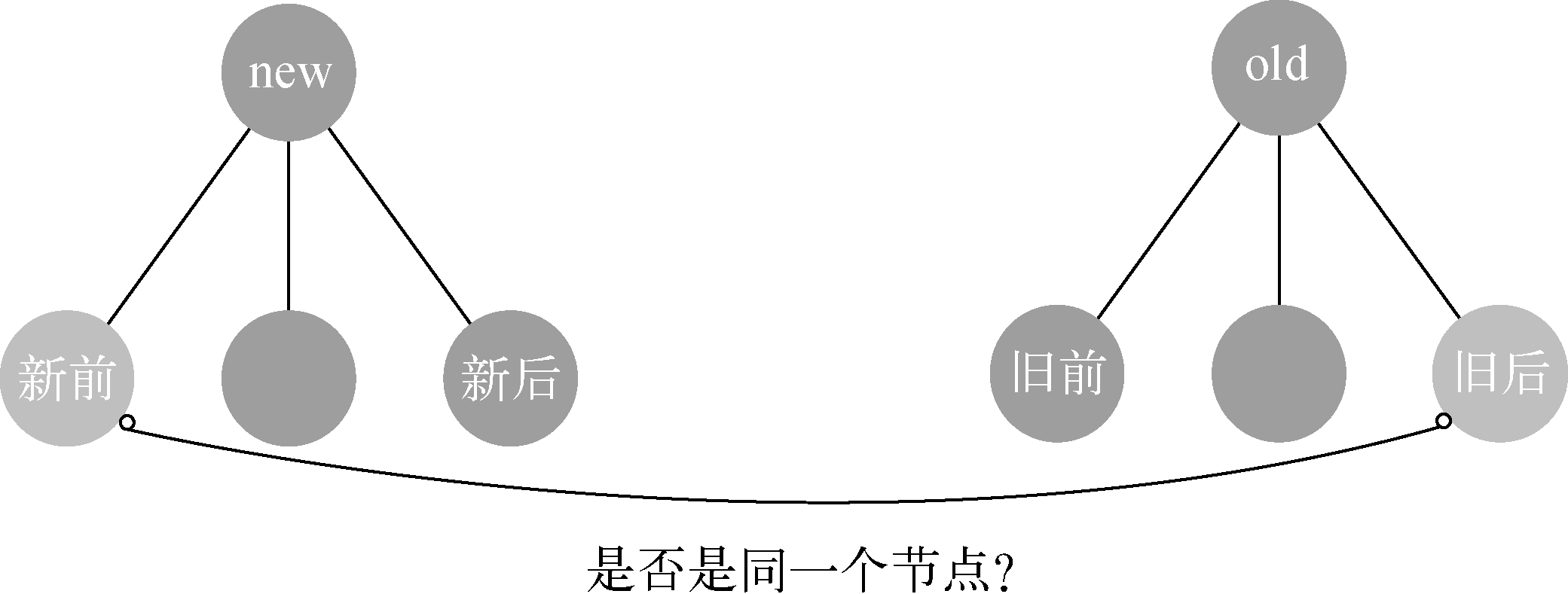
如果我们把这种很快速的查找节点的方式称为快捷查找,那么它共有4种查找方式,分别是:
- 新前(newChildren中所有未处理的第一个节点)与 旧前(oldChildren中所有未处理的第一个节点)
- 新后(newChildren中所有未处理的最后一个节点)与 旧后(oldChildren中所有未处理的最后一个节点)
- 新后 与 旧前
- 新前 与 旧后
1、新前和旧前
顾名思义,“新前”与“旧前”的意思就是尝试使用“新前”这个节点与“旧前”这个节点对比,对比它们俩是不是同一个节点。如果是同一个节点,则说明我们不费吹灰之力就在oldChildren中找到了这个虚拟节点,然后使用7.4节中介绍的更新节点操作将它们俩进行对比并更新视图
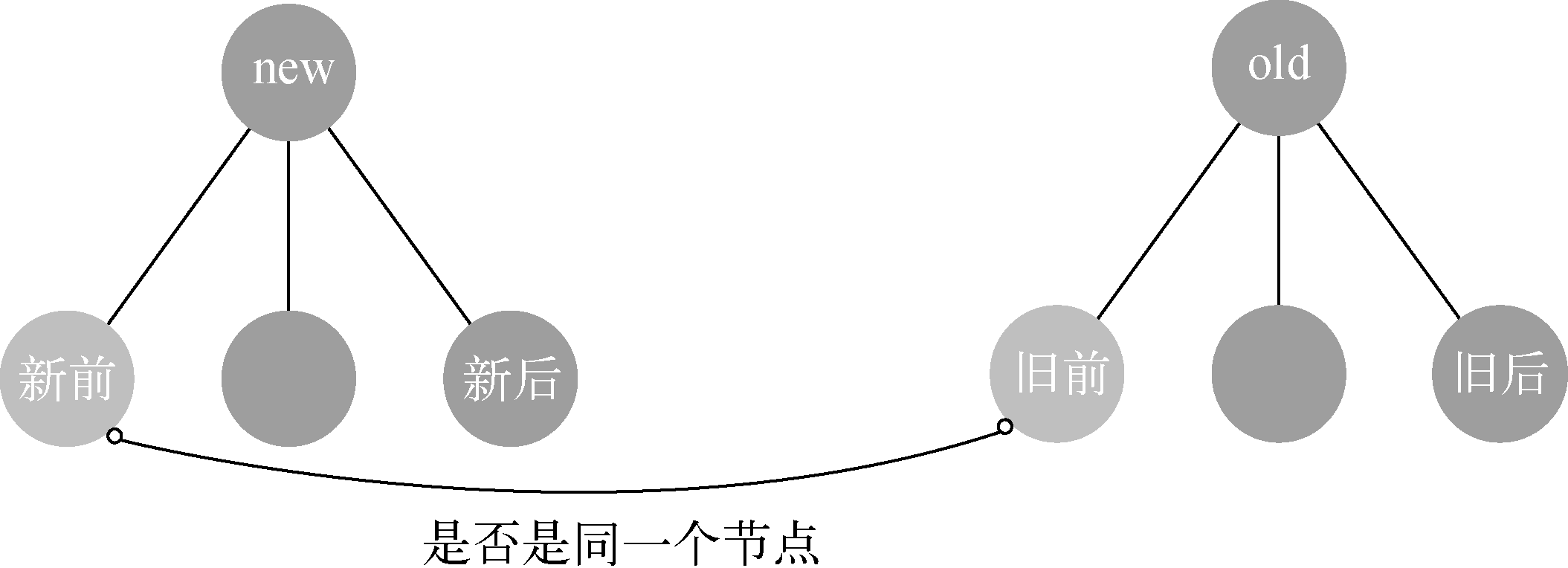
由于“新前”与“旧前”的位置相同,所以并不需要执行移动节点的操作,只需要更新节点即可。
2、新后和旧后
当“新前”与“旧前”对比后发现不是同一个节点,这时可以尝试用“新后”与“旧后”的方式来比对它们俩是否是同一个节点。
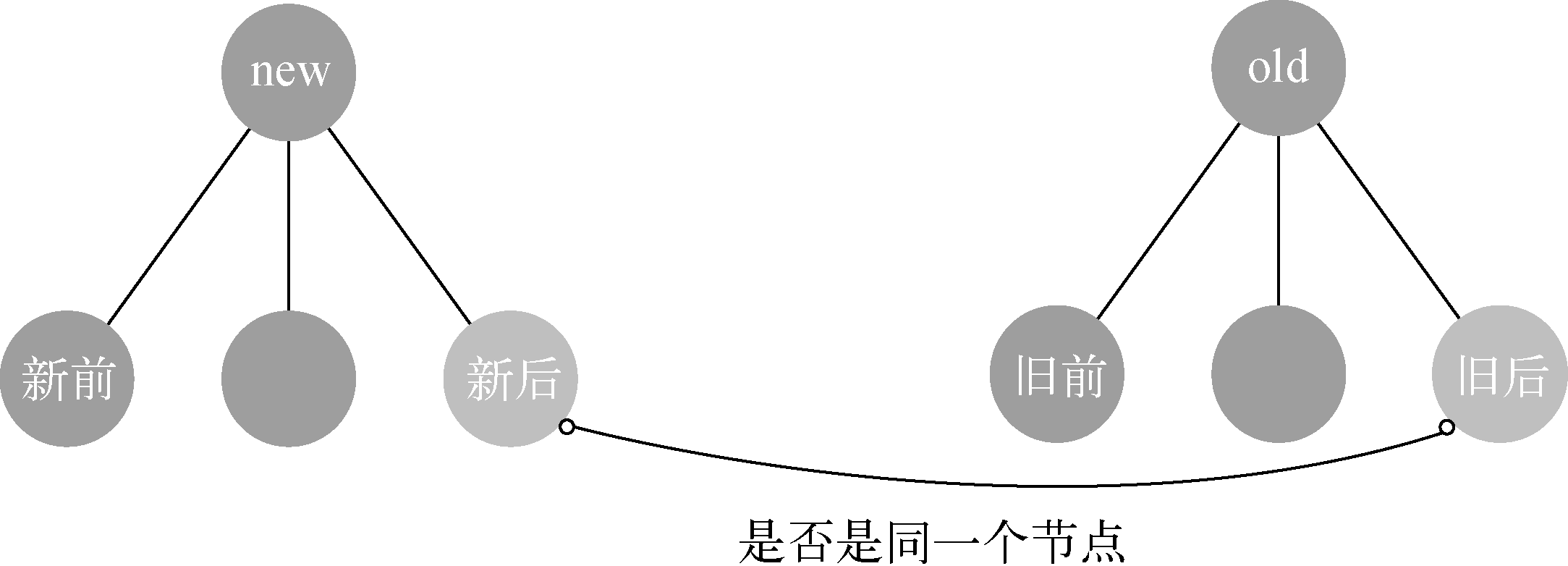
由于“新后”与“旧后”这两个节点的位置相同,所以只需要执行更新节点的操作即可,不需要执行移动节点的操作。
3、新后和旧前
“新后”与“旧前”的意思是使用“新后”这个节点与“旧前”这个节点进行对比,通过对比来分辨它们俩是不是同一个节点。如果是同一个节点,就对比它们俩并更新视图:
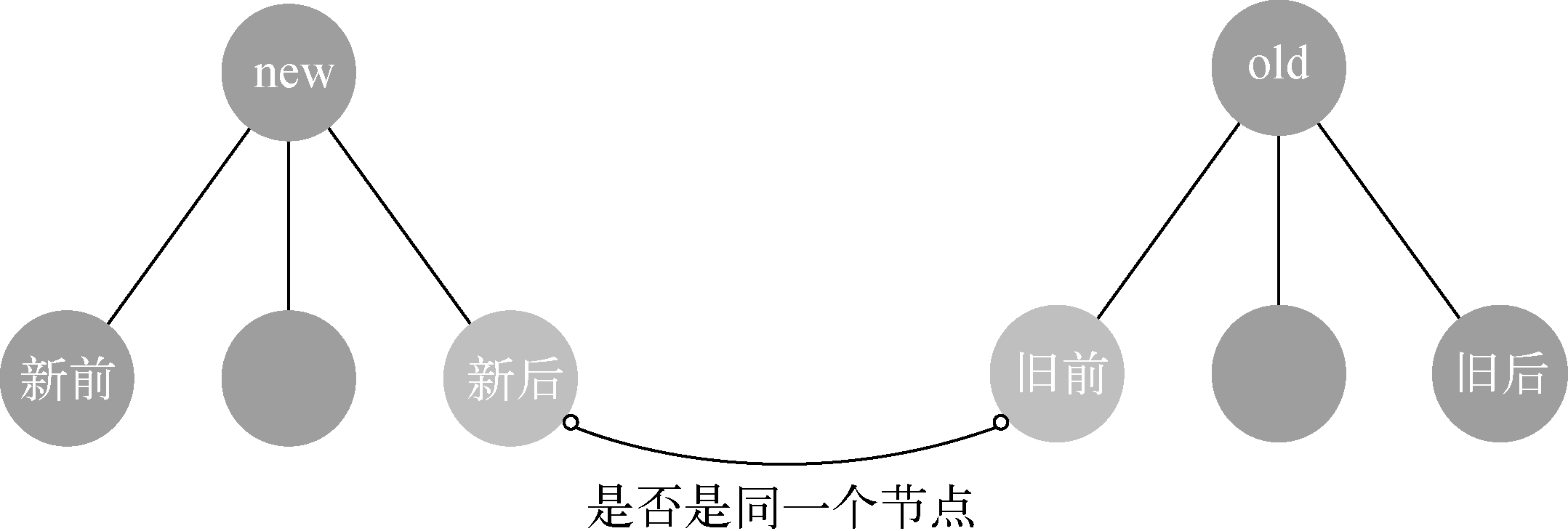
如果“新后”与“旧前”是同一个节点,那么由于它们的位置不同,所以除了更新节点外,还需要执行移动节点的操作:
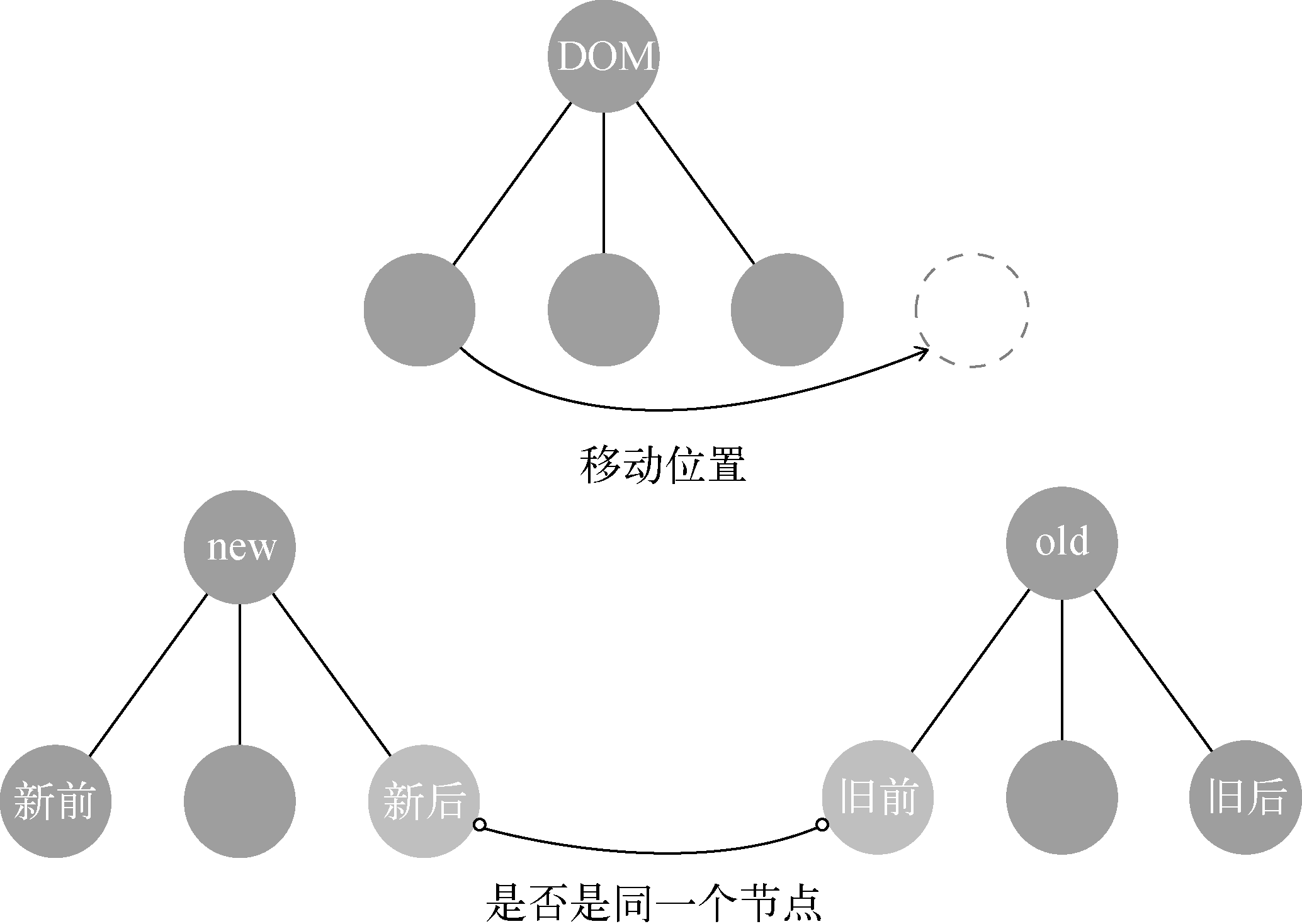
当“新后”与“旧前”是同一个节点时,在真实DOM中除了做更新操作外,还需要将节点移动到oldChildren中所有未处理节点的最后面。
你可能对为什么移动到oldChildren中所有未处理节点的最后面感到困惑,接下来我们会详细介绍为什么移动到这个位置。
更新节点是以新虚拟节点为基准,子节点也不例外,所以在图7-21中,因为“新后”这个节点是最后一个节点,所以真实DOM中将节点移动到最后不难理解,让我们感到困惑的是为什么移动到oldChildren中所有未处理节点的最后面。
这里我们举个例子,如下图:
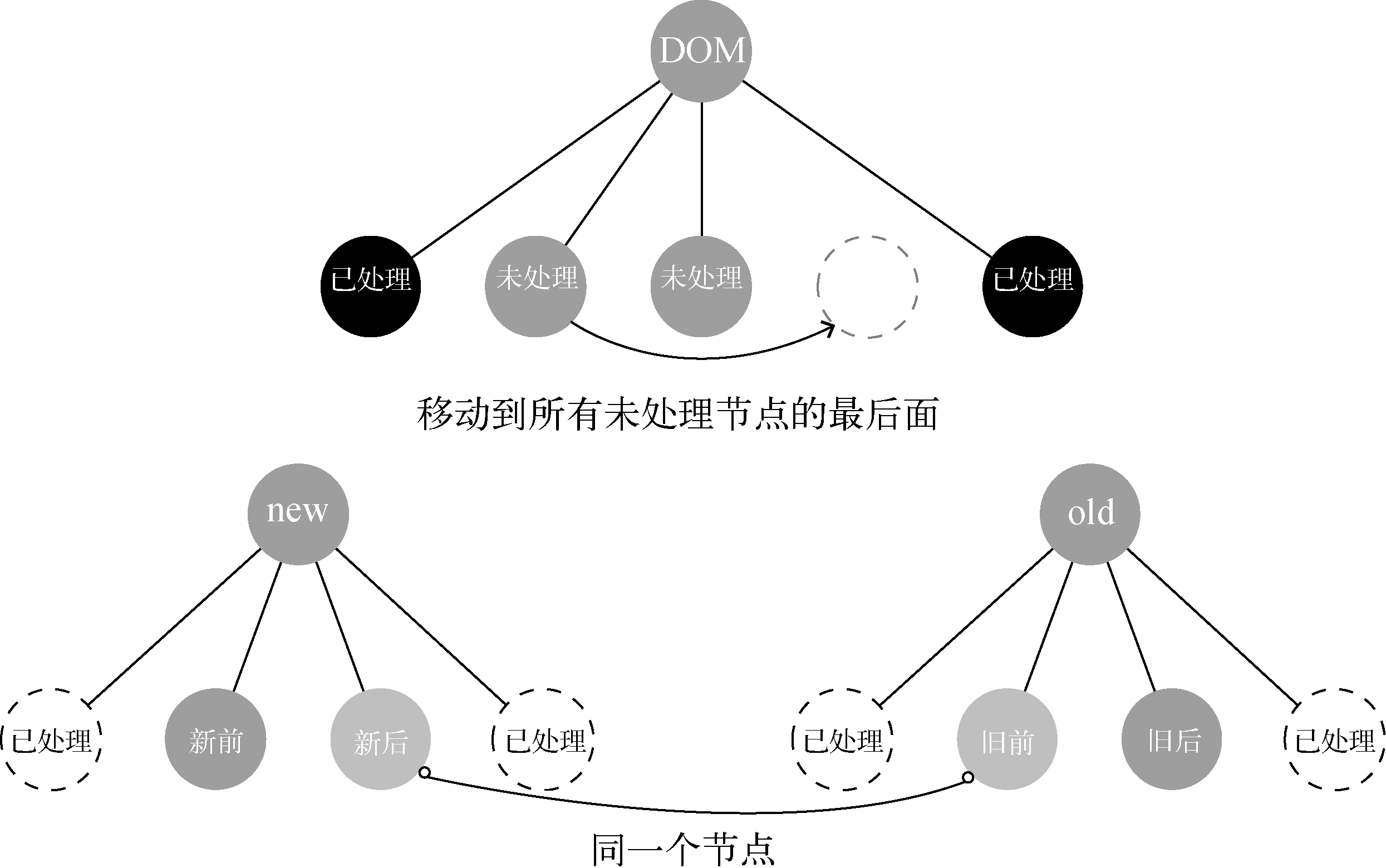
当真实DOM子节点左右两侧已经有节点被更新,只有中间这部分节点未处理时,“新后”这个节点是未处理节点中的最后一个节点,所以真实DOM节点移动位置时,需要移动到oldChildren中所有未处理节点的最后面。只有移动到未处理节点的最后面,它的位置才与“新后”这个节点的位置相同。
如果对比之后发现这两个节点也不是同一个节点,则继续尝试对比“新前”与“旧后”是否是同一个节点。
4、新前和旧后
“新前”与“旧后”的意思是使用“新前”与“旧后”这两个节点进行对比,对比它们是否是同一个节点,如果是同一个节点,则进行更新节点的操作。
由于“新前”与“旧后”这两个节点的位置不同,所以除了更新节点的操作外,还需要进行移动节点的操作:
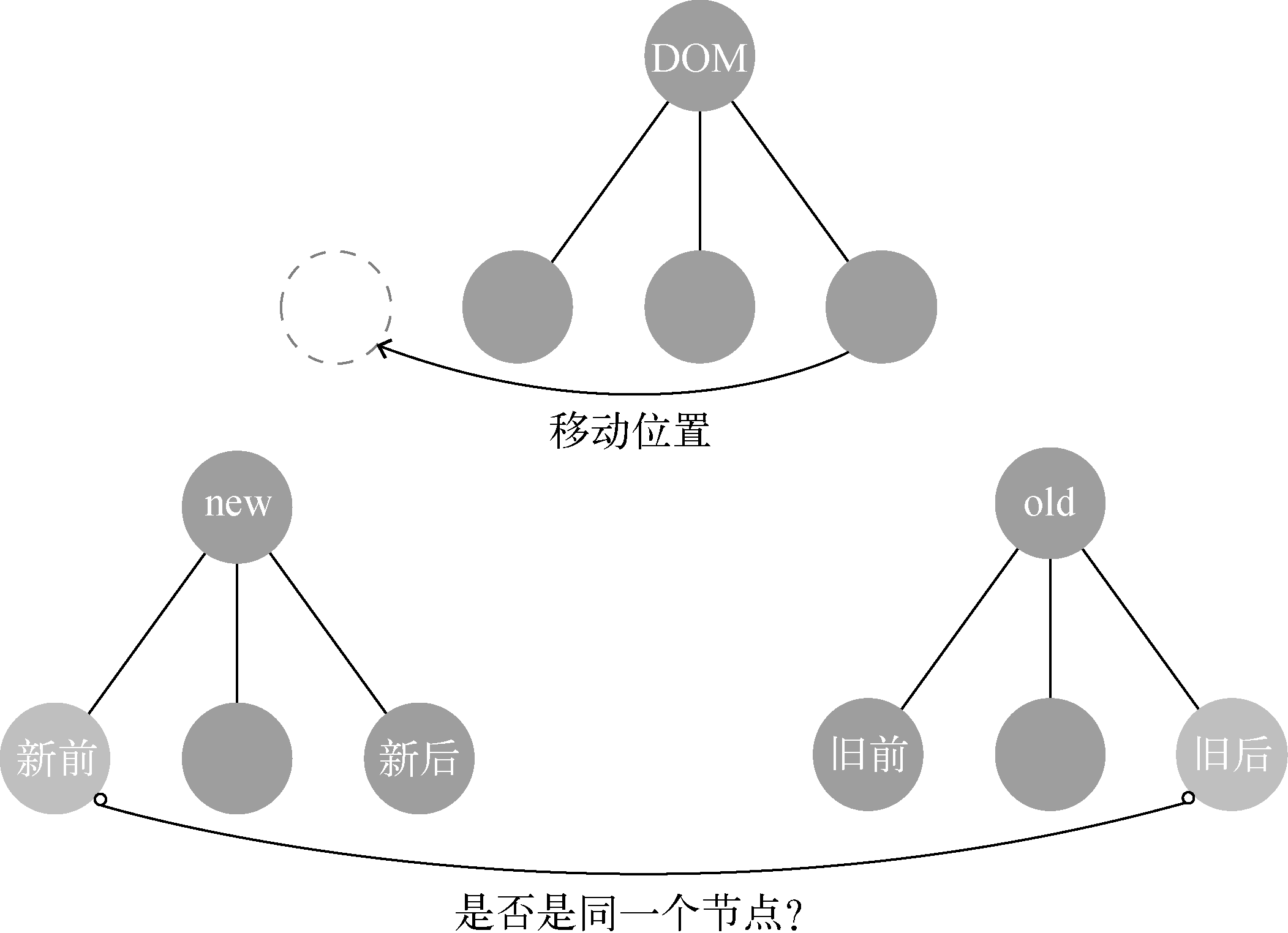
从上图中可以看出,当“新前”与“旧后”是同一个节点时,在真实DOM中除了做更新操作外,还需要将节点移动到oldChildren中所有未处理节点的最前面。
将节点移动到oldChildren中所有未处理节点的最前面的原因,与前面介绍的“新后”与“旧前”的逻辑是一样的, 如下图:
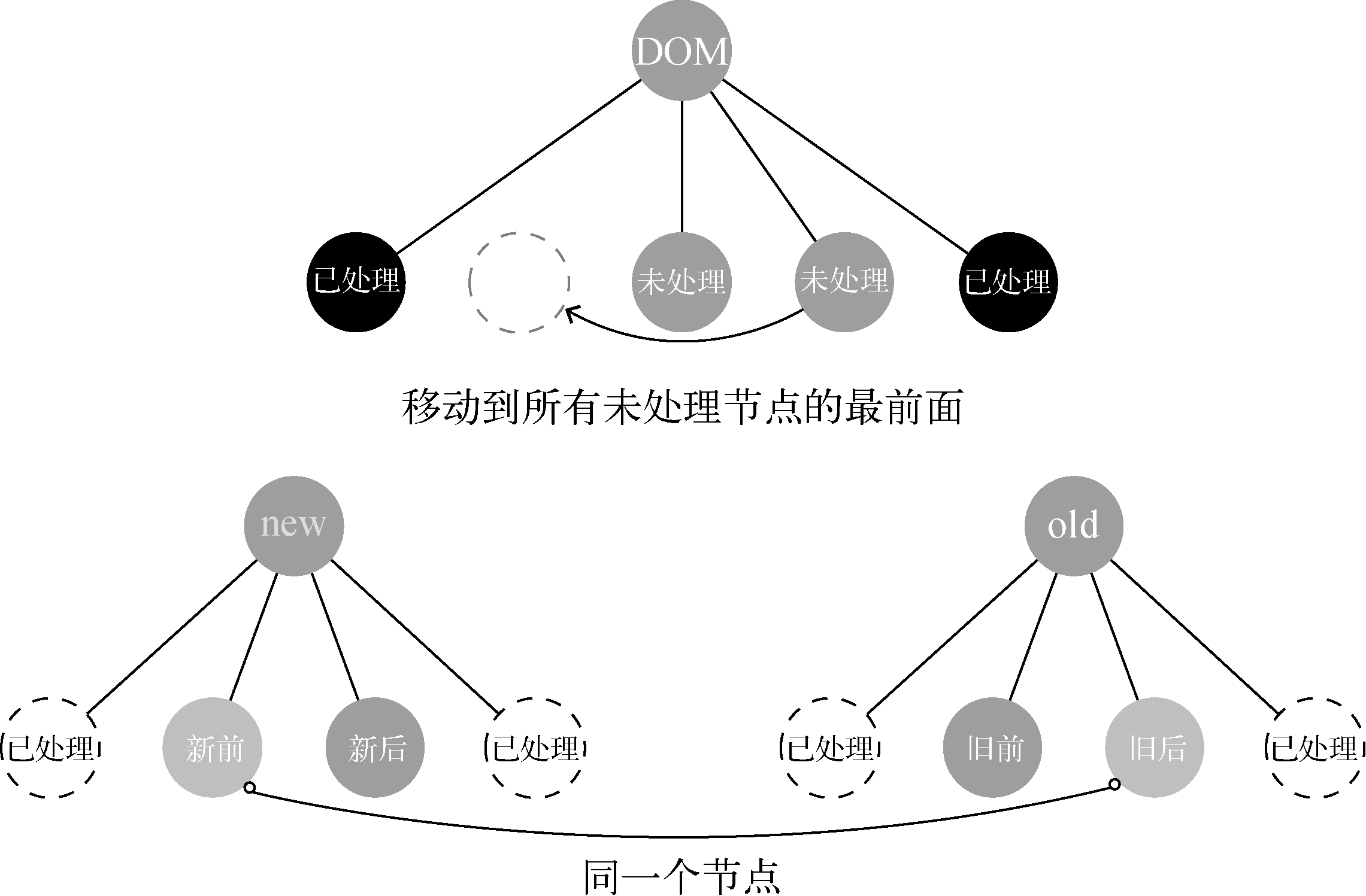
如上图所示,当真实的DOM节点中已经有节点被更新,并且更新到第二个节点时,我们发现oldChildren中对应的节点在第三个的位置上,这时需要将“旧后”这个节点更新并移动到第二个的位置上,所以只需要将节点移动到所有未处理节点的最前面,就能实现移动到第二个位置的目的。
也就是说,已更新过的节点都不用管。因为更新过的节点无论是节点的内容或者节点的位置,都是正确的,更新完后面就不需要再进行更改了。所以,我们只需要在所有未更新的节点区间内进行移动和更新操作即可。
如果前面这4种方式对比之后都没找到相同的节点,这时再通过循环的方式去oldChildren中详细找一圈,看看能否找到。
大部分情况下,通过前面这4种方式就可以找到相同的节点,所以节省了很多次循环操作。
5、哪些节点是未处理过的
那么,怎样实现从两边向中间循环呢?
首先,我们先准备4个变量:oldStartIdx、oldEndIdx、newStartIdx和newEndIdx。
这4个变量分别表示oldChildren的开始位置的下标(oldStartIdx)和结束位置的下标(oldEndIdx),以及newChildren的开始位置的下标(newStartIdx)和结束位置的下标(newEndIdx)。
在循环体内,每处理一个节点,就将下标向指定的方向移动一个位置,通常情况下是对新旧两个节点进行更新操作,就相当于一次性处理两个节点,将新旧两个节点的下标都向指定方向移动一个位置。
当开始位置大于等于结束位置时,说明所有节点都遍历过了,则结束循环:
1 | while(oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx){ |
6、小结
更新子节点的整体流程:
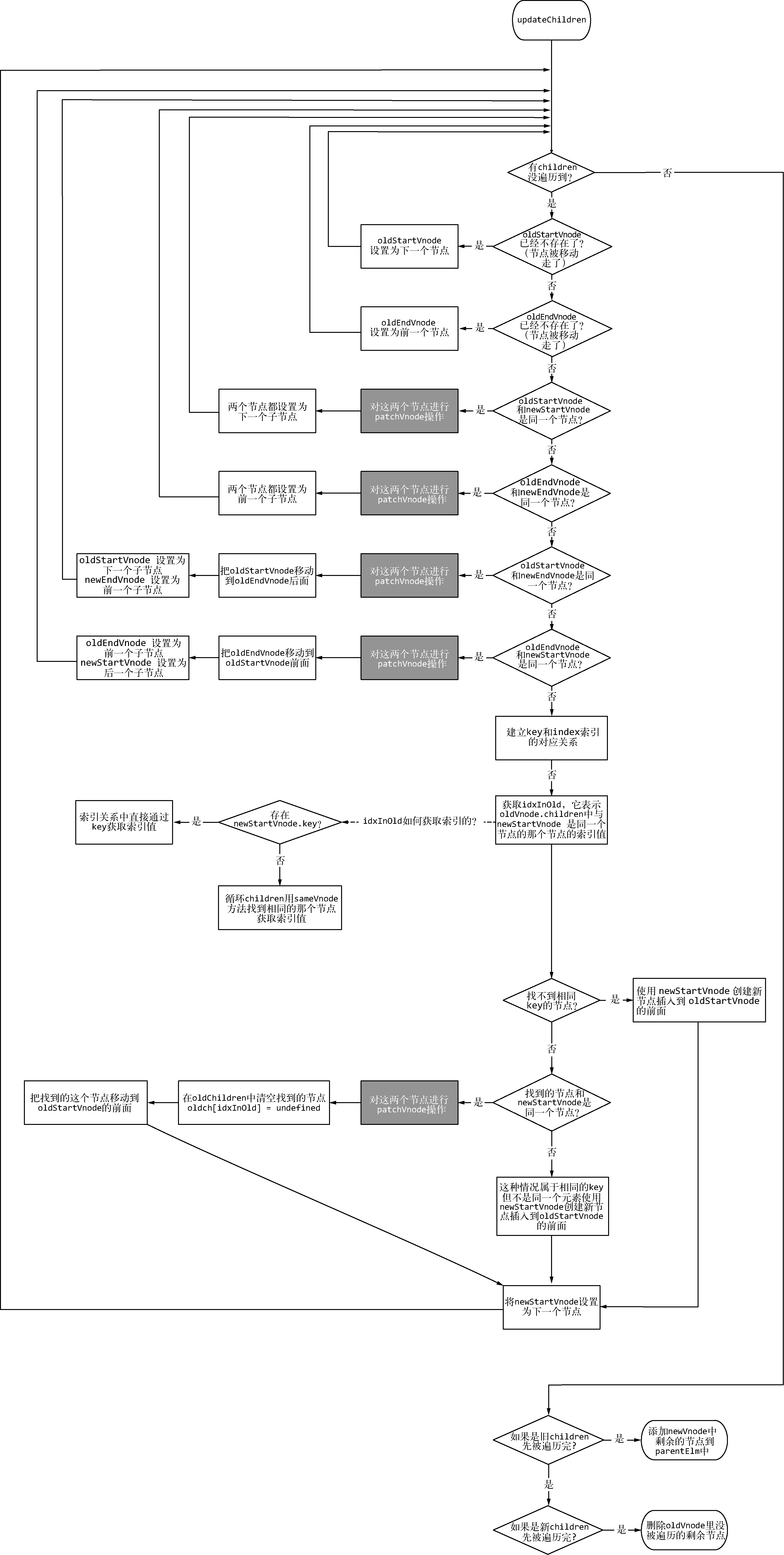
名称解释:
- oldStartVnode:oldChildren中所有未处理的第一个节点,与前文中提到的“旧前”是同一个节点。
- oldEndVnode:oldChildren中所有未处理的最后一个节点,与前文中提到的“旧后”是同一个节点。
- newStartVnode:newChildren中所有未处理的第一个节点,与前文中提到的“新前”是同一个节点。
- newEndVnode:newChildren中所有未处理的最后一个节点,与前文中提到的“新后”是同一个节点。
在Vue.js的模板中,渲染列表时可以为节点设置一个属性key,这个属性可以标示一个节点的唯一ID。Vue.js官方非常推荐在渲染列表时使用这个属性,我也非常推荐使用它,为什么呢?
在更新子节点时,需要在oldChildren中循环去找一个节点。但是如果我们在模板中渲染列表时,为子节点设置了属性key,那么在上图中建立key与index索引的对应关系时,就生成了一个key对应着一个节点下标这样一个对象。也就是说,如果在节点上设置了属性key,那么在oldChildren中找相同节点时,可以直接通过key拿到下标,从而获取节点。这样,我们根本不需要通过循环来查找节点。
3.4.6 总结
本章中,我们介绍了虚拟DOM中最关键的部分:patch。
通过patch可以对比新旧两个虚拟DOM,从而只针对发生了变化的节点进行更新视图的操作。本章详细介绍了如何对比新旧两个节点以及更新视图的过程。
5、模板编译
1、介绍
我们平时使用Vue.js进行开发时,会经常使用模板。模板赋予我们很多强大的能力,例如可以在模板中访问变量。
但在Vue.js中创建HTML并不是只有模板这一种途径,我们既可以手动写渲染函数来创建HTML,也可以在Vue.js中使用JSX来创建HTML。
**渲染函数是创建HTML最原始的方法。模板最终会通过编译转换成渲染函数,渲染函数执行后,会得到一份vnode用于虚拟DOM渲染。所以模板编译其实是配合虚拟DOM进行渲染,**这也是本书先介绍虚拟DOM后介绍模板编译的原因。
2、模板编译原理
模板编译在整个渲染过程中的位置:

Vue.js提供了模板语法,允许我们声明式地描述状态和DOM之间的绑定关系,然后通过模板来生成真实DOM并将其呈现在用户界面上。
在底层实现上,Vue.js会将模板编译成虚拟DOM渲染函数。当应用内部的状态发生变化时,Vue.js可以结合响应式系统,聪明地找出最小数量的组件进行重新渲染以及最少量地进行DOM操作。
2.1 概念
模板编译的主要目标就是生成渲染函数,如下图所示。而渲染函数的作用是每次执行它,它就会使用当前最新的状态生成一份新的vnode,然后使用这个vnode进行渲染。

2.2 模板编译 –> 渲染函数
将模板编译成渲染函数可以分两个步骤,先将模板解析成AST(Abstract Syntax Tree,抽象语法树),然后再使用AST生成渲染函数。
但是由于静态节点不需要总是重新渲染,所以在生成AST之后、生成渲染函数之前这个阶段,需要做一个操作,那就是遍历一遍AST,给所有静态节点做一个标记,这样在虚拟DOM中更新节点时,如果发现节点有这个标记,就不会重新渲染它。
所以,在大体逻辑上,模板编译分三部分内容:
- 将模板解析为AST –> 解析器
- 遍历AST标记静态节点 –> 优化器
- 使用AST生成渲染函数 –> 代码生成器
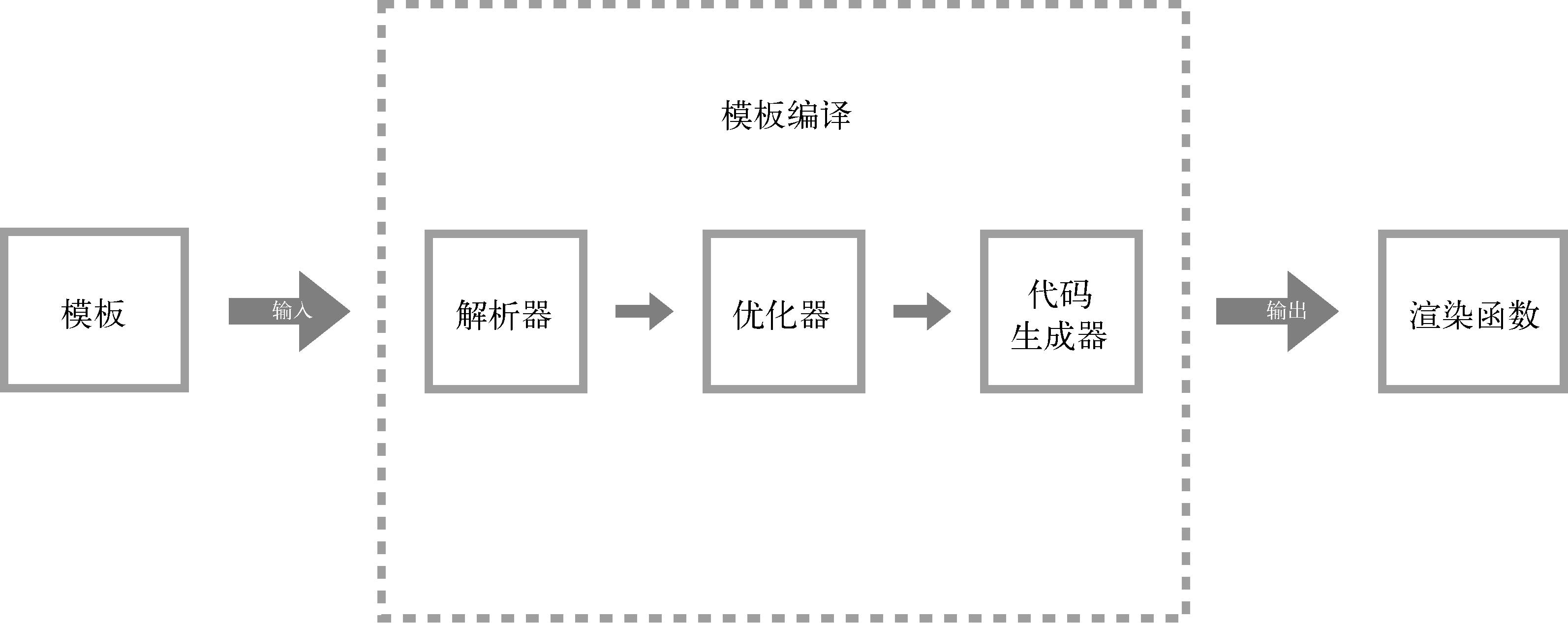
2.3 解析器
解析器的作用前面已经提到过,其目标很明确,只实现一个功能,那就是将模板解析成AST。
在解析器内部,分成了很多小解析器,其中包括过滤器解析器、文本解析器和HTML解析器。然后通过一条主线将这些解析器组装在一起。
AST其实和vnode有点类似,都是使用JavaScript中的对象来表示节点。
2.4 优化器
优化器的目标是遍历AST,检测出所有静态子树(永远都不会发生变化的DOM节点)并给其打标记。
当AST中的静态子树被打上标记后,每次重新渲染时,就不需要为打上标记的静态节点创建新的虚拟节点,而是直接克隆已存在的虚拟节点。在虚拟DOM的更新操作中,如果发现两个节点是同一个节点,正常情况下会对这两个节点进行更新,但是如果这两个节点是静态节点,则可以直接跳过更新节点的流程。
2.5 代码生成器
1、模板
1 | <p title="Brewin" @click="c">1</p> |
2、生成后的代码字符串
1 | `with(this){return _c('p',{attrs:{"title":"Berwin"},on:{"click":c}},[_v("1")])}` |
这样一个代码字符串最终导出到外界使用时,会将代码字符串放到函数里,这个函数叫作渲染函数。
1 | const code = `with(this){return 'Hello Berwin'}` |
渲染函数的作用是创建vnode。渲染函数之所以可以生成vnode,是因为代码字符串中会有很多函数调用(例如,上面生成的代码字符串中有两个函数调用 _c和 _v),这些函数是虚拟DOM提供的创建vnode的方法。vnode有很多种类型,不同的类型对应不同的创建方法,所以代码字符串中的 _c和 _v其实都是创建vnode的方法,只是创建的vnode的类型不同。例如,_c可以创建元素类型的vnode,而 _v可以创建文本类型的vnode。
3、解析器
3.1 解析器作用
解析器要实现的功能是将模板解析成AST。
其实AST并不是什么很神奇的东西,不要被它的名字吓倒。它只是用JavaScript中的对象来描述一个节点,一个对象表示一个节点,对象中的属性用来保存节点所需的各种数据。
1 | <div> |
AST
1 | { |
3.2 解析器内部运行原理
解析器内部也分了好几个子解析器,比如HTML解析器、文本解析器以及过滤器解析器,其中最主要的是HTML解析器。顾名思义,HTML解析器的作用是解析HTML,它在解析HTML的过程中会不断触发各种钩子函数。这些钩子函数包括开始标签钩子函数、结束标签钩子函数、文本钩子函数以及注释钩子函数。
伪代码:
1 | parseHTML(template, { |
1 | <div><p>我是berwin</p></div> |
当上面这个模板被HTML解析器解析时,所触发的钩子函数依次是:start、start、chars、end和end。
也就是说,解析器其实是从前向后解析的。解析到 <div> 时,会触发一个标签开始的钩子函数start;然后解析到 <p> 时,又触发一次钩子函数start;接着解析到我是Berwin这行文本,此时触发了文本钩子函数chars;然后解析到 </p>,触发了标签结束的钩子函数end;接着继续解析到 </div>,此时又触发一次标签结束的钩子函数end,解析结束。
因此,我们可以在钩子函数中构建AST节点。在start钩子函数中构建元素类型的节点,在chars钩子函数中构建文本类型的节点,在comment钩子函数中构建注释类型的节点。
1 | function createASTElement (tag, attrs, parent ){ |
基于HTML解析器的逻辑,我们可以在每次触发钩子函数start时,把当前构建的节点推入栈中;每当触发钩子函数end时,就从栈中弹出一个节点。
这样就可以保证每当触发钩子函数start时,栈的最后一个节点就是当前正在构建的节点的父节点,如下图:
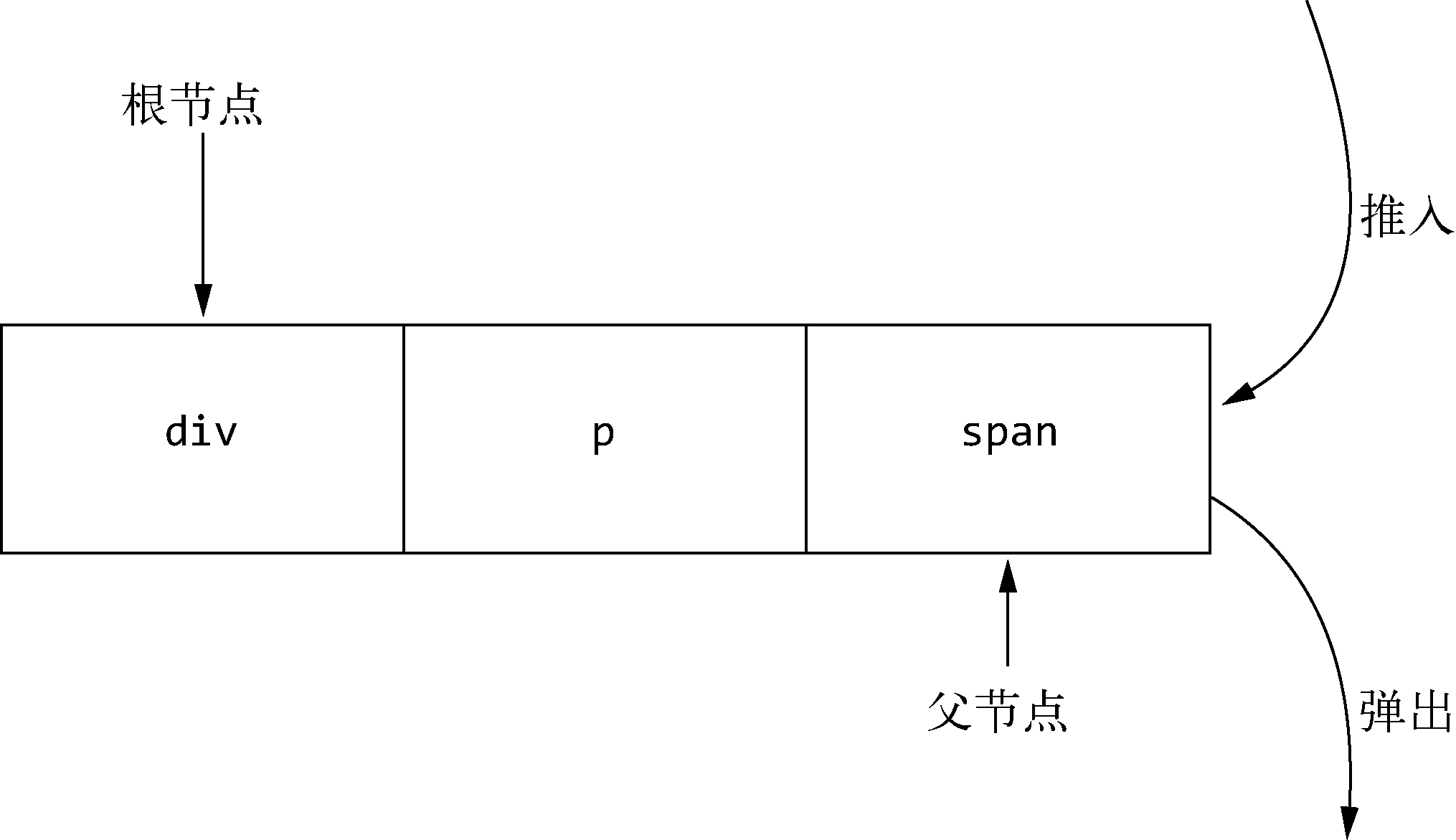
假如有个模板:
1 | <div> |
上面模板解析成AST的过程如下:
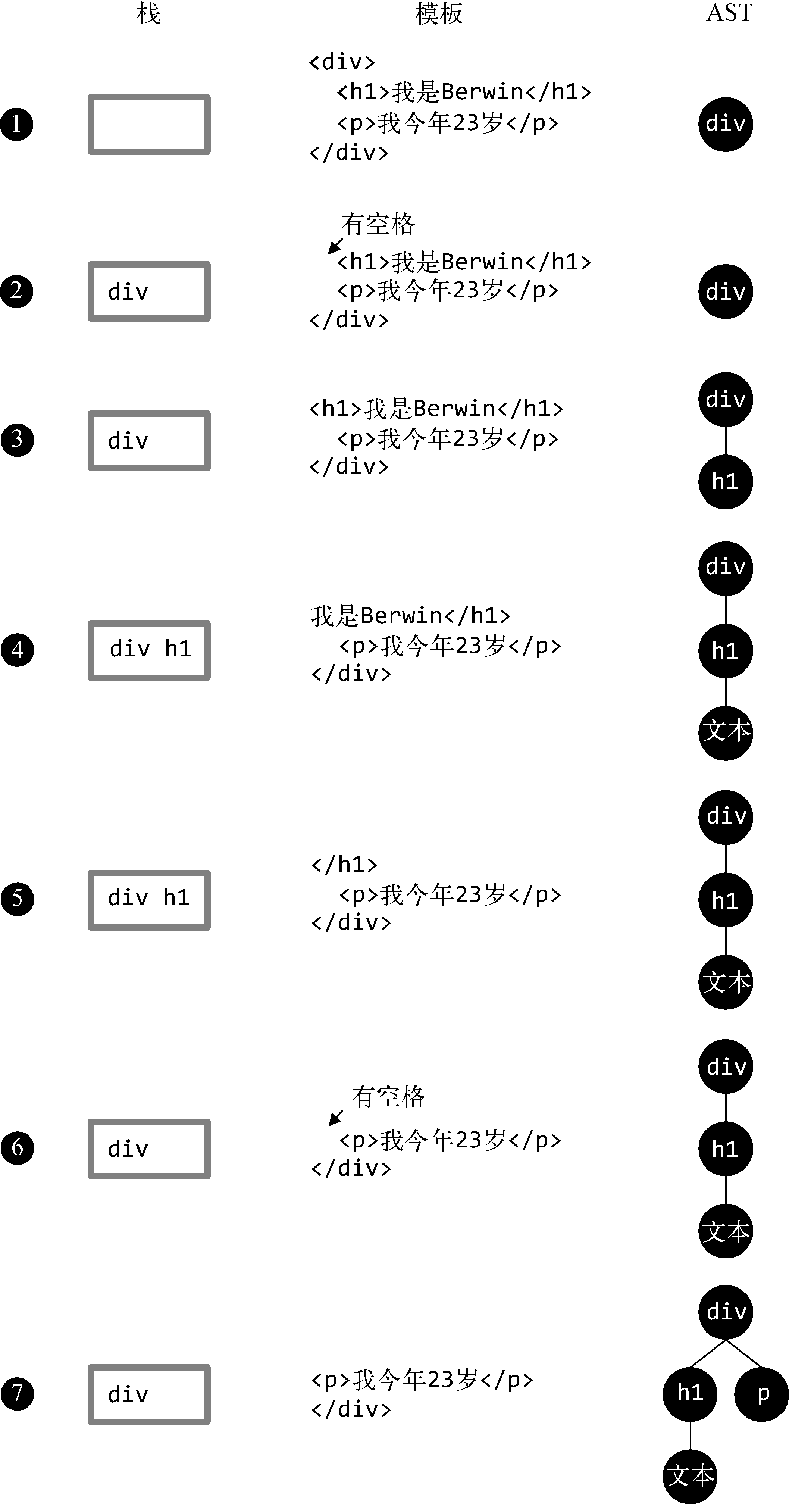
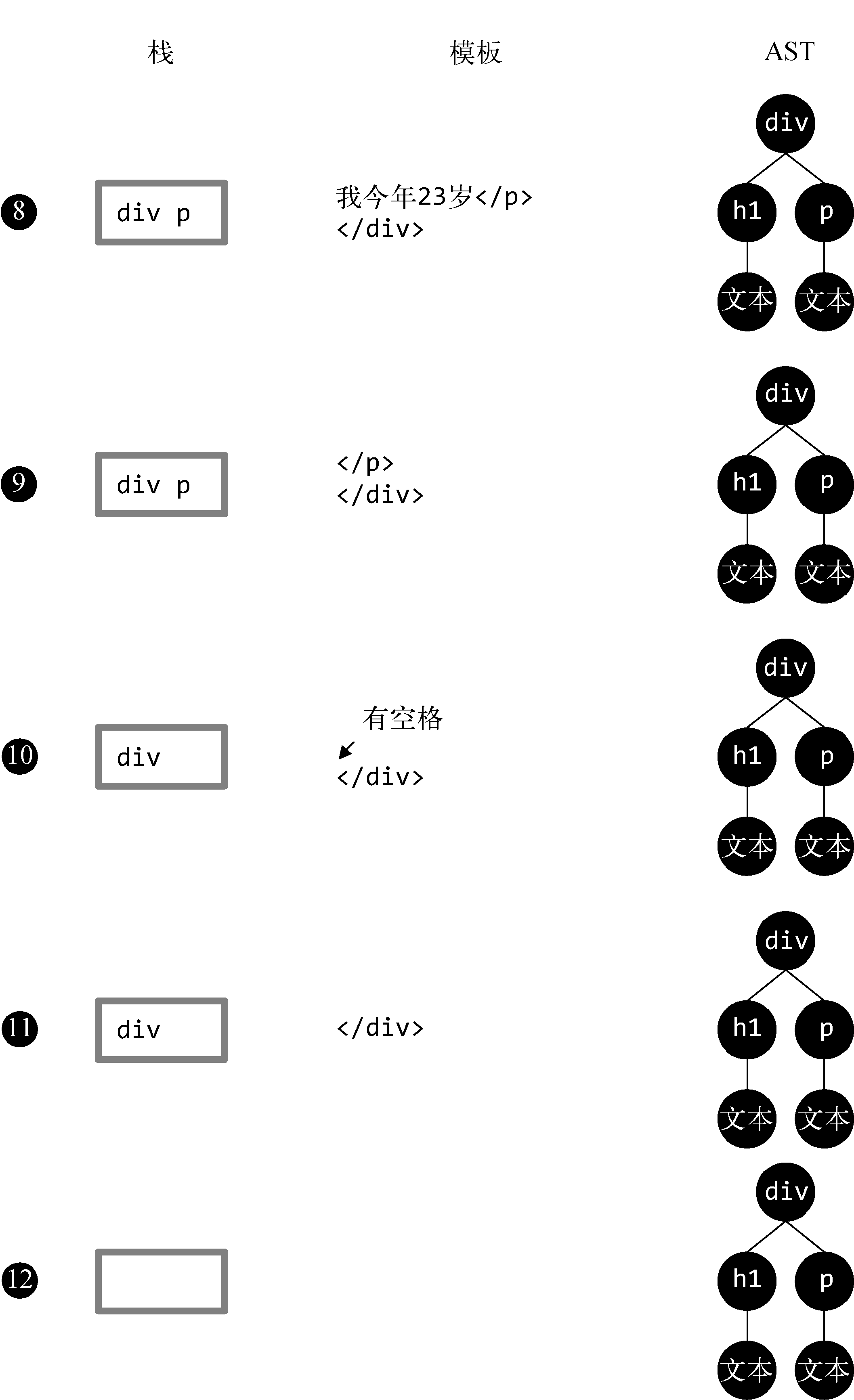
❶ 模板的开始位置是div的开始标签,于是会触发钩子函数start。start触发后,会先构建一个div节点。此时发现栈是空的,这说明div节点是根节点,因为它没有父节点。最后,将div节点推入栈中,并将模板字符串中的div开始标签从模板中截取掉。
❷ 这时模板的开始位置是一些空格,这些空格会触发文本节点的钩子函数,在钩子函数里会忽略这些空格。同时会在模板中将这些空格截取掉。
❸ 这时模板的开始位置是h1的开始标签,于是会触发钩子函数start。与前面流程一样,start触发后,会先构建一个h1节点。此时发现栈的最后一个节点是div节点,这说明h1节点的父节点是div,于是将h1添加到div的子节点中,并且将h1节点推入栈中,同时从模板中将h1的开始标签截取掉。
❹ 这时模板的开始位置是一段文本,于是会触发钩子函数chars。chars触发后,会先构建一个文本节点,此时发现栈中的最后一个节点是h1,这说明文本节点的父节点是h1,于是将文本节点添加到h1节点的子节点中。由于文本节点没有子节点,所以文本节点不会被推入栈中。最后,将文本从模板中截取掉。
❺ 这时模板的开始位置是h1结束标签,于是会触发钩子函数end。end触发后,会把栈中最后一个节点弹出来。
❻ 与第 ❷ 步一样,这时模板的开始位置是一些空格,这些空格会触发文本节点的钩子函数,在钩子函数里会忽略这些空格。同时会在模板中将这些空格截取掉。
❼ 这时模板的开始位置是p开始标签,于是会触发钩子函数start。start触发后,会先构建一个p节点。由于第 ❺ 步已经从栈中弹出了一个节点,所以此时栈中的最后一个节点是div,这说明p节点的父节点是div。于是将p推入div的子节点中,最后将p推入到栈中,并将p的开始标签从模板中截取掉。
❽ 这时模板的开始位置又是一段文本,于是会触发钩子函数chars。当chars触发后,会先构建一个文本节点,此时发现栈中的最后一个节点是p节点,这说明文本节点的父节点是p节点。于是将文本节点推入p节点的子节点中,并将文本从模板中截取掉。
❾ 这时模板的开始位置是p的结束标签,于是会触发钩子函数end。当end触发后,会从栈中弹出一个节点出来,也就是把p标签从栈中弹出来,并将p的结束标签从模板中截取掉。
❿ 与第 ❷ 步和第 ❻ 步一样,这时模板的开始位置是一些空格,这些空格会触发文本节点的钩子函数并且在钩子函数里会忽略这些空格。同时会在模板中将这些空格截取掉。
⓫ 这时模板的开始位置是div的结束标签,于是会触发钩子函数end。其逻辑与之前一样,把栈中的最后一个节点弹出来,也就是把div弹了出来,并将div的结束标签从模板中截取掉。
⓬ 这时模板已经被截取空了,也就说明HTML解析器已经运行完毕。这时我们会发现栈已经空了,但是我们得到了一个完整的带层级关系的AST语法树。这个AST中清晰写明了每个节点的父节点、子节点及其节点类型。
3.3 HTML解析器
我们发现构建AST非常依赖HTML解析器所执行的钩子函数以及钩子函数中所提供的参数,你一定会非常好奇HTML解析器是如何解析模板的。
3.3.1 运行原理
事实上,解析HTML模板的过程就是循环的过程,简单来说就是用HTML模板字符串来循环,每轮循环都从HTML模板中截取一小段字符串,然后重复以上过程,直到HTML模板被截成一个空字符串时结束循环,解析完毕(如上图所示)。
1 | function parseHTML(html, options) { |
HTML模板:
1 | `<div> |
第一轮循环时,截取一段字符串<div>, 切触发钩子函数start, 截取后的结果为:
1 | ` |
第二轮循环时,截取出一段字符串
1 | ` |
并且触发钩子函数chars,截取后的结果为:
1 | `<p>{{name}}</p> |
第三轮循环时,截取出一段字符串 <p>,并且触发钩子函数start,截取后的结果为:
1 | `{{name}}</p> |
第四轮循环时,截取出一段字符串 ,并且触发钩子函数chars,截取后的结果为:
1 | `</p> |
第五轮循环时,截取出一段字符串 </p>,并且触发钩子函数end,截取后的结果为:
1 | ` |
第六轮循环时,截取出一段字符串:
1 | ` |
并且触发钩子函数chars,截取后的结果为:
1 | `</div>` |
第七轮循环时,截取出一段字符串 </div>,并且触发钩子函数end,截取后的结果为:
1 | `` |
这些被截取的片段分很多种类型,示例如下:
● 开始标签,例如 <div>。
● 结束标签,例如 </div>。
● HTML注释,例如 <!– 我是注释 –>。
● DOCTYPE,例如 。
● 条件注释,例如 <!–[if !IE]>–>我是注释<!–<![endif]–>。
● 文本,例如我是Berwin。
3.3.2 截取开始标签
如何确定模板是不是以开始标签开头?
在HTML解析器中,想分辨出模板是否以开始标签开头并不难,我们需要先判断HTML模板是不是以 < 开头。
如何使用正则表达式来匹配模板以开始标签开头?我们看下面的代码:
1 | const ncname = '[a-zA-Z_][\\w\\-\\.]*'; |
通过上面的例子可以看到,只有 ‘<div></div>‘ 可以成功匹配,而以 </div> 开头的或者以文本开头的模板都无法成功匹配。
当完成上面的解析后,我们可以得到这样一个数据结构:
1 | const start = '<div></div>'.match(startTagOpen) |
前面解析开始标签时,我们将其拆解成了三个部分,分别是标签名、属性和结尾。我相信你已经对开始标签的解析有了一个清晰的认识,接下来看一下Vue.js中真实的代码是什么样的:
1 | const ncname = '[a-zA-Z_][\\w\\-\\.]*' |
上面的代码是Vue.js中解析开始标签的源码,这段代码中的html变量是HTML模板。
3.3.3 截取结束标签
如果HTML模板的第一个字符不是 <,那么一定不是结束标签。只有HTML模板的第一个字符是 < 时,我们才需要进一步确认它到底是不是结束标签。
进一步确认时,我们只需要判断剩余HTML模板的开始位置是否符合正则表达式中定义的规则即可:
1 | const ncname = '[a-zA-Z_][\\w\\-\\.]*' |
而Vue.js中相关源码被精简后如下:
1 | const endTagMatch = html.match(endTag) |
3.3.4 截取注释
分辨模板是否已经截取到注释的原理与开始标签和结束标签相同,先判断剩余HTML模板的第一个字符是不是 <,如果是,再用正则表达式来进一步匹配:
1 | const comment = /^<!--/ |
3.3.5 截取条件注释
截取条件注释的原理与截取注释非常相似,如果模板的第一个字符是 <,并且符合我们事先用正则表达式定义好的规则,就说明需要进行条件注释的截取操作。
1 | const conditionalComment = /^<!\[/ |
举个例子:
1 | const conditionalComment = /^<!\[/ |
通过这个逻辑可以发现,在Vue.js中条件注释其实没有用,写了也会被截取掉,通俗一点说就是写了也白写。
3.3.6 截取DOCTYPE
1 | const doctype = /^<!DOCTYPE [^>]+>/i |
例子:
1 | const doctype = /^<!DOCTYPE [^>]+>/i |
3.3.7 截取文本
在前面的其他标签类型中,我们都会判断剩余HTML模板的第一个字符是否是 <,如果是,再进一步确认到底是哪种类型。这是因为以 < 开头的标签类型太多了,如开始标签、结束标签和注释等。然而文本只有一种,如果HTML模板的第一个字符不是 <,那么它一定是文本了。
1 | 我是文本</div> |
上面这段HTML模板并不是以 < 开头的,所以可以断定它是以文本开头的。那么,如何从模板中将文本解析出来呢?我们只需要找到下一个 < 在什么位置,这之前的所有字符都属于文本。
代码中可以这样实现:
1 | while (html) { |
如果 < 是文本的一部分,该如何处理:
1 | <我<是文本</div> |
1 | while (html) { |
上面的代码中,endTag、startTagOpen、comment和conditionalComment都是正则表达式,分别匹配结束标签、开始标签、注释和条件注释。
3.3.8 纯文本内容元素的处理
什么是纯文本内容元素呢?script、style和textarea这三种元素叫作纯文本内容元素。解析它们的时候,会把这三种标签内包含的所有内容都当作文本处理。
前面介绍开始标签、结束标签、文本、注释的截取时,其实都是默认当前需要截取的元素的父级元素不是纯文本内容元素。事实上,如果要截取元素的父级元素是纯文本内容元素的话,处理逻辑将完全不一样。
1 | while (html) { |
在上面的代码中,lastTag表示父元素。可以看到,在while中,首先进行判断,如果父元素不存在或者不是纯文本内容元素,那么进行正常的处理逻辑,也就是前面介绍的逻辑。
而当父元素是script这种纯文本内容元素时,会进入到else这个语句里面。由于纯文本内容元素都被视作文本处理,所以我们的处理逻辑就变得很简单,只需要把这些文本截取出来并触发钩子函数chars,然后再将结束标签截取出来并触发钩子函数end。
假如我们现在有这样一个模板:
1 | <div id="el"> |
当解析到script中的内容时,模板是下面的样子:
1 | console.log(1)</script> |
钩子函数chars的参数为script中的所有内容,本例中大概是下面的样子:
1 | chars('console.log(1)') |
处理后的剩余模板如下:
1 | </div> |
3.3.9 使用栈维护DOM层级
在前面几节中,我们并没有介绍HTML解析器内部其实也有一个栈来维护DOM层级关系,其逻辑与9.2.1节相同:就是每解析到开始标签,就向栈中推进去一个;每解析到标签结束,就弹出来一个。因此,想取到父元素并不难,只需要拿到栈中的最后一项即可。
同时,HTML解析器中的栈还有另一个作用,它可以检测出HTML标签是否正确闭合。例如:
1 | <div><p></div> |
在上面的代码中,p标签忘记写结束标签,那么当HTML解析器解析到div的结束标签时,栈顶的元素却是p标签。这个时候从栈顶向栈底循环找到div标签,发现在找到div标签之前遇到的所有其他标签都忘记写闭合标签,此时Vue.js会在非生产环境下的控制台中打印警告提示。
3.3.10 整体逻辑
前面我们把开始标签、结束标签、注释、文本、纯文本内容元素等的截取方式拆分开,单独进行了详细介绍。本节中,我们就来介绍如何将这些解析方式组装起来完成HTML解析器的功能。
首先,HTML解析器是一个函数。就像9.2节介绍的那样,HTML解析器最终的目的是实现这样的功能:
1 | parseHTML(template, { |
文本解析器原理
文本解析器的作用是解析文本。你可能会觉得很奇怪,文本不是在HTML解析器中被解析出来了么?准确地说,文本解析器是对HTML解析器解析出来的文本进行二次加工。为什么要进行二次加工?
文本其实分两种类型,一种是纯文本,另一种是带变量的文本。
1 | Hello World |
而在构建文本类型的AST时,纯文本和带变量的文本是不同的处理方式。如果是带变量的文本,我们需要借助文本解析器对它进行二次加工,其代码如下:
1 | paseHTML(template, { |
1 | "hello {{name}}" |
解析之后,得到expression变量为:
1 | "hello "+_s(name) |
_s其实是下面这个toString函数的别名:
1 | function toString(val){ |
假设当前上下文中有一个变量name,其值为Berwin,那么expression中的内容被执行时,它的内容是不是就是Hello Berwin了?
举个例子:
1 | let obj = {name: 'Berwin'}; |
在文本解析器中,**第一步要做的事情就是使用正则表达式来判断文本是否为带变量的文本,也就是检查文本中是否包含 这样的语法。如果是纯文本,则直接返回undefined;如果是带变量的文本,再进行二次加工。**所以我们的代码是这样的:
1 | function parseText (text){ |
一个解决思路是使用正则表达式匹配出文本中的变量,先把变量左边的文本添加到数组中,然后把变量改成 _s(x)这样的形式也添加到数组中。如果变量后面还有变量,则重复以上动作,直到所有变量都添加到数组中。如果最后一个变量的后面有文本,就将它添加到数组中。
这时我们其实已经有一个数组,数组元素的顺序和文本的顺序是一致的,此时将这些数组元素用+连起来变成字符串,就可以得到最终想要的效果:
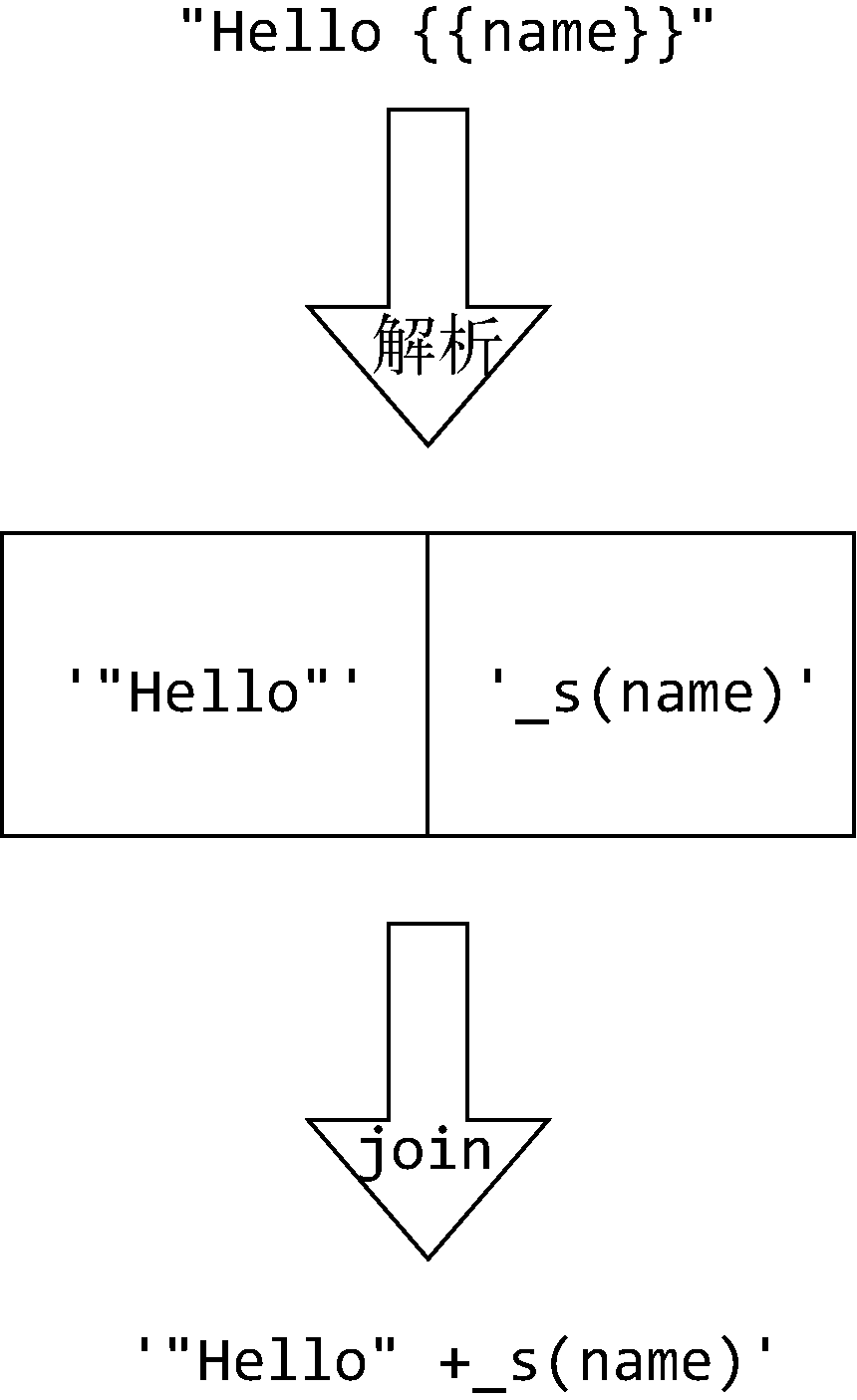
具体实现代码如下:
1 | function parseText(text){ |
这段代码有一个很关键的地方在lastIndex:每处理完一个变量后,会重新设置lastIndex的位置,这样可以保证如果后面还有其他变量,那么在下一轮循环时可以从lastIndex的位置开始向后匹配,而lastIndex之前的文本将不再被匹配。
总结
解析器的作用是通过模板得到AST(抽象语法树)。
生成AST的过程需要借助HTML解析器,当HTML解析器触发不同的钩子函数时,我们可以构建出不同的节点。
随后,我们可以通过栈来得到当前正在构建的节点的父节点,然后将构建出的节点添加到父节点的下面。
最终,当HTML解析器运行完毕后,我们就可以得到一个完整的带DOM层级关系的AST。
HTML解析器的内部原理是一小段一小段地截取模板字符串,每截取一小段字符串,就会根据截取出来的字符串类型触发不同的钩子函数,直到模板字符串截空停止运行。
文本分两种类型,不带变量的纯文本和带变量的文本,后者需要使用文本解析器进行二次加工。
4、优化器
解析器的作用是将HTML模板解析成AST,而优化器的作用是在AST中找出静态子树并打上标记。
静态子树指的是那些在AST中永远都不会发生变化的节点。例如,一个纯文本节点就是静态子树,而带变量的文本节点就不是静态子树,因为它会随着变量的变化而变化。
标记静态子树有两点好处:
● 每次重新渲染时,不需要为静态子树创建新节点;
● 在虚拟DOM中打补丁(patching)的过程可以跳过。
每次重新渲染时,不需要为静态子树创建新节点,是什么意思呢?
前面介绍虚拟DOM时,我们说每次重新渲染都会使用最新的状态生成一份全新的VNode与旧的VNode进行对比。而在生成VNode的过程中,如果发现一个节点被标记为静态子树,那么除了首次渲染会生成节点之外,在重新渲染时并不会生成新的子节点树,而是克隆已存在的静态子树。
在虚拟DOM中打补丁的过程可以被跳过,又是什么意思?
我们介绍了如果两个节点都是静态子树,就不需要进行对比与更新DOM的操作,直接跳过。因为静态子树是不可变的,不需要对比就知道它不可能发生变化。此外,直接跳过后续的各种对比可以节省JavaScript的运算成本。
优化器的内部实现主要分为两个步骤:
(1) 在AST中找出所有静态节点并打上标记;
(2) 在AST中找出所有静态根节点并打上标记。
先标记所有静态节点,再标记所有静态根节点。那么,什么是静态节点?像下面这样永远都不会发生变化的节点属于静态节点:
1 | <p>我是静态节点</p> |
落到AST中,静态节点指static为true节点
1 | { |
什么是静态根节点?如果一个节点下面的所有子节点都是静态节点,并且它的父级是动态节点,那么它就是静态根节点。下面模板中的ul就属于静态根节点:
1 | <ul> |
落到AST中, 静态根节点指staticRoot属性为true
1 | { |
举个例子:
1 | <div id="el">Hello {{name}}</div> |
如果我们有上面这样一个模板,它转换成AST之后是下面的样子:
1 | 01 { |
经过优化器优化后,AST如下:
1 | 01 { |
4.1 找出所有静态节点并标记
找出所有静态子节点并不难,我们只需要从根节点开始,先判断根节点是不是静态根节点,再用相同的方式处理子节点,接着用同样的方式去处理子节点的子节点,直到所有节点都被处理之后程序结束,这个过程叫作递归。
1 | function markStatic (node) { |
isStatic方法如下:
1 | function isStatic (node) { |
type的取值及其说明:
1、type = 1 为 元素节点
2、type = 2 为 带变量的动态文本节点
3、type = 3 为 不带变量的纯文本阶段
当type等于1时,说明节点是元素节点。当一个节点是元素节点时,想分辨出它是否是静态节点,就会稍微有点复杂。
首先,如果元素节点使用了指令v-pre,那么可以直接断定它是一个静态节点
其次,如果元素节点没有使用指令v-pre,那么它必须同时满足以下条件才会被认为是一个静态节点。
● 不能使用动态绑定语法,也就是说标签上不能有以v-、@、:开头的属性。
● 不能使用v-if、v-for或者v-else指令。
● 不能是内置标签,也就是说标签名不能是slot或者component。
● 不能是组件,即标签名必须是保留标签,例如<div></div>是保留标签,而<list></list>不是保留标签。
● 当前节点的父节点不能是带v-for指令的template标签。
● 节点中不存在动态节点才会有的属性。
我们已经可以判断一个节点是否是静态节点,并且可以通过递归的方式来标记子节点是否是静态节点。
但是这里会遇到一个问题,递归是从上向下依次标记的,如果父节点被标记为静态节点之后,子节点却被标记为动态节点,这时就会发生矛盾。因为静态子树中不应该只有它自己是静态节点,静态子树的所有子节点应该都是静态节点。
1 | function markStatic (node) { |
4.2 找出所有静态根节点并标记
4.3 总结
优化器的作用是在AST中找出静态子树并打上标记,这样做有两个好处:
● 每次重新渲染时,不需要为静态子树创建新节点;
● 在虚拟DOM中打补丁的过程可以跳过。
通过递归的方式从上向下标记静态节点时,如果一个节点被标记为静态节点,但它的子节点却被标记为动态节点,就说明该节点不是静态节点,可以将它改为动态节点。静态节点的特征是它的子节点必须是静态节点。
标记完静态节点之后需要标记静态根节点,其标记方式也是使用递归的方式从上向下寻找,在寻找的过程中遇到的第一个静态节点就为静态根节点,同时不再向下继续查找。
但有两种情况比较特殊:一种是如果一个静态根节点的子节点只有一个文本节点,那么不会将它标记成静态根节点,即便它也属于静态根节点;另一种是如果找到的静态根节点是一个没有子节点的静态节点,那么也不会将它标记为静态根节点。因为这两种情况下,优化成本大于收益。
5、代码生成器
代码生成器是模板编译的最后一步,它的作用是将AST转换成渲染函数中的内容,这个内容可以称为代码字符串。
代码字符串可以被包装在函数中执行,这个函数就是我们通常所说的渲染函数。
本章中,我们主要讨论如何使用AST生成代码字符串。
假设现在有这样一个简单的模板:
1 | <div id="el">Hello {{name}}</div> |
它转换成AST并且经过优化器的优化之后是下面的样子:
1 | { |
代码生成器可以通过上面这个AST来生成代码字符串,生成后的代码字符串是这样的:
1 | 'with(this){return _c("div",{attrs:{"id":"el"}},[_v("Hello "+_s(name))])}' |
仔细观察生成后的代码字符串,我们会发现,这其实是一个嵌套的函数调用。函数_c的参数中执行了函数 _v,而函数 _v的参数中又执行了函数 _s。
_c其实是createElement的别名。createElement是虚拟DOM中所提供的方法,它的作用是创建虚拟节点,有三个参数,分别是:
● 标签名
● 一个包含模板相关属性的数据对象
● 子节点列表
调用createElement方法,我们可以得到一个VNode。
这也就知道了渲染函数可以生成VNode的原因:渲染函数其实是执行了createElement,而createElement可以创建一个VNode。
5.1 通过AST生成代码字符串
生成代码字符串是一个递归的过程,从顶向下依次处理每一个AST节点
节点有三种类型,分别对应三种不同的创建方法与别名:

例如:
1 | <div id="el"> |
生成代码字符串:
1 | _c('div', |
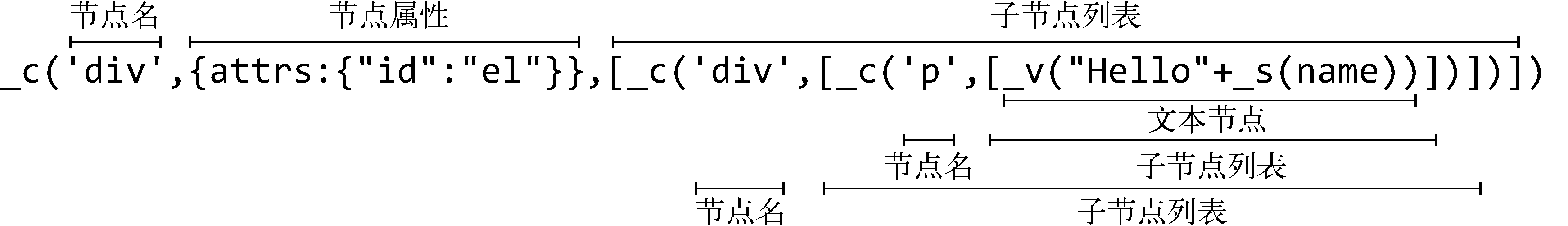
当递归结束时,我们就可以得到一个完整的代码字符串。这段代码字符串会被包裹在with语句中,其伪代码如下:
1 | `with(this){return ${code}}` |
5.2 代码生成器的原理
5.2.1 元素节点
生成元素节点,其实就是生成一个 _c的函数调用字符串,相关代码如下:
1 | function genElement (el, state) { |
代码中el的plain属性是在编译时发现的。如果节点没有属性,就会把plain设置为true。
这里我们可以通过plain来判断是否需要获取节点的属性数据。代码中的主要逻辑是用genData和genChildren分别获取data和children,然后将它们分别拼到字符串中指定的位置,最后把拼好的 “_c(tagName, data, children)”返回,这样一个元素节点的代码字符串就生成好了。
5.2.2 文本节点
生成文本节点很简单,我们只需要把文本放在 _v这个函数的参数中即可:
1 | function genText (text) { |
如果是动态文本,则使用expression;如果是静态文本,则使用text。
你可能会问,为什么text需要使用JSON.stringify方法?
这是因为expression中的文本是这样的:
1 | '"Hello "+_s(name)' |
而text中的文本是这样的:
1 | "Hello Berwin" |
而我们希望静态文本是这样的:
1 | '"Hello Berwin"' |
所以静态文本需要使用JSON.stringify方法。因为JSON.stringify可以给文本包装一层字符串
5.2.3 注释节点
注释节点与文本节点相同,只需要把文本放在 _e的参数中即可,其代码如下:
1 | function genComment (comment) { |
5.3 总结
了解了代码生成器其实就是字符串拼接的过程。通过递归AST来生成字符串,最先生成根节点,然后在子节点字符串生成后,将其拼接在根节点的参数中,子节点的子节点拼接在子节点的参数中,这样一层一层地拼接,直到最后拼接成完整的字符串。
最后,我们介绍了当字符串拼接好后,会将字符串拼在with中返回给调用者。
6、整体流程
1、架构设计和项目结构
不同的Vue.js构建版本的区别:
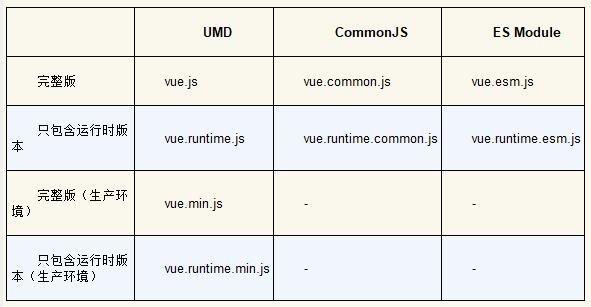
• 完整版:构建后的文件同时包含编译器和运行时。
• 编译器:负责将模板字符串编译成JavaScript渲染函数,这部分内容在第三篇中介绍过。
• 运行时:负责创建Vue.js实例,渲染视图和使用虚拟DOM实现重新渲染,基本上包含除编译器外的所有部分。
• UMD:UMD版本的文件可以通过 <script> 标签直接在浏览器中使用, 就是运行时+编译器的UMD版本。
• CommonJS:CommonJS版本用来配合较旧的打包工具,比如Browserify或webpack 1,这些打包工具的默认文件(pkg.main)只包含运行时的CommonJS版本(vue.runtime.common.js)。
• ES Module:ES Module版本用来配合现代打包工具,比如webpack 2或Rollup,这些打包工具的默认文件(pkg.module)只包含运行时的ES Module版本(vue.runtime.esm.js)。
运行时+编译器 与 只包含运行时区别:
如果需要在客户端编译模板(比如传入一个字符串给template选项,或挂载到一个元素上并以其DOM内部的HTML作为模板),那么需要用到编译器,因此需要完整版:
1 | // 需要编译器 |
当使用vue-loader或vueify的时候,*.vue文件内部的模板会在构建时预编译成JavaScript。所以,最终打包完成的文件实际上是不需要编译器的,只需要引入运行时版本即可。
由于运行时版本的体积比完整版要小30%左右,所以应该尽可能使用运行时版本。如果仍然希望使用完整版,则需要在打包工具里配置一个别名。
1 | module.exports = { |
CommonJS和ES Module版本用于打包工具,因此Vue.js不提供压缩后的版本,需要自行将最终的包进行压缩。此外,这两个版本同时保留原始的process.env.NODE_ENV检测,来决定它们应该在什么模式下运行。我们应该使用适当的打包工具配置来替换这些环境变量,以便控制Vue.js所运行的模式。把process.env.NODE_ENV替换为字符串字面量,同时让UglifyJS之类的压缩工具完全删除仅供开发环境的代码块,从而减少最终文件的大小。
在webpack中,我们使用DefinePlugin:
1 | new webpack.DefinePlugin({ |
1.1 架构设计
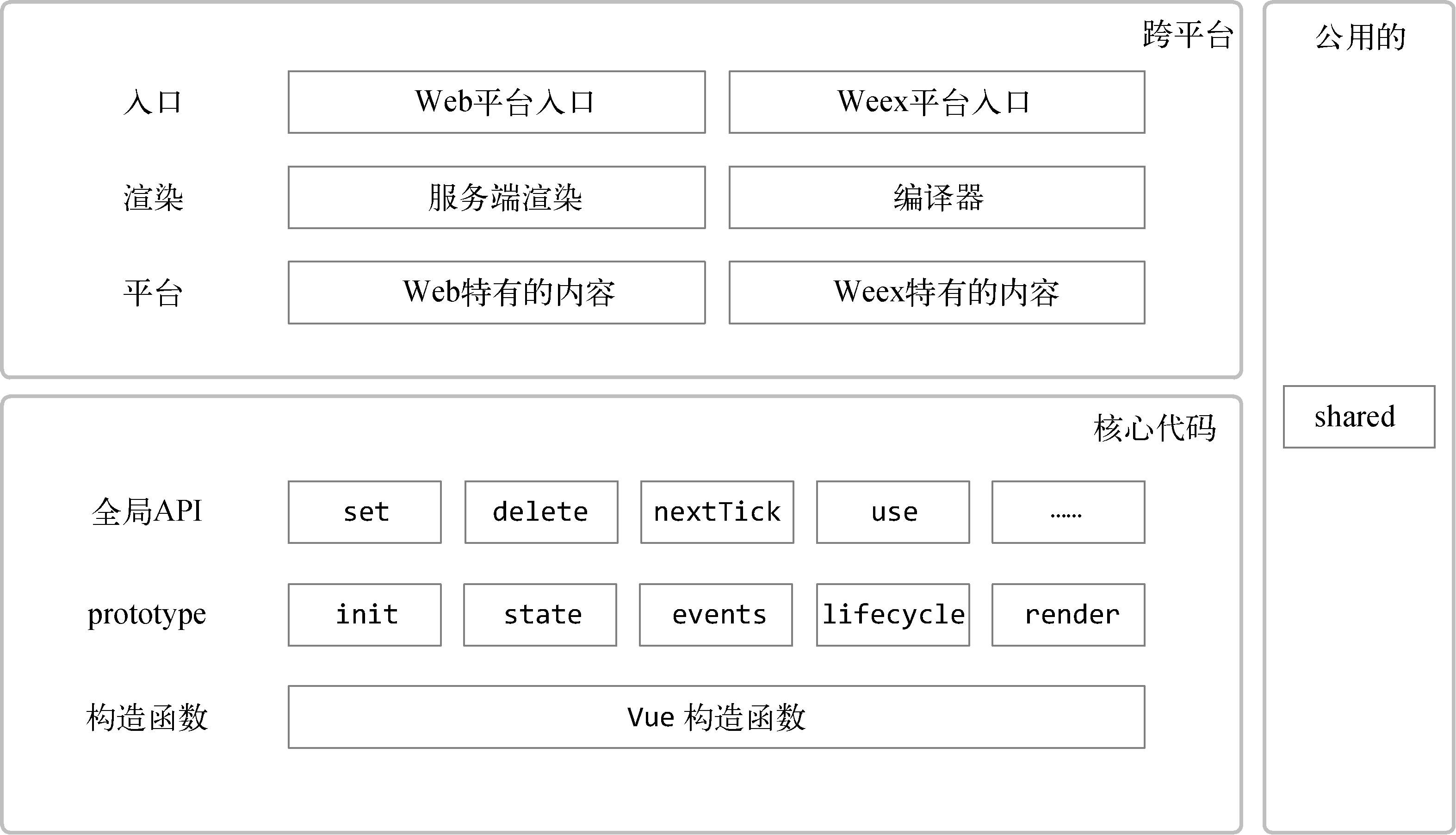
最顶层是入口,也可以叫作出口。对于构建工具和Vue.js的使用者来说,这是入口;对于Vue.js自身来说,这是出口。在构建文件时,不同平台的构建文件会选择不同的入口进行构建操作。
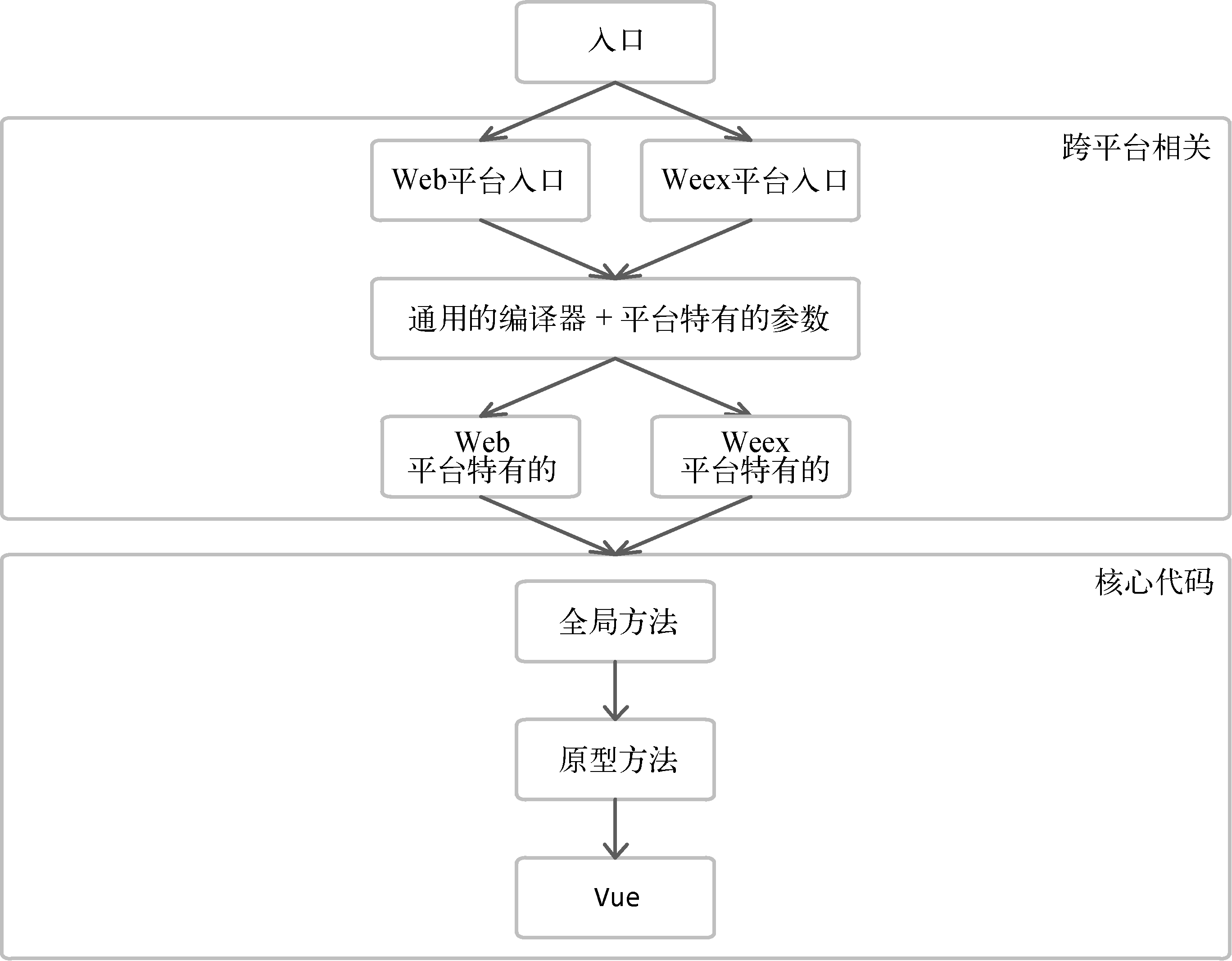
从整体结构上看,下面三层的代码是与平台无关的核心代码,上面三层是与平台相关的代码。因此,整个程序结构还可以用另一种表现形式来展现:
1.2 总结
在架构设计中,我们介绍了Vue.js在大体上可以分三部分:核心代码、跨平台相关与公用工具函数。核心代码包含原型方法和全局API,它们可以在各个平台下运行,而跨平台相关的部分更多的是渲染相关的功能,不同平台下的渲染API是不同的。以Web平台为例,Web页面中的渲染操作就是操作DOM,所以在跨平台的Web环境下对DOM操作的API进行了封装,这个封装主要与虚拟DOM对接,而虚拟DOM中所使用的各种节点操作其实是调用跨平台层封装的API接口。而Weex平台对节点的操作与Web平台并不相同。
2、实例方法和全局API的实现原理
上一章介绍了Vue.js内部的整体结构,知道了它会向构造函数添加一些属性和方法。本章中,我们将详细介绍它的实例方法和全局API的实现原理。
1 | import { initMixin } from './init' |
其中定义了Vue构造函数,然后分别调用了initMixin、stateMixin、eventsMixin、lifecycleMixin和renderMixin这5个函数,并将Vue构造函数当作参数传给了这5个函数。
这5个函数的作用就是向Vue的原型中挂载方法,以函数initMixin为例,它的实现方式是这样的:
1 | export function initMixin(Vue){ |
2.1 数据相关的实例方法
与数据相关的实例方法有3个,分别是vm.$watch、vm.$set和vm.$delete,它们是在stateMixin中挂载到Vue的原型上的,代码如下:
1 | import { |
可以看到,当stateMixin被调用时,会向Vue构造函数的prototype属性挂载上面说的3个与数据相关的实例方法。
2.2 事件相关的实例方法
与事件相关的实例方法有4个,分别是:vm.$on、vm.$once、vm.$off和vm.$emit。这4个方法是在eventsMixin中挂载到Vue构造函数的prototype属性中的,其代码如下:
1 | export function eventsMixin (Vue) { |
2.2.1 vm.$on
使用:监听当前实例上的自定义事件,事件可以由vm.$emit触发。回调函数会接收所有传入事件所触发的函数的额外参数。
1 | vm.$on('test', function (msg) { |
原理:
1 | Vue.prototype.$on = function (event, fn) { |
vm._events是一个对象,用来存储事件。在代码中,我们使用事件名(event)从vm._events中取出事件列表,如果列表不存在,则使用空数组初始化,然后再将回调函数添加到事件列表中。
vm._events是哪儿来的?事实上,在执行new Vue()时,Vue会执行this._init方法进行一系列初始化操作,其中就会在Vue.js的实例上创建一个 _events属性,用来存储事件。
1 | vm._events = Object.create(null) |
2.2.2 vm.$off
使用:移除自定义事件监听器
● 如果没有提供参数,则移除所有的事件监听器。
● 如果只提供了事件,则移除该事件所有的监听器。
● 如果同时提供了事件与回调,则只移除这个回调的监听器。
原理:
1、首先,我们需要处理没有提供参数的情况,此时需要移除所有事件的监听器,其代码如下:
1 | Vue.prototype.$off = function (event, fn) { |
2、接下来,我们需要处理第二种条件:如果只提供了事件名,则移除该事件所有的监听器。实现这个功能并不复杂,我们只需要从this._events中将event重置为空即可。
1 | Vue.prototype.$off = function (event, fn) { |
3、接下来处理最后一种情况:如果同时提供了事件与回调,那么只移除这个回调的监听器。实现这个功能并不复杂,只需要使用参数中提供的事件名从vm._events上取出事件列表,然后从列表中找到与参数中提供的回调函数相同的那个函数,并将它从列表中移除。综合上面2种情况其代码如下:
1 | Vue.prototype.$off = function (event, fn) { |
2.2.3 vm.$once
使用:监听一个自定义事件,但是只触发一次,在第一次触发之后移除监听器。
原理:我们知道vm.$once和vm.$on的区别是vm.$once只能被触发一次,所以实现这个功能的一个思路是:在vm.$once中调用vm.$on来实现监听自定义事件的功能,当自定义事件触发后会执行拦截器,将监听器从事件列表中移除。
1 | Vue.prototype.$once = function (event, fn) { |
2.2.4 vm.$emit
使用:触发当前实例上的事件。附加参数都会传给监听器回调。
原理:
1 | Vue.prototype.$emit = function (event) { |
这里我们使用event从vm._events中取出事件监听器回调函数列表,并将其赋值给变量cbs。如果cbs存在,则循环它,依次调用每一个监听器回调并将所有参数传给监听器回调。toArray的作用是将类似于数组的数据转换成真正的数组,它的第二个参数是起始位置。也就是说,args是一个数组,里面包含除第一个参数之外的所有参数。
2.3 生命周期相关的实例方法
与生命周期相关的实例方法有4个,分别是vm.$mount、vm.$forceUpdate、vm.$nextTick和vm.$destroy。其中有两个方法是从lifecycleMixin中挂载到Vue构造函数的prototype属性上的,分别是vm.$forceUpdate和vm.$destroy。lifecycleMixin的代码如下:
1 | export function lifecycleMixin (Vue) { |
vm.$nextTick方法是从renderMixin中挂载到Vue构造函数的prototype属性上的。renderMixin的代码如下:
1 | export function renderMixin (Vue) { |
而vm.$mount方法则是在跨平台的代码中挂载到Vue构造函数的prototype属性上的。
2.3.1 vm.$forceUpdate
vm.$forceUpdate()的作用是迫使Vue.js实例重新渲染。注意它仅仅影响实例本身以及插入插槽内容的子组件,而不是所有子组件。
我们只需要执行实例watcher的update方法,就可以让实例重新渲染。Vue.js的每一个实例都有一个watcher。第5章介绍虚拟DOM时提到,当状态发生变化时,会通知到组件级别,然后组件内部使用虚拟DOM进行更详细的重新渲染操作。事实上,组件就是Vue.js实例,所以组件级别的watcher和Vue.js实例上的watcher说的是同一个watcher。
1 | Vue.prototype.$forceUpdate = function () { |
vm._watcher就是Vue.js实例的watcher,每当组件内依赖的数据发生变化时,都会自动触发Vue.js实例中 _watcher的update方法。
重新渲染的实现原理并不难,Vue.js的自动渲染通过变化侦测来侦测数据,即当数据发生变化时,Vue.js实例重新渲染。而vm.$forceUpdate是手动通知Vue.js实例重新渲染。
2.3.2 vm.$destroy
vm.$destroy的作用是完全销毁一个实例,它会清理该实例与其他实例的连接,并解绑其全部指令及监听器,同时会触发beforeDestroy和destroyed的钩子函数。
这个方法并不是很常用,大部分场景下并不需要销毁组件,只需要使用v-if或者v-for等指令以数据驱动的方式控制子组件的生命周期即可。
完整的代码如下:
1 | Vue.prototype.$destroy = function () { |
2.3.3 vm.$nextTick
nextTick接收一个回调函数作为参数,它的作用是将回调延迟到下次DOM更新周期之后执行。它与全局方法Vue.nextTick一样,不同的是回调的this自动绑定到调用它的实例上。
我们在开发项目时会遇到一种场景:当更新了状态(数据)后,需要对新DOM做一些操作,但是这时我们其实获取不到更新后的DOM,因为还没有重新渲染。这个时候我们需要使用nextTick方法。
1 | new Vue({ |
在Vue.js中,当状态发生变化时,watcher会得到通知,然后触发虚拟DOM的渲染流程。而watcher触发渲染这个操作并不是同步的,而是异步的。Vue.js中有一个队列,每当需要渲染时,会将watcher推送到这个队列中,在下一次事件循环中再让watcher触发渲染的流程。
1、为什么Vue.js使用异步更新队列?
我们知道Vue.js 2.0开始使用虚拟DOM进行渲染,变化侦测的通知只发送到组件,组件内用到的所有状态的变化都会通知到同一个watcher,然后虚拟DOM会对整个组件进行“比对(diff)”并更改DOM。也就是说,如果在同一轮事件循环中有两个数据发生了变化,那么组件的watcher会收到两份通知,从而进行两次渲染。事实上,并不需要渲染两次,虚拟DOM会对整个组件进行渲染,所以只需要等所有状态都修改完毕后,一次性将整个组件的DOM渲染到最新即可。
要解决这个问题,Vue.js的实现方式是将收到通知的watcher实例添加到队列中缓存起来,并且在添加到队列之前检查其中是否已经存在相同的watcher,只有不存在时,才将watcher实例添加到队列中。然后在下一次事件循环(event loop)中,Vue.js会让队列中的watcher触发渲染流程并清空队列。这样就可以保证即便在同一事件循环中有两个状态发生改变,watcher最后也只执行一次渲染流程。
2、什么是事件循环?
我们都知道JavaScript是一门单线程且非阻塞的脚本语言,这意味着JavaScript代码在执行的任何时候都只有一个主线程来处理所有任务。而非阻塞是指当代码需要处理异步任务时,主线程会挂起(pending)这个任务,当异步任务处理完毕后,主线程再根据一定规则去执行相应回调。
事实上,当任务处理完毕后,JavaScript会将这个事件加入一个队列中,我们称这个队列为事件队列。被放入事件队列中的事件不会立刻执行其回调,而是等待当前执行栈中的所有任务执行完毕后,主线程会去查找事件队列中是否有任务。
异步任务有两种类型:微任务(microtask)和宏任务(macrotask)。不同类型的任务会被分配到不同的任务队列中。
当执行栈中的所有任务都执行完毕后,会去检查微任务队列中是否有事件存在,如果存在,则会依次执行微任务队列中事件对应的回调,直到为空。然后去宏任务队列中取出一个事件,把对应的回调加入当前执行栈,当执行栈中的所有任务都执行完毕后,检查微任务队列中是否有事件存在。无限重复此过程,就形成了一个无限循环,这个循环就叫作事件循环。
微任务:
- Promise.then
- MutationObserver
- Object.observe
- process.nextTick
宏任务:
- setTimeout
- setInterval
- setImmediate
- messageChannel
- requestAnimationFrame
- I/O
- UI rendering(交互渲染)
3、什么是执行栈?
当我们执行一个方法时,JavaScript会生成一个与这个方法对应的执行环境(context),又叫执行上下文。这个执行环境中有这个方法的私有作用域、上层作用域的指向、方法的参数、私有作用域中定义的变量以及this对象。这个执行环境会被添加到一个栈中,这个栈就是执行栈。
如果在这个方法的代码中执行到了一行函数调用语句,那么JavaScript会生成这个函数的执行环境并将其添加到执行栈中,然后进入这个执行环境继续执行其中的代码。执行完毕并返回结果后,JavaScript会退出执行环境并把这个执行环境从栈中销毁,回到上一个方法的执行环境。这个过程反复进行,直到执行栈中的代码全部执行完毕。这个执行环境的栈就是执行栈。
setTimeout属于宏任务,使用它注册的回调会加入到宏任务中。宏任务的执行要比微任务晚,所以即便是先注册,也是先更新DOM后执行setTimeout中设置的回调。
vm.$nextTick的实现原理:
1 | import { nextTick } from '../util/index' |
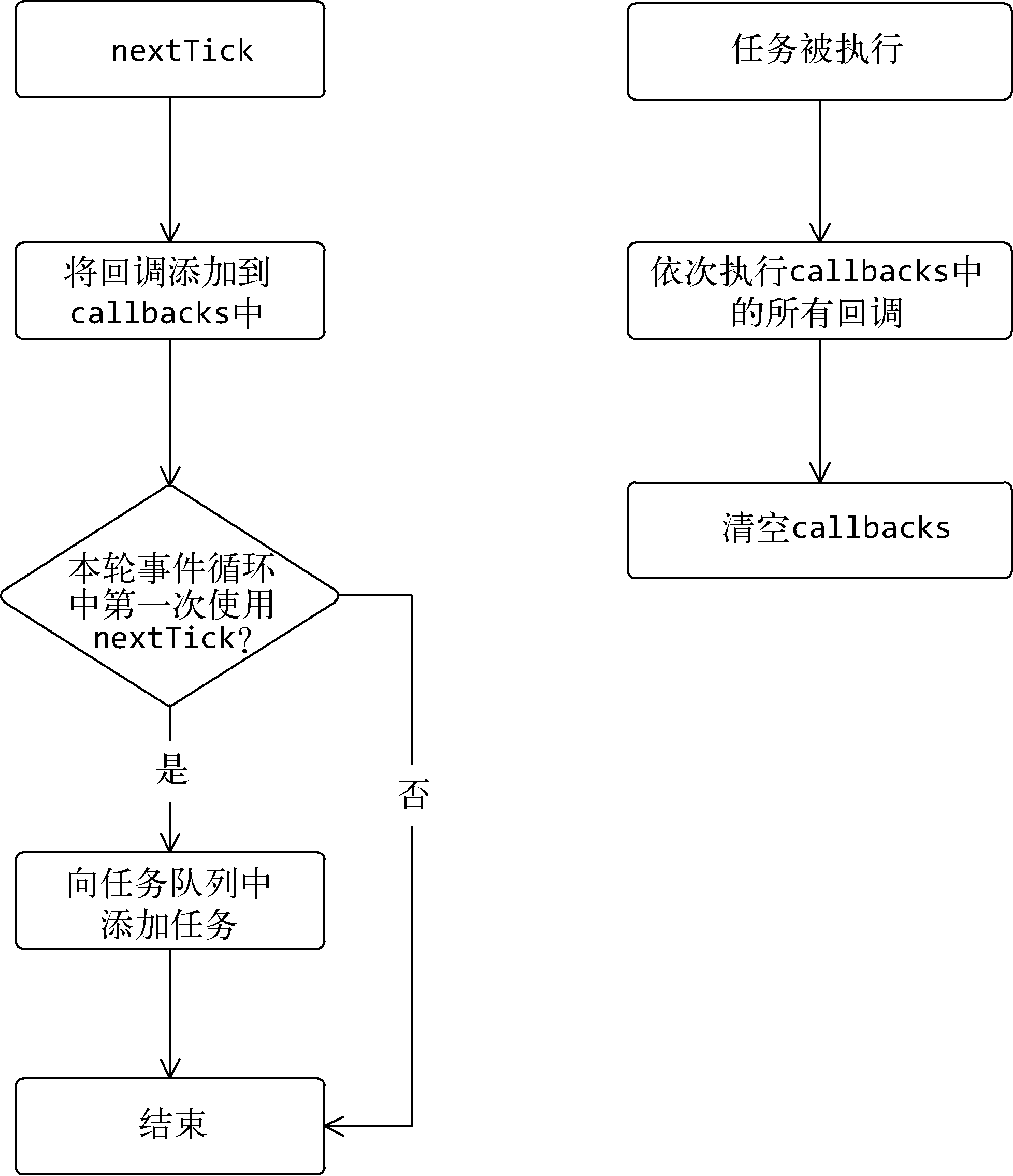
最终完整的代码如下:
1 | const callbacks = [] |
2.3.4 vm.$mount
我们并不常用这个方法,其原因是如果在实例化Vue.js时设置了el选项,会自动把Vue.js实例挂载到DOM元素上。但理解这个方法却非常重要,因为无论我们在实例化Vue.js时是否设置了el选项,想让Vue.js实例具有关联的DOM元素,只有使用vm.$mount方法这一种途径。
使用示例:
1 | let MyComponent = Vue.extend({ |
在不同的构建版本中,vm.$mount的表现都不一样。其差异主要体现在完整版(vue.js)和只包含运行时版本(vue.runtime.js)之间。
完整版和只包含运行时版本之间的差异在于是否有编译器,而是否有编译器的差异主要在于vm.$mount方法的表现形式。在只包含运行时的构建版本中,vm.$mount的作用如前面介绍的那样。而在完整的构建版本中,vm.$mount的作用会稍有不同,它首先会检查template或el选项所提供的模板是否已经转换成渲染函数(render函数)。如果没有,则立即进入编译过程,将模板编译成渲染函数,完成之后再进入挂载与渲染的流程中。
1、首先,来看完整版vm.$mount的实现代码:
1 | // 通过函数劫持,可以在原始功能之上新增一些其他功能 |
我们将Vue原型上的 $mount方法保存在mount中,以便后续使用。然后Vue原型上的 $mount方法被一个新的方法覆盖了。新方法中会调用原始的方法,这种做法通常被称为函数劫持。
接下来,将实现完整版vm.$mount中最主要的功能:编译器。
首先判断Vue.js实例中是否存在渲染函数,只有不存在时,才会将模板编译成渲染函数。其代码如下:
1 | const mount = Vue.prototype.$mount |
在实例化Vue.js时,会有一个初始化流程,其中会向Vue.js实例上新增一些方法,这里的this.$options就是其中之一,它可以访问到实例化Vue.js时用户设置的一些参数,例如template和render。
关于这一点,Vue.js在官方文档的template选项中也给出了相应的提示。如果没有render选项,那么需要获取模板并将模板编译成渲染函数(render函数)赋值给render选项。
我们先介绍获取模板相关的逻辑,代码如下:
1 | const mount = Vue.prototype.$mount |
结合前面的代码,整体逻辑是,如果用户没有通过template选项设置模板,那么会从el选项中获取HTML字符串当作模板。如果用户提供了template选项,那么需要对它进一步解析,因为这个选项支持很多种使用方式。template选项可以直接设置成字符串模板,也可以设置为以#开头的选择符,还可以设置成DOM元素。
将模板编译成代码字符串并将代码字符串转换成渲染函数的过程是在compileToFunctions函数中完成的,该函数的内部实现如下:
1 | function compileToFunctions (template, options, vm) { |
● 1、首先,将options属性混合到空对象中,其目的是让options成为可选参数。
● 2、接下来,检查缓存中是否已经存在编译后的模板。如果模板已经被编译,就会直接返回缓存中的结果,不会重复编译,保证不做无用功来提升性能。
● 3、然后调用compile函数来编译模板。这部分内容就是第三篇中介绍的,将模板编译成代码字符串并存储在compiled中的render属性中,此时该属性中保存的内容类似下面这样:
1 | 'with(this){return _c("div",{attrs:{"id":"el"}},[_v("Hello "+_s(name))])}' |
● 4、接下来,调用createFunction函数将代码字符串转换为函数。其实现原理相当简单,使用new Function(code)就可以完成。
1 | const code = 'console.log("Hello Berwin")' |
● 5、最后,将渲染函数返回给调用方。
2、只包含运行时版本的vm.$mount的实现原理:
下面代码可以看到,$mount方法将ID转换为DOM元素后,使用mountComponent函数将Vue.js实例挂载到DOM元素上。事实上,将实例挂载到DOM元素上指的是将模板渲染到指定的DOM元素中,而且是持续性的,以后当数据(状态)发生变化时,依然可以渲染到指定的DOM元素中。
实现这个功能需要开启watcher。watcher将持续观察模板中用到的所有数据(状态),当这些数据(状态)被修改时它将得到通知,从而进行渲染操作。这个过程会持续到实例被销毁。
1 | Vue.prototype.$mount = function (el) { |
vm._update(vm._render()) 的作用是先调用渲染函数得到一份最新的VNode节点树,然后通过 _update方法对最新的VNode和上一次渲染用到的旧VNode进行对比并更新DOM节点。简单来说,就是执行了渲染操作。
下面我们来回顾一下watcher观察数据的过程:
状态通过Observer转换成响应式之后,每当触发getter时,会从全局的某个属性中获取watcher实例并将它添加到数据的依赖列表中。watcher在读取数据之前,会先将自己设置到全局的某个属性中。而数据被读取会触发getter,所以会将watcher收集到依赖列表中。收集好依赖后,当数据发生变化时,会向依赖列表中的watcher发送通知。
由于Watcher的第二个参数支持函数,所以当watcher执行函数时,函数中所读取的数据都将会触发getter去全局找到watcher并将其收集到函数的依赖列表中。也就是说,函数中读取的所有数据都将被watcher观察。这些数据中的任何一个发生变化时,watcher都将得到通知。
得出了这个结论后,有什么用呢?当数据发生变化时,watcher会一次又一次地执行函数进入渲染流程,如此反复,这个过程会持续到实例被销毁。
挂载完毕后,会触发mounted钩子函数。
2.4 全局API的实现原理
全局API和实例方法不同,后者是在Vue的原型上挂载方法,也就是在Vue.prototype上挂载方法,而前者是直接在Vue上挂载方法。
1 | Vue.extend = function (extendOptions) { |
2.4.1 Vue.extend
用法:使用基础Vue构造器创建一个“子类”,其参数是一个包含“组件选项”的对象。
1 | <div id="mount-point"></div> |
原理:
为了性能考虑,我们在Vue.extend方法内首先增加了缓存策略。反复调用Vue.extend其实应该返回同一个结果。只要返回结果是固定的,就可以将计算结果缓存,再次调用extend方法时,只需要从缓存中取出结果即可。
完整代码如下:
1 | let cid = 1 |
总体来讲,其实就是创建了一个Sub函数并继承了父级。如果直接使用Vue.extend,则Sub继承于Vue构造函数。
2.4.2 Vue.nextTick
用法:在下次DOM更新循环结束之后执行延迟回调,修改数据之后立即使用这个方法获取更新后的DOM。
1 | // 修改数据 |
原理:
1 | import { nextTick } from '../util/index' |
2.4.3 Vue.set
用法:设置对象的属性。如果对象是响应式的,确保属性被创建后也是响应式的,同时触发视图更新。这个方法主要用于避开Vue不能检测属性被添加的限制。
注意 对象不能是Vue.js实例或者Vue.js实例的根数据对象。
1 | // target {object|arrary} |
Vue.set与vm.$set的实现原理相同。
2.4.4 Vue.delete
用法:删除对象的属性。如果对象是响应式的,确保删除能触发更新视图。这个方法主要用于避开Vue.js不能检测到属性被删除的限制。
1 | Vue.delete(target, key) |
2.4.5 Vue.directive
用法:注册或获取全局指令。
1 | // 注册 |
除了核心功能默认内置的指令外(v-model和v-show),Vue.js也允许注册自定义指令。虽然代码复用和抽象的主要形式是组件,但是有些情况下,仍然需要对普通DOM元素进行底层操作,这时就会用到自定义指令。
原理:
1 | // 用于保存指令的位置 |
2.4.6 Vue.filter
用法:注册或获取全局过滤器。
1 | // 注册 |
1 | <!-- 在双花括号中 --> |
原理:
1 | Vue.options['filters'] = Object.create(null) |
2.4.7 Vue.component
用法:注册或获取全局组件。注册组件时,还会自动使用给定的id设置组件的名称。相关代码如下:
1 | // 注册组件,传入一个扩展过的构造器 |
我们在使用Vue.js开发项目时,会经常与组件打交道。在编写组件库时,也经常会用到Vue.component方法。因此,理解组件的注册原理非常重要。
你会发现Vue.directive、Vue.filter和Vue.component这三个方法的实现方式非常相似,代码很多都是重复的。但是为了方便理解,这里我将这三个方法分别拆开单独介绍。事实上,在Vue.js的源码中,这三个方法是放在一起实现的:
1 | Vue.options = Object.create(null) |
2.4.8 Vue.use
用法:安装Vue.js插件。如果插件是一个对象,必须提供install方法。如果插件是一个函数,它会被作为install方法。调用install方法时,会将Vue作为参数传入。install方法被同一个插件多次调用时,插件也只会被安装一次。
原理:
Vue.use的作用是注册插件,此时只需要调用install方法并将Vue作为参数传入即可。但在细节上其实有两部分逻辑需要处理:一部分是插件的类型,可以是install方法,也可以是一个包含install方法的对象;另一部分逻辑是插件只能被安装一次,保证插件列表中不能有重复的插件。其代码如下:
1 | Vue.use = function (plugin) { |
2.4.9 Vue.mixin
用法:全局注册一个混入(mixin),影响注册之后创建的每个Vue.js实例。插件作者可以使用混入向组件注入自定义行为(例如:监听生命周期钩子)。不推荐在应用代码中使用。
1 | // 为自定义的选项myOption注入一个处理器 |
原理:Vue.mixin方法注册后,会影响之后创建的每个Vue.js实例,因为该方法会更改Vue.options属性。
1 | import { mergeOptions } from '../util/index' |
因为mixin方法修改了Vue.options属性,而之后创建的每个实例都会用到该属性,所以会影响创建的每个实例。但也正是因为有影响,所以mixin在某些场景下才堪称神器。
2.4.10 Vue.compile
用法:编译模板字符串并返回包含渲染函数的对象。只在完整版中才有效。
1 | var res = Vue.compile('<div><span>{{ msg }}</span></div>') |
与vm.$mount类似,Vue.compile方法只存在于完整版中。
原理:
Vue.compile = compileToFunctions
2.4.11 Vue.version
用法:
1 | var version = Number(Vue.version.split('.')[0]) |
2.4.12 总结
我们详细介绍了Vue.js的实例方法和全局API的实现原理。它们的区别在于:实例方法是Vue.prototype上的方法,而全局API是Vue.js上的方法。
实例方法又分为数据、事件和生命周期这三个类型。
3、生命周期
每个Vue.js实例在创建时都要经过一系列初始化,例如设置数据监听、编译模板、将实例挂载到DOM并在数据变化时更新DOM等。同时,也会运行一些叫作生命周期钩子的函数,这给了我们在不同阶段添加自定义代码的机会。
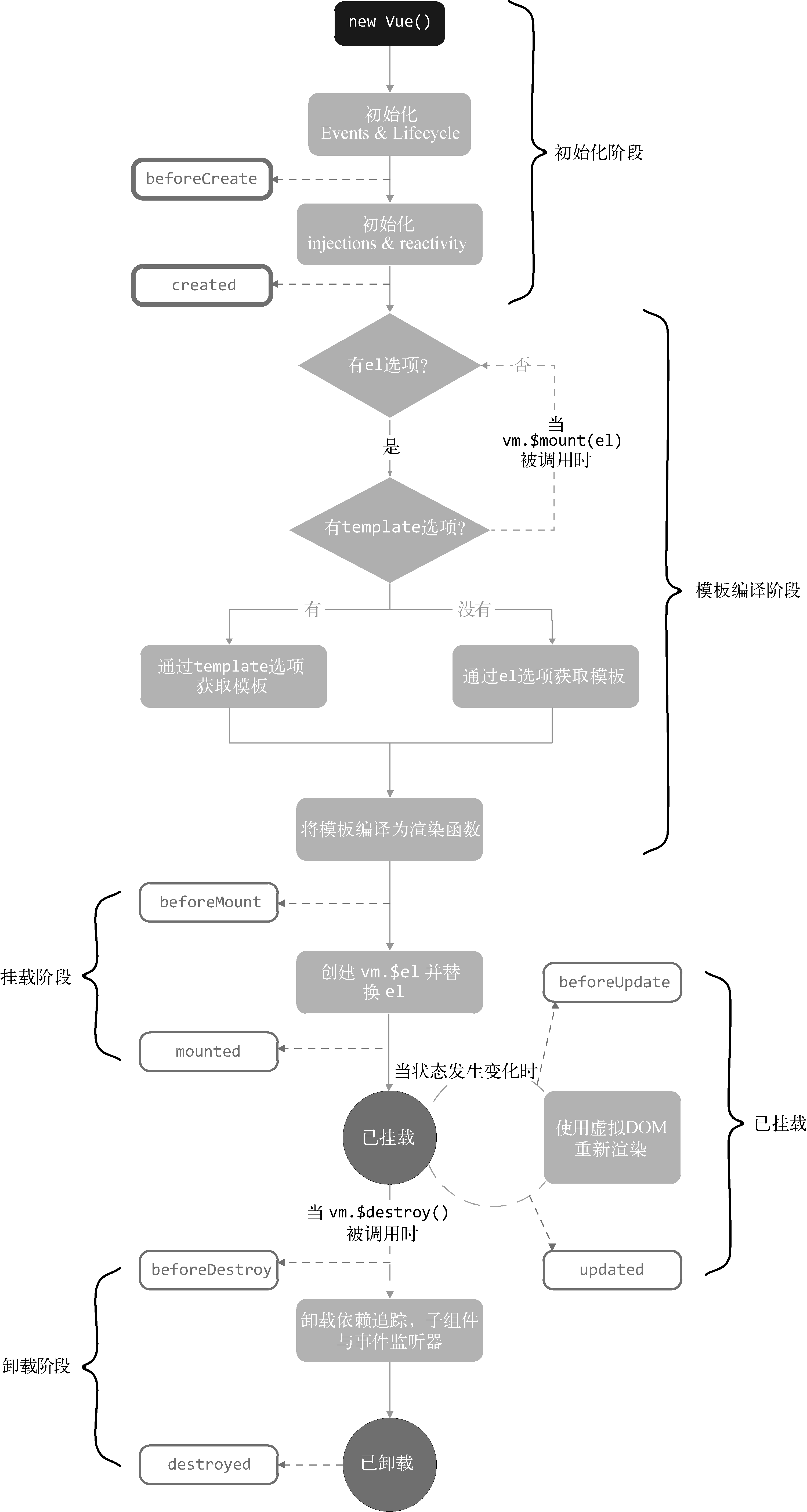
3.1 生命周期示意图
初始化阶段(部分版本有模版编译)、挂载阶段、更新阶段、卸载阶段
3.1.1 初始化
new Vue()到created之间的阶段叫作初始化阶段
这个阶段的主要目的是在Vue.js实例上初始化一些属性、事件以及响应式数据,如props、methods、data、computed、watch、provide和inject等。
3.1.2 模版编译
在created钩子函数与beforeMount钩子函数之间的阶段是模板编译阶段。
这个阶段的主要目的是将模板编译为渲染函数,只存在于完整版中。如果在只包含运行时的构建版本中执行new Vue(),则不会存在这个阶段。
当使用vue-loader或vueify时,*.vue文件内部的模板会在构建时预编译成JavaScript,所以最终打好的包里是不需要编译器的,用运行时版本即可。由于模板这时已经预编译成了渲染函数,所以在生命周期中并不存在模板编译阶段,初始化阶段的下一个生命周期直接是挂载阶段
3.1.3 挂载阶段
beforeMount钩子函数到mounted钩子函数之间是挂载阶段。
在这个阶段,Vue.js会将其实例挂载到DOM元素上,通俗地讲,就是将模板渲染到指定的DOM元素中。在挂载的过程中,Vue.js会开启Watcher来持续追踪依赖的变化。
在已挂载状态下,Vue.js仍会持续追踪状态的变化。当数据(状态)发生变化时,Watcher会通知虚拟DOM重新渲染视图,并且会在渲染视图前触发beforeUpdate钩子函数,渲染完毕后触发updated钩子函数。
通常,在运行时的大部分时间下,Vue.js处于已挂载状态,每当状态发生变化时,Vue.js都会通知组件使用虚拟DOM重新渲染,也就是我们常说的响应式。这个状态会持续到组件被销毁。
3.1.4 卸载阶段
在这个阶段,Vue.js会将自身从父组件中删除,取消实例上所有依赖的追踪并且移除所有的事件监听器。
3.2 从源码角度了解生命周期
new Vue()被调用时发生了什么?
想要了解new Vue()被调用时发生了什么,我们需要知道在Vue构造函数中实现了哪些逻辑。前面介绍过,当new Vue()被调用时,会首先进行一些初始化操作,然后进入模板编译阶段,最后进入挂载阶段。
1 | function Vue (options) { |
_init方法的定义
1 | import { initMixin } from './init' |
_init方法的内部原理
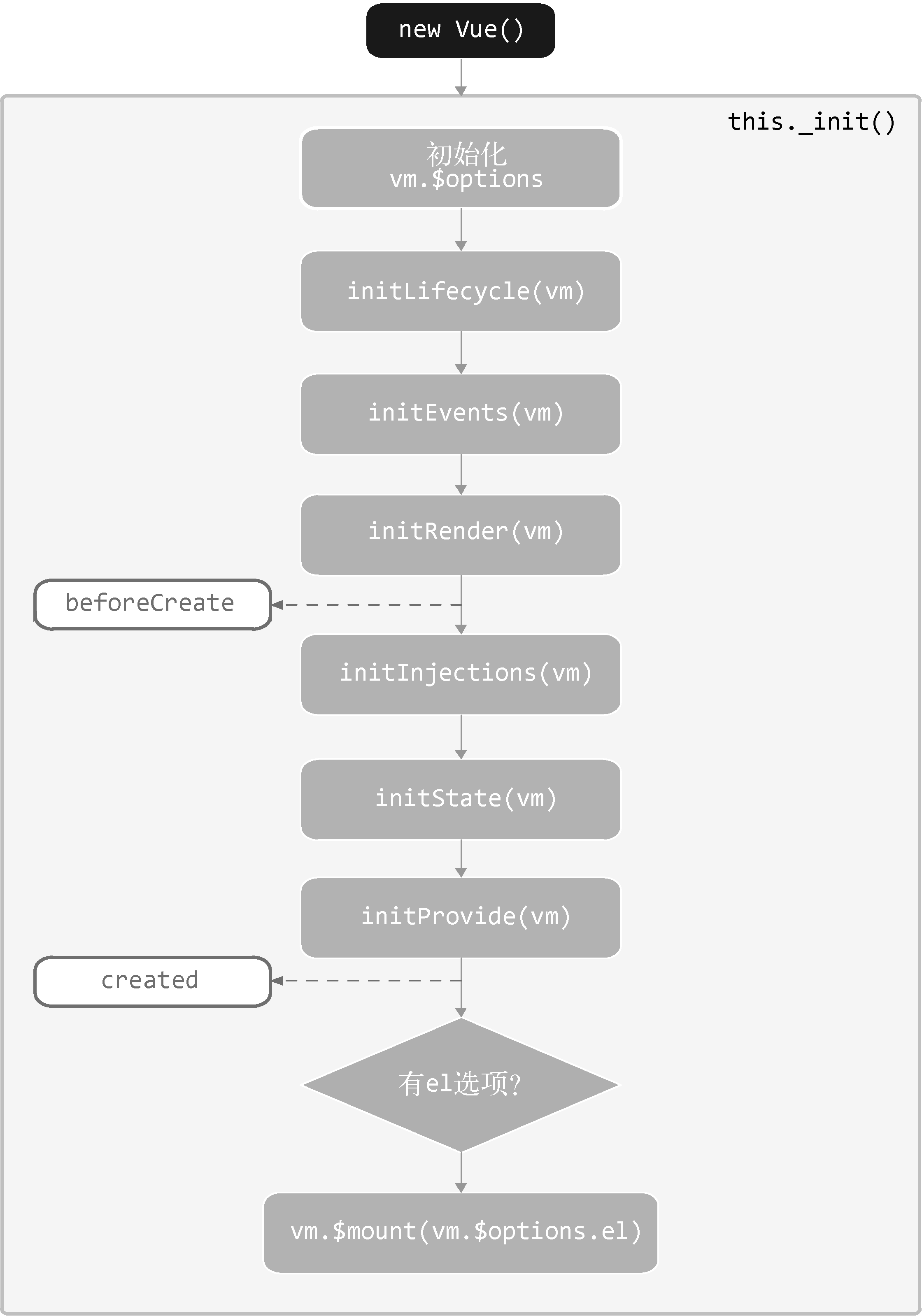
当new Vue()执行后,触发的一系列初始化流程都是在 _init方法中启动的。_init的实现如下:
1 | Vue.prototype._init = function (options) { |
callHook函数的内部原理
Vue.js通过callHook函数来触发生命周期钩子。我们需要理解callHook所实现的功能。callHook的作用是触发用户设置的生命周期钩子,而用户设置的生命周期钩子会在执行new Vue()时通过参数传递给Vue.js。也就是说,可以在Vue.js的构造函数中通过options参数得到用户设置的生命周期钩子。
vue生命周期:
● beforeCreate
● created
● beforeMount
● mounted
● beforeUpdate
● updated
● beforeDestroy
● destroyed
● activated
● deactivated
● errorCaptured
通过vm.$options.created获取的是一个数组,数组中包含了钩子函数,例如:
1 | console.log(vm.$options.created); // [fn] 数组 |
原因:Vue.mixin和用户在实例化Vue.js时,如果设置了同一个生命周期钩子,那么在触发生命周期时,需要同时触发这两个函数。而转换成数组后,可以在同一个生命周期钩子列表中保存多个生命周期钩子。
举个例子:使用Vue.mixin设置生命周期钩子mounted之后,在执行new Vue()时,会在参数中也设置一个生命周期钩子mounted,这时vm.$options.mounted是一个数组,里面包含两个生命周期钩子。
1 | export function callHook (vm, hook) { |
这里使用try…catch语句捕获钩子函数内发生的错误,并使用handleError处理错误。handleError会依次执行父组件的errorCaptured钩子函数与全局的config.errorHandler,这也是为什么生命周期钩子errorCaptured可以捕获子孙组件的错误。关于handleError与生命周期钩子errorCaptured,我们会在随后的内容中详细介绍。
3.3 errorCaptured与错误处理
errorCaptured钩子函数的作用是捕获来自子孙组件的错误,此钩子函数会收到三个参数:错误对象、发生错误的组件实例以及一个包含错误来源信息的字符串。然后此钩子函数可以返回false,阻止该错误继续向上传播。
传播规则如下:
默认情况下,如果全局的config.errorHandler被定义,那么所有的错误都会发送给它,这样这些错误可以在单个位置报告给分析服务。
如果一个组件继承的链路或其父级从属链路中存在多个errorCaptured钩子,则它们将会被相同的错误逐个唤起。
如果errorCaptured钩子函数自身抛出了一个错误,则这个新错误和原本被捕获的错误都会发送给全局的config.errorHandler。
一个errorCaptured钩子函数能够返回false来阻止错误继续向上传播。这本质上是说“这个错误已经被搞定,应该被忽略”。它会阻止其他被这个错误唤起的errorCaptured钩子函数和全局的config.errorHandler。
handleError函数的实现原理并不复杂。根据前面的传播规则,我们先实现第一个需求:将所有错误发送给config.errorHandler。相关代码如下:
1 | export function handleError (err, vm, info) { |
接下来实现第二个功能:如果一个组件继承的链路或其父级从属链路中存在多个errorCaptured钩子函数,则它们将会被相同的错误逐个唤起。
1 | export function handleError (err, vm, info) { |
自底向上的每一层都会读出当前层组件的errorCaptured钩子函数列表,并依次执行列表中的每一个钩子函数。当组件循环到根组件时,从属链路中的多个errorCaptured钩子函数就都被触发完了。此时,我们就不难理解为什么errorCaptured可以捕获来自子孙组件抛出的错误了。
我们实现第三个功能:如果errorCaptured钩子函数自身抛出了一个错误,那么这个新错误和原本被捕获的错误都会发送给全局的config.errorHandler。
1 | export function handleError (err, vm, info) { |
接下来实现最后一个功能:一个errorCaptured钩子函数能够返回false来阻止错误继续向上传播。它会阻止其他被这个错误唤起的errorCaptured钩子函数和全局的config.errorHandler。
1 | export function handleError (err, vm, info) { |
因为一旦钩子函数返回了false,handleError函数将会执行return语句终止程序执行,所以错误向上传递和全局的config.errorHandler都会被停止。
3.4 初始化实例属性
在Vue.js的整个生命周期中,初始化实例属性是第一步。需要实例化的属性既有Vue.js内部需要用到的属性(例如vm._watcher),也有提供给外部使用的属性(例如vm.$parent)。
以 $ 开头的属性是提供给用户使用的外部属性,以 _ 开头的属性是提供给内部使用的内部属性。
Vue.js通过initLifecycle函数向实例中挂载属性,该函数接收Vue.js实例作为参数。所以在函数中,我们只需要向Vue.js实例设置属性即可达到向Vue.js实例挂载属性的目的。代码如下:
1 | export function initLifecycle (vm) { |
稍微有点复杂的是vm.$parent属性,它需要找到第一个非抽象类型的父级,所以代码中会进行判断:如果当前组件不是抽象组件并且存在父级,那么需要通过while来自底向上循环;如果父级是抽象类,那么继续向上,直到遇到第一个非抽象类的父级时,将它赋值给vm.$parent属性。
最后一个值得注意的属性是vm.$root,它表示当前组件树的根Vue.js实例。这个属性的实现原理很巧妙,也很好理解。如果当前组件没有父组件,那么它自己其实就是根组件,它的 $root属性是它自己,而它的子组件的vm.$root属性是沿用父级的$root,所以其直接子组件的 $root属性还是它,其孙组件的 $root属性沿用其直接子组件中的 $root属性,以此类推。因此,我们会发现这其实是自顶向下将根组件的 $root依次传递给每一个子组件的过程。
注意 在真实的Vue.js源码中,内部属性有更多。因为本书介绍的内容没有使用那么多属性,所以为了方便理解,上面代码中并没有给出所有属性
3.5 初始化事件
初始化事件是指将父组件在模板中使用的v-on注册的事件添加到子组件的事件系统(Vue.js的事件系统)中。
我们都知道,在Vue.js中,父组件可以在使用子组件的地方用v-on来监听子组件触发的事件。
1 | <div id="counter-event-example"> |
父组件的模板里使用v-on监听子组件中触发的increment事件,并在子组件中使用this.$emit触发该事件。
对于这个问题,我们需要先简单介绍一下模板编译和虚拟DOM。在模板编译阶段,可以得到某个标签上的所有属性,其中就包括使用v-on或@注册的事件。在模板编译阶段,我们会将整个模板编译成渲染函数,而渲染函数其实就是一些嵌套在一起的创建元素节点的函数。创建元素节点的函数是这样的:_c(tagName, data,children)。当渲染流程启动时,渲染函数会被执行并生成一份VNode,随后虚拟DOM会使用VNode进行对比与渲染。在这个过程中会创建一些元素,但此时会判断当前这个标签究竟是真的标签还是一个组件:如果是组件标签,那么会将子组件实例化并给它传递一些参数,其中就包括父组件在模板中使用v-on注册在子组件标签上的事件;如果是平台标签,则创建元素并插入到DOM中,同时会将标签上使用v-on注册的事件注册到浏览器事件中。
简单来说,如果v-on写在组件标签上,那么这个事件会注册到子组件Vue.js事件系统中;如果是写在平台标签上,例如div,那么事件会被注册到浏览器事件中。
原理:
Vue.js通过initEvents函数来执行初始化事件相关的逻辑,其代码如下:
1 | export function initEvents (vm) { |
首先在vm上新增 _events属性并将它初始化为空对象,用来存储事件。事实上,所有使用vm.$on注册的事件监听器都会保存到vm._events属性中。
在模板编译阶段,当模板解析到组件标签时,会实例化子组件,同时将标签上注册的事件解析成object并通过参数传递给子组件。所以当子组件被实例化时,可以在参数中获取父组件向自己注册的事件,这些事件最终会被保存在vm.$options._parentListeners中。
用前面的例子中举例,vm.$options._parentListeners是下面的样子:
1 | {increment: function () {}} |
通过前面的代码可以看到,如果vm.$options._parentListeners不为空,则调用updateComponentListeners方法,将父组件向子组件注册的事件注册到子组件实例中。
updateComponentListeners的逻辑很简单,只需要循环vm.$options._parentListeners并使用vm.$on把事件都注册到this._events中即可。updateComponentListeners函数的源码如下:
1 | let target |
其中封装了add和remove这两个函数,用来新增和删除事件。此外,还通过updateListeners函数对比listeners和oldListeners的不同,并调用参数中提供的add和remove进行相应的注册事件和卸载事件的操作。它的实现思路并不复杂:如果listeners对象中存在某个key(也就是事件名)在oldListeners中不存在,那么说明这个事件是需要新增的事件;反过来,如果oldListeners中存在某些key(事件名)在listeners中不存在,那么说明这个事件是需要从事件系统中移除的。
updateListeners代码如下:
1 | export function updateListeners (on, oldOn, add, remove, vm) { |
在循环on的过程中,有如下三个判断。
● 判断事件名对应的值是否是undefined或null,如果是,则在控制台触发警告。
● 判断该事件名在oldOn中是否存在,如果不存在,则调用add注册事件。
● 如果事件名在on和oldOn中都存在,但是它们并不相同,则将事件回调替换成on中的回调,并且把on中的回调引用指向真实的事件系统中注册的事件,也就是oldOn中对应的事件。
注意:代码中的isUndef函数用于判断传入的参数是否为undefined或null
代码中还有normalizeEvent函数,它的作用是什么呢?
Vue.js的模板中支持事件修饰符,例如capture、once和passive等,如果我们在模板中注册事件时使用了事件修饰符,那么在模板编译阶段解析标签上的属性时,会将这些修饰符改成对应的符号加在事件名的前面,例如 <child v-on:increment.once=”a”>。此时vm.$options._parentListeners是下面的样子:
1 | {~increment: function () {}} |
可以看到,事件名的前面新增了一个~符号,这说明该事件的事件修饰符是once,我们通过这样的方式来分辨当前事件是否使用了事件修饰符。而normalizeEvent函数的作用是将事件修饰符解析出来,其代码如下:
1 | const normalizeEvent = name => { |
3.6 初始化inject
inject和provide通常是成对出现的
3.6.1 provide/inject的使用方式
说明 provide和inject主要为高阶插件/组件库提供用例,并不推荐直接用于程序代码中。
inject和provide选项需要一起使用,它们允许祖先组件向其所有子孙后代注入依赖,并在其上下游关系成立的时间里始终生效(不论组件层次有多深)。如果你熟悉React,会发现这与它的上下文特性很相似。
inject选项应该是一个字符串数组或对象,其中对象的key是本地的绑定名,value是一个key(字符串或Symbol)或对象,用来在可用的注入内容中搜索。
如果是对象,那么它有如下两个属性。
● name:它是在可用的注入内容中用来搜索的key(字符串或 Symbol)。
● default:它是在降级情况下使用的value
说明 可用的注入内容指的是祖先组件通过provide注入了内容,子孙组件可以通过inject获取祖先组件注入的内容。
1 | // 父组件 |
如果使用ES2015 Symbol作为key,则provide函数和inject对象如下所示:
1 | const s = Symbol() |
3.6.2 inject的内部原理
虽然inject和provide是成对出现的,但是二者在内部的实现是分开处理的,先处理inject后处理provide。inject在data/props之前初始化,而provide在data/props后面初始化。这样做的目的是让用户可以在data/props中使用inject所注入的内容。也就是说,可以让data/props依赖inject,所以需要将初始化inject放在初始化data/props的前面。
初始化inject的方法叫作initInjections,其代码如下:
1 | export function initInjections (vm) { |
其中,resolveInject函数的作用是通过用户配置的inject,自底向上搜索可用的注入内容,并将搜索结果返回。
resolveInject代码:
1 | export function resolveInject (inject, vm) { |
例如,用户设置的inject是这样的:
1 | { |
它被规格化之后是下面这样的:
1 | { |
不论是数组形式还是对象中使用from属性的形式,本质上其实是让用户设置原属性名与当前组件中的属性名。如果用户设置的是数组,那么就认为用户是让两个属性名保持一致。
3.7 初始化状态
当我们使用Vue.js开发应用时,经常会使用一些状态,例如props、methods、data、computed和watch。在Vue.js内部,这些状态在使用之前需要进行初始化。
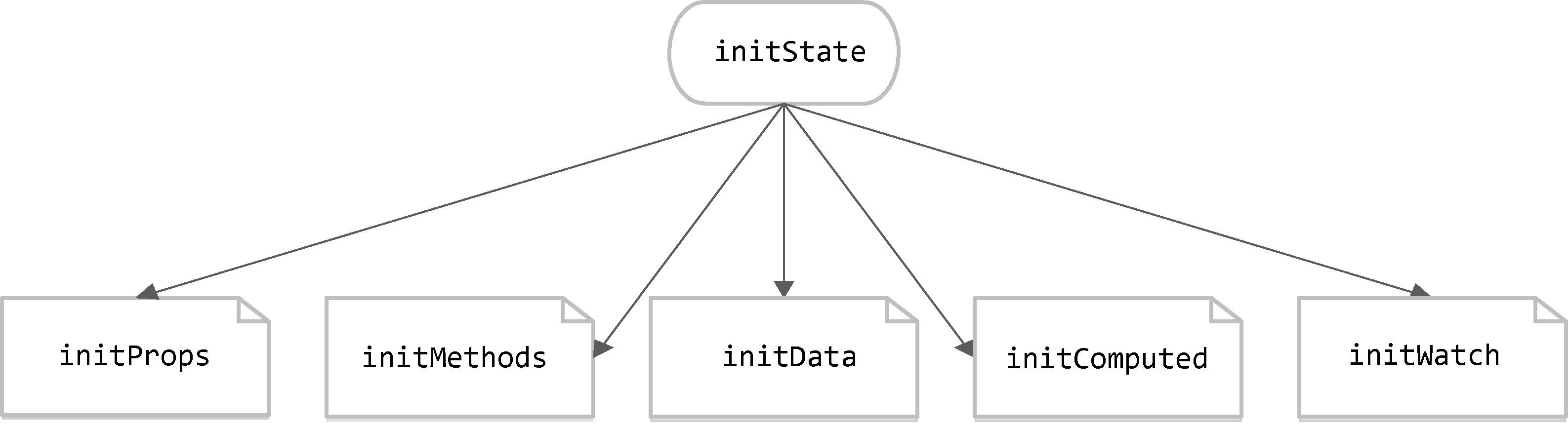
initState函数的代码:
1 | export function initState (vm) { |
如果你足够细心,就会发现初始化的顺序其实是精心安排的。先初始化props,后初始化data,这样就可以在data中使用props中的数据了。在watch中既可以观察props,也可以观察data,因为它是最后被初始化的。
初始化状态可以分为5个子项,分别是初始化props、初始化methods、初始化data、初始化computed和初始化watch:
3.7.1 初始化props
props的实现原理大体上是这样的:父组件提供数据,子组件通过props字段选择自己需要哪些内容,Vue.js内部通过子组件的props选项将需要的数据筛选出来之后添加到子组件的上下文中。
1 | function initProps (vm, propsOptions) { |
validateProp代码:
1 | export function validateProp (key, propOptions, propsData, vm) { |
assertProp函数的代码如下:
1 | function assertProp (prop, name, value, vm, absent) { |
3.7.2 初始化methods
初始化methods时,只需要循环选项中的methods对象,并将每个属性依次挂载到vm上即可,相关代码如下:
1 | function initMethods (vm, methods) { |
当methods的某个方法只有key没有value时,会在控制台发出警告。如果methods中的某个方法已经在props中声明过了,会在控制台发出警告。如果methods中的某个方法已经存在于vm中,并且方法名是以 $ 或 _ 开头的,也会在控制台发出警告。这里isReserved函数的作用是判断字符串是否是以 $ 或 _ 开头。
将方法赋值到vm中很简单,详见initMethods方法的最后一行代码。其中会判断方法(methods[key])是否存在:如果不存在,则将noop赋值到vm[key] 中;如果存在,则将该方法通过bind改写它的this后,再赋值到vm[key] 中。
这样,我们就可以通过vm.x访问到methods中的x方法了
3.7.3 初始化data
简单来说,data中的数据最终会保存到vm._data中。然后在vm上设置一个代理,使得通过vm.x可以访问到vm._data中的x属性。最后由于这些数据并不是响应式数据,所以需要调用observe函数将data转换成响应式数据。于是,data就完成了初始化。
1 | function initData (vm) { |
如果data中的某个key与methods发生了重复,依然会将data代理到实例中,但如果与props发生了重复,则不会将data代理到实例中。
代码中调用了proxy函数实现代理功能。该函数的作用是在第一个参数上设置一个属性名为第三个参数的属性。这个属性的修改和获取操作实际上针对的是与第二个参数相同属性名的属性。proxy的代码如下:
1 | const sharedPropertyDefinition = { |
3.7.4 初始化computed
大家肯定对计算属性computed不陌生,在实际项目中我们会经常用它。但对于刚入门的新手来说,它不是很好理解,它和watch到底有哪些不同呢?
我们知道计算属性的结果会被缓存,且只有在计算属性所依赖的响应式属性或者说计算属性的返回值发生变化时才会重新计算。那么,如何知道计算属性的返回值是否发生了变化?这其实是结合Watcher的dirty属性来分辨的:当dirty属性为true时,说明需要重新计算“计算属性”的返回值;当dirty属性为false时,说明计算属性的值并没有变,不需要重新计算。
当计算属性中的内容发生变化后,计算属性的Watcher与组件的Watcher都会得到通知。计算属性的Watcher会将自己的dirty属性设置为true,当下一次读取计算属性时,就会重新计算一次值。然后组件的Watcher也会得到通知,从而执行render函数进行重新渲染的操作。由于要重新执行render函数,所以会重新读取计算属性的值,这时候计算属性的Watcher已经把自己的dirty属性设置为true,所以会重新计算一次计算属性的值,用于本次渲染。
计算属性的内部原理,在模板中使用了一个数据渲染视图时,如果这个数据恰好是计算属性,那么读取数据这个操作其实会触发计算属性的getter方法(初始化计算属性时在vm上设置的getter方法):
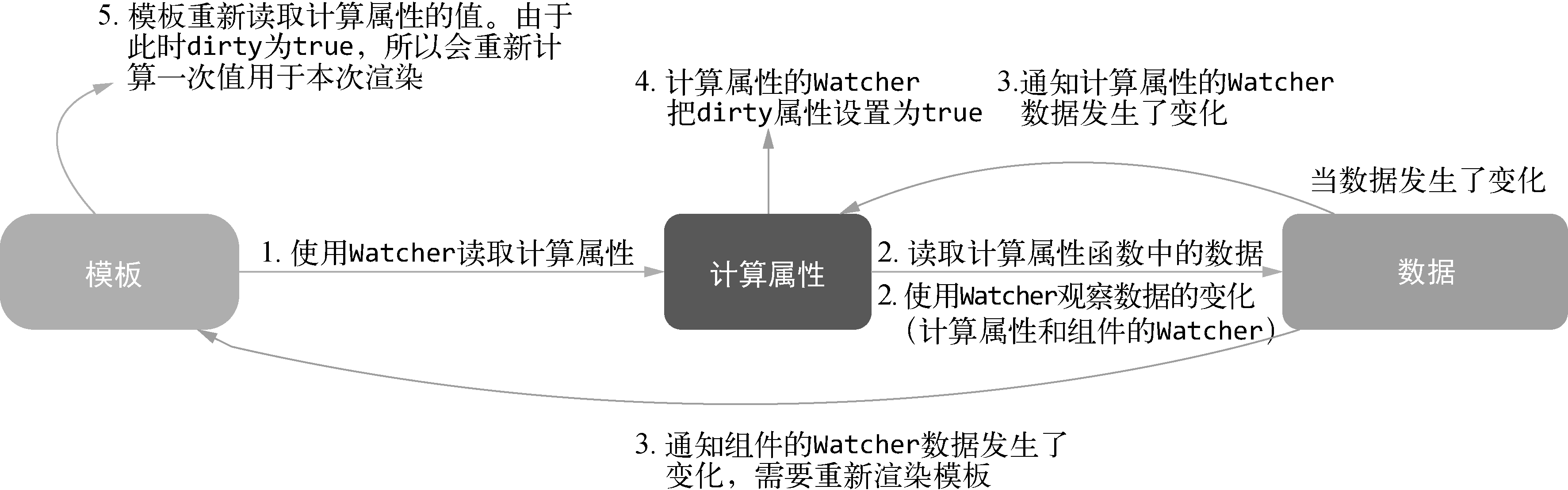
这个getter方法被触发时会做两件事。
● 计算当前计算属性的值,此时会使用Watcher去观察计算属性中用到的所有其他数据的变化。同时将计算属性的Watcher的dirty属性设置为false,这样再次读取计算属性时将不再重新计算,除非计算属性所依赖的数据发生了变化。
● 当计算属性中用到的数据发生变化时,将得到通知从而进行重新渲染操作。
说明 计算属性的一个特点是有缓存。计算属性函数所依赖的数据在没有发生变化的情况下,会反复读取计算属性,而计算属性函数并不会反复执行。
computed具体实现代码:
1 | const computedWatcherOptions = { lazy: true } |
但在Vue.js中,只有与data和props重名时,才会打印警告。如果与methods重名,并不会在控制台打印警告。所以如果与methods重名,计算属性会悄悄失效,我们在开发过程中应该尽量避免这种情况。
还需要说明一下defineComputed函数:
1 | const sharedPropertyDefinition = { |
然后函数中声明了变量shouldCache,它的作用是判断computed是否应该有缓存。这里调用isServerRendering函数来判断当前环境是否是服务端渲染环境。因此,变量shouldCache只有在非服务端渲染环境下才为true。也就是说,只有在非服务端渲染环境下,计算属性才有缓存。
通过前面的介绍,我们发现计算属性的缓存与响应式功能主要在于是否将getter方法设置为createComputedGetter函数执行后的返回结果。下面我们介绍createComputedGetter函数是如何实现缓存以及响应式功能的,其代码如下:
1 | function createComputedGetter (key) { |
如果watcher存在,那么判断watcher.dirty是否为true。前面我们介绍,watcher.dirty属性用于标识计算属性的返回值是否有变化,如果它为true,说明计算属性所依赖的状态发生了变化,它的返回值有可能也会有变化,所以需要重新计算得出最新的结果。
计算属性的缓存就是通过这个判断来实现的。每当计算属性所依赖的状态发生变化时,会将watcher.dirty设置为true,这样当下一次读取计算属性时,会发现watcher.dirty为true,此时会重新计算返回值,否则就直接使用之前的计算结果。
第2章介绍Watcher时,并没有介绍其depend与evaluate方法。事实上,其中定义了depend与evaluate方法专门用于实现计算属性相关的功能,代码如下:
1 | export default class Watcher { |
3.7.5 初始化watch
初始化状态的最后一步是初始化watch。在initState函数的最后,有这样一行代码:
1 | if (opts.watch && opts.watch !== nativeWatch) { |
是因为Firefox浏览器中的Object.prototype上有一个watch方法。当用户没有设置watch时,在Firefox浏览器下的opts.watch将是Object.prototype.watch函数,所以通过这样的语句可以避免这种问题。
使用方法:
1 | var vm = new Vue({ |
由于watch选项的值同时支持字符串、函数、对象和数组类型,不同的类型有不同的用法,所以在调用vm.$watch之前需要对这些类型做一些适配。initWatch函数的代码如下:
1 | function initWatch (vm, watch) { |
createWatcher函数主要负责处理其他类型的handler并调用vm.$watch创建Watcher观察表达式,其代码如下:
1 | function createWatcher (vm, expOrFn, handler, options) { |
3.7.6 初始化provide
初始化provide时,只需要将provide选项添加到vm._provided即可,相关代码如下:
1 | export function initProvide (vm) { |
3.7.7 总结 (new Vue()背后)
本章详细介绍了new Vue()被执行时Vue.js的背后发生了什么。
Vue.js的整体生命周期可以分为4个阶段:初始化阶段、模板编译阶段、挂载阶段和卸载阶段。初始化阶段结束后,会触发created钩子函数。在created钩子函数与beforeMount钩子函数之间的这个阶段是模板编译阶段,这个阶段在不同的构建版本中不一定存在。挂载阶段在beforeMount钩子函数与mounted期间。挂载完毕后,Vue.js处于已挂载阶段。已挂载阶段会持续追踪状态的变化,当数据(状态)发生变化时,Watcher会通知虚拟DOM重新渲染视图。在渲染视图前触发beforeUpdate钩子函数,渲染完毕后触发updated钩子函数。当vm.$destroy被调用时,组件进入卸载阶段。卸载前会触发beforeDestroy钩子函数,卸载后会触发destroyed钩子函数。
new Vue()被执行后,Vue.js进入初始化阶段,然后选择性进入模板编译与挂载阶段。
在初始化阶段,会分别初始化实例属性、事件、provide/inject以及状态等,其中状态又包含props、methods、data、computed与watch。
4、指令的奥秘
4.1 简介
指令(directive)是Vue.js提供的带有v-前缀的特殊特性。指令属性的值预期是单个JavaScript表达式。指令的职责是,当表达式的值改变时,将其产生的连带影响响应式地作用于DOM。
除了自定义指令外,Vue.js还内置了一些常用指令,例如v-if和v-for等。有些内置指令的实现原理与自定义指令不同,它们提供的功能很难用自定义指令实现。
4.2 指令原理
在模板解析阶段,我们在将指令解析到AST,然后使用AST生成代码字符串的过程中实现某些内置指令的功能,最后在虚拟DOM渲染的过程中触发自定义指令的钩子函数使指令生效。
下图给出了让指令生效的全过程。在模板解析阶段,会将节点上的指令解析出来并添加到AST的directives属性中。
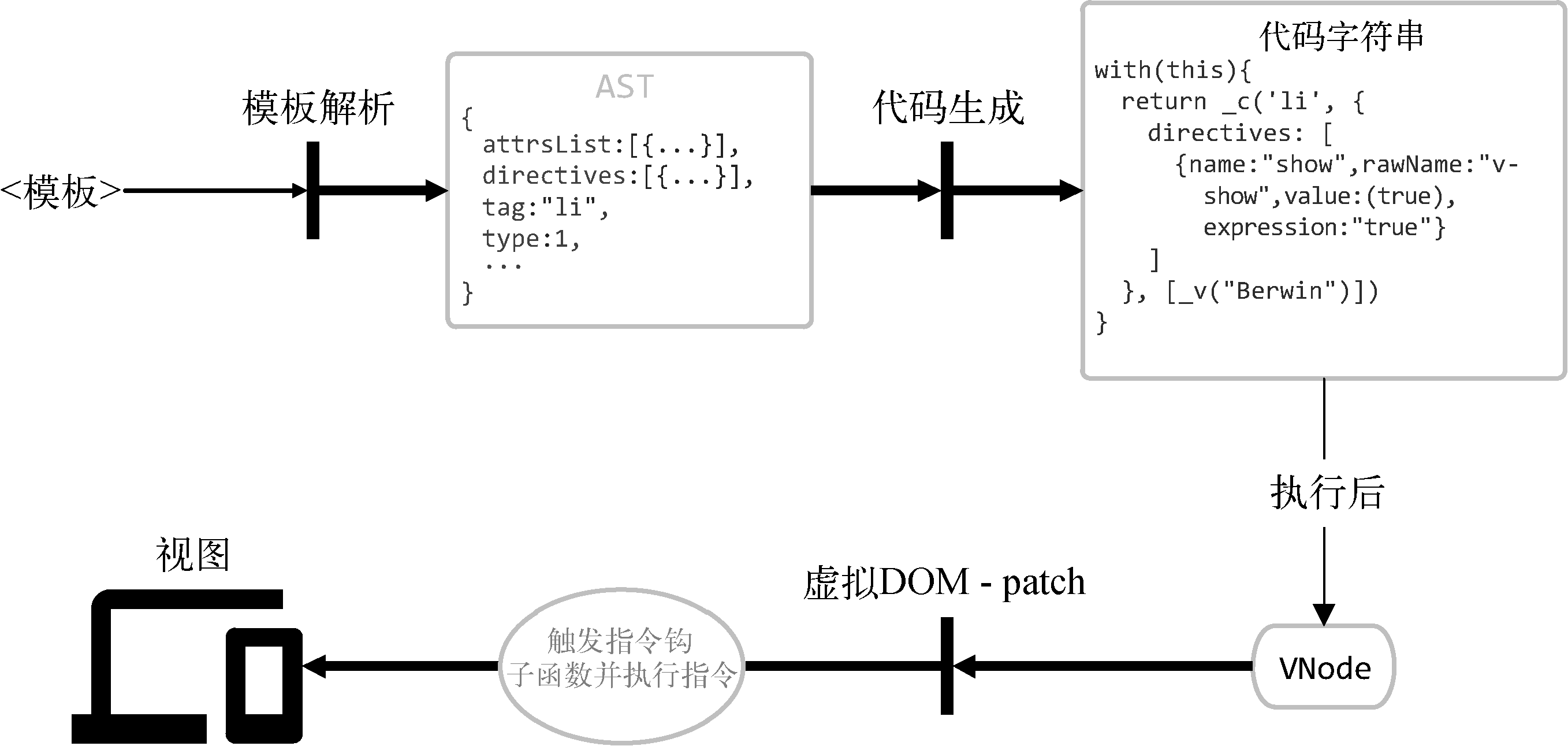
随后directives数据会传递到VNode中,接着就可以通过vnode.data.directives获取一个节点所绑定的指令。
最后,当虚拟DOM进行修补时,会根据节点的对比结果触发一些钩子函数。更新指令的程序会监听create、update和destroy钩子函数,并在这三个钩子函数触发时对VNode和oldVNode进行对比,最终根据对比结果触发指令的钩子函数。(使用自定义指令时,可以监听5种钩子函数:bind、inserted、update、componentUpdated与unbind)
4.2.1 v-if指令的原理概述
有一些内置指令是在模板编译阶段实现的。在代码生成时,通过生成一个特殊的代码字符串来实现指令的功能。
1 | <li v-if="has">if</li> |
在模板编译的代码生成阶段会生成这样的代码字符串:
1 | (has) |
这样一段代码字符串在最终被执行时,会根据has变量的值来选择创建哪个节点。我们发现v-if的内部原理其实和自定义指令不一样。
4.2.2 v-for指令的原理概述
v-for指令也是在模板编译的代码生成阶段实现的。
1 | <li v-for="(item, index) in list">v-for {{index}}</li> |
在模板编译阶段会生成这样的代码字符串:
1 | _l((list), function (item, index) { |
其中,_l是函数renderList的别名。当执行这段代码字符串时,_l函数会循环变量list并依次调用第二个参数所传递的函数。同时,会传递两个参数:item和index。此外,当 _c函数被调用时,会执行 _v函数创建一个文本节点。
可以发现,v-for指令的实现原理和自定义指令也不一样。
4.2.3 v-on指令
它用在普通元素上时,可以监听原生DOM事件;用在自定义元素组件上时,可以监听子组件触发的自定义事件。
例如,在模板中注册一个点击事件:
1 | <button v-on:click="doThat">我是按钮</button> |
在最终生成的VNode中,我们可以通过vnode.data.on读出下面的事件对象:
1 | { |
事件绑定相关的处理逻辑分别设置了create与update钩子函数,也就是说在修补的过程中,每当一个DOM元素被创建或更新时,都会触发事件绑定相关的处理逻辑。
事件绑定相关的处理逻辑是一个叫updateDOMListeners的函数,而create与update钩子函数执行的都是这个函数。其代码如下:
1 | let target |
这个函数接收两个参数:oldVnode与vnode。我们可以通过对比两个VNode中的事件对象,来决定绑定原生DOM事件还是解绑原生DOM事件。
那么,add和remove方法是如何绑定与解绑DOM原生事件的呢?
浏览器提供了一个绑定事件的API,叫作node.addEventListener,我相信大家都不陌生。add方法的代码如下:
1 | function add (event, handler, once, capture, passive) { |
事件监听器使用withMacroTask包了一层,并且如果v-on使用了once修饰符,那么会使用高阶函数createOnceHandler实现once的功能。
withMacroTask函数的作用是给回调函数做一层包装,当事件触发时,如果因为回调中修改了数据而触发更新DOM的操作,那么该更新操作会被推送到宏任务(macrotask)的任务队列中。
前面说过,createOnceHandler函数可以实现once的功能,那么它是如何做到的呢?其代码如下:
1 | function createOnceHandler (handler, event, capture) { |
可以看到,这个createOnceHandler函数就是一个普通的once实现。执行该函数后,会返回函数onceHandler。当执行onceHandler时,会执行handler函数,并执行remove函数来解绑事件,使事件只能被执行一次。
remove方法比add方法简单,它只需要调用浏览器提供的removeEventListener方法将事件解绑即可,其代码如下:
1 | function remove (event, handler, capture, _target) { |
4.3 自定义指令的内部原理
我们知道,虚拟DOM通过算法对比两个VNode之间的差异并更新真实的DOM节点。在更新真实的DOM节点时,有可能是创建新的节点,或者更新一个已有的节点,还有可能是删除一个节点等。虚拟DOM在渲染时,除了更新DOM内容外,还会触发钩子函数。例如,在更新节点时,除了更新节点的内容外,还会触发update钩子函数。这是因为标签上通常会绑定一些指令、事件或属性,这些内容也需要在更新节点时同步被更新。因此,事件、指令、属性等相关处理逻辑只需要监听钩子函数,在钩子函数触发时执行相关处理逻辑即可实现功能。
指令的处理逻辑分别监听了create、update与destroy,其代码如下:
1 | export default { |
虚拟DOM在触发钩子函数时,上面代码中对应的函数会被执行。但无论哪个钩子函数被触发,最终都会执行一个叫作updateDirectives的函数。从代码中可以得知,指令相关的处理逻辑都在updateDirectives函数中实现,该函数的代码如下:
1 | function updateDirectives (oldVnode, vnode) { |
这里通过normalizeDirectives函数将模板中使用的指令从用户注册的自定义指令集合中取出来,最终取到的值为:
1 | { |
自定义指令的代码为:
1 | Vue.directive('focus', { |
最后,介绍一下callHook函数是如何执行指令的钩子函数的,其代码如下:
1 | // dir:指令对象。 |
4.4 虚拟DOM钩子函数
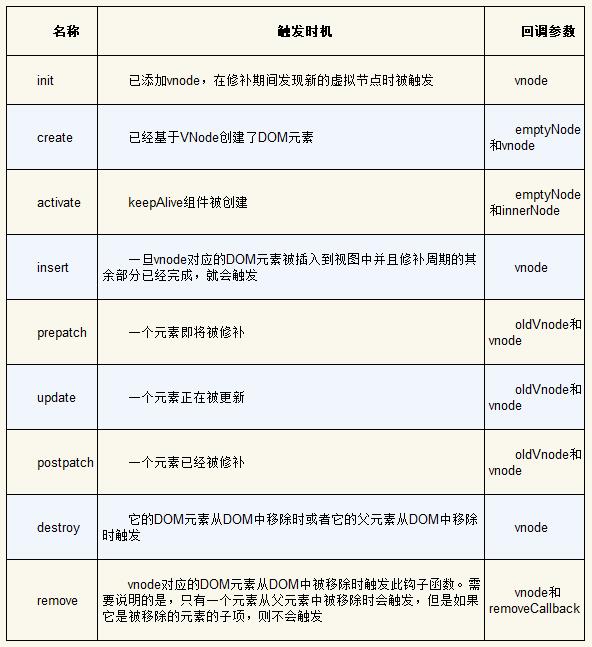
下表给出了虚拟DOM在渲染时会触发的所有钩子函数以及每个钩子函数的触发时机。
虚拟DOM在渲染时会触发的所有钩子函数及其触发时机:
5、过滤器的奥秘
Vue.js允许我们自定义过滤器来格式化文本。它可以用在两个地方:双花括号插值和v-bind表达式(后者从2.1.0+ 开始支持)。它应该被添加在JavaScript表达式的尾部,由“管道”符号指示:
1 | <!-- 在双花括号中 --> |
我们可以在一个组件的选项中定义本地的过滤器:
1 | filters: { |
或者在创建Vue.js实例之前全局定义过滤器:
1 | Vue.filter('capitalize', function (value) { |
过滤器可以串联,下例中,filterA被定义为接收单个参数的过滤器函数,表达式message的值将作为参数传入到filterA过滤器函数中。然后继续调用同样被定义为接收单个参数的过滤器函数filterB,将过滤器函数filterA的执行结果当作参数传递给filterB函数:
1 | {{ message | filterA | filterB }} |
过滤器是JavaScript函数,因此可以接收参数:
1 | {{ message | filterA('arg1', arg2) }} |
这里,filterA被定义为接收三个参数的过滤器函数。其中message的值作为第一个参数,普通字符串 ‘arg1’ 作为第二个参数,表达式arg2的值作为第三个参数。
5.1 过滤器原理概述
1 | {{ message | capitalize }} |
其中 _f函数是resolveFilter的别名,其作用是从this.$options.filters中找出注册的过滤器并返回。因此,上面例子中的 _f(“capitalize”) 与this.$options.filters[‘capitalize’]相同。而this.$options.filters[‘capitalize’] 就是我们注册的capitalize过滤器函数:
1 | filters: { |
_s函数不陌生,第9章中介绍过,它是toString函数的别名。toString函数的代码如下:
1 | function toString (val) { |
简单来说,其实就是执行了capitalize过滤器函数并把message当作参数传递进去,接着将capitalize过滤器处理后的结果当作参数传递给toString函数。最终toString函数执行后的结果会保存到VNode中的text属性中。换句话说,这个返回结果直接被拿去渲染视图了。
5.1.1 串联过滤器
1 | {{ message | capitalize | suffix }} |
我们定义的本地过滤器如下:
1 | filters: { |
最终在模板编译阶段会编译成下面的样子:
1 | _s(_f("suffix")(_f("capitalize")(message))) |
5.1.2 滤器接收参数
1 | {{message|capitalize|suffix('!')}} |
设置了参数的过滤器最终被编译后变成这样:
1 | _s(_f("suffix")(_f("capitalize")(message),'!')) |
5.1.3 resolveFilter的内部原理
_f函数是resolveFilter函数的别名。resolveFilter函数的代码如下:
1 | import { identity, resolveAsset } from 'core/util/index' |
现在我们比较关心resolveAsset函数如何查找过滤器,其代码如下:
1 | export function resolveAsset (options, type, id, warnMissing) { |
5.2 解析过滤器
现在我们已经了解了过滤器内部是如何执行的,但是并不了解模板中的过滤器语法是如何编译成过滤器函数来调用表达式的。例如下面的过滤器:
1 | {{ message | capitalize }} |
在Vue.js内部,src/compiler/parser/filter-parser.js文件中提供了一个parseFilters函数,专门用来解析过滤器,它可以将模板过滤器解析成过滤器函数调用表达式。这个逻辑并不复杂,我们只需要在解析出过滤器列表后,循环过滤器列表并拼接一个字符串即可。其代码如下:
1 | export function parseFilters (exp) { |
5.3 总结
过滤器的原理是:在编译阶段将过滤器编译成函数调用,串联的过滤器编译后是一个嵌套的函数调用,前一个过滤器函数的执行结果是后一个过滤器函数的参数。
编译后的 _f函数是resolveFilter函数的别名,resolveFilter函数的作用是找到对应的过滤器并返回。
最后,介绍了在模板编译过程中过滤器是如何被编译成过滤器函数调用的。简单来说,编译过滤器的过程也分两步:解析和拼接字符串。
6、最佳实践
6.1 为列表渲染设置属性key
我们在介绍虚拟DOM时提到,在更新子节点时,需要从旧虚拟节点列表中查找与新虚拟节点相同的节点进行更新。如果这个查找过程设置了属性key,那么查找速度会快很多。所以无论何时,建议大家尽可能地在使用v-for时提供key,除非遍历输出的DOM内容非常简单,或者是刻意依赖默认行为以获取性能上的提升
1 | <div v-for="item in items" :key="item.id"> |
6.2 在v-if/v-if-else/v-else中使用key
如果一组v-if+v-else的元素类型相同,最好使用属性key(比如两个 <div> 元素)。
在第15章中,我们简单介绍了v-if指令在编译后是下面的样子:
1 | (has) |
所以当状态发生变化时,生成的虚拟节点既有可能是v-if上的虚拟节点,也有可能是v-else上的虚拟节点。
默认情况下,Vue.js会尽可能高效地更新DOM。这意味着,当它在相同类型的元素之间切换时,会修补已存在的元素,而不是将旧的元素移除,然后在同一位置添加一个新元素。如果本不相同的元素被识别为相同,则会出现意料之外的副作用。
如果添加了属性key,那么在比对虚拟DOM时,则会认为它们是两个不同的节点,于是会将旧元素移除并在相同的位置添加一个新元素,从而避免意料之外的副作用。
推荐做法:
1 | <div |
6.3 路由切换组件不变
在使用Vue.js开发项目时,最常遇到的一个典型问题就是,当页面切换到同一个路由但不同参数的地址时,组件的生命周期钩子并不会重新触发。
1 | const routes = [ |
当我们从路由/detail/1切换到/detail/2时,组件是不会发生任何变化的。
这是因为vue-router会识别出两个路由使用的是同一个组件从而进行复用,并不会重新创建组件,因此组件的生命周期钩子自然也不会被触发。
组件本质上是一个映射关系,所以先销毁再重建一个相同的组件会存在很大程度上的性能浪费,复用组件才是正确的选择。但是这也意味着组件的生命周期钩子不会再被调用。
我相信大家都遇到过这个场景,下面总结了3个方法来解决这个问题。
6.3.1 路由导航守卫beforeRouteUpdate
vue-router提供了导航守卫beforeRouteUpdate,该守卫在当前路由改变且组件被复用时调用,所以可以在组件内定义路由导航守卫来解决这个问题。
组件的生命周期钩子虽然不会重新触发,但是路由提供的beforeRouteUpdate守卫可以被触发。因此,只需要把每次切换路由时需要执行的逻辑放到beforeRouteUpdate守卫中即可。例如,在beforeRouteUpdate守卫中发送请求拉取数据,更新状态并重新渲染视图。这种方式是我最推荐的一种方式
6.3.2 观察 $route对象的变化
路由:/user?id=4&page=2。
1 | const User = { |
6.3.3 为router-view组件添加属性key
这种做法非常取巧,非常“暴力”,但非常有效。它本质上是利用虚拟DOM在渲染时通过key来对比两个节点是否相同的原理。通过给router-view组件设置key,可以使每次切换路由时的key都不一样,让虚拟DOM认为router-view组件是一个新节点,从而先销毁组件,然后再重新创建新组件。即使是相同的组件,但是如果url变了,key就变了,Vue.js就会重新创建这个组件。
因为组件是新创建的,所以组件内的生命周期会重复触发
1 | <router-view :key="$route.fullPath"></router-view> |
这种方式的坏处很明显,每次切换路由组件时都会被销毁并且重新创建,非常浪费性能。其优点更明显,简单粗暴,改动小。为router-view组件设置了key之后,立刻就可以看到问题被解决了。
6.4 为所有路由统一添加query
如果路由上的query中有一些是从上游链路上传下来的,那么需要在应用的任何路由中携带,但是在所有跳转路由的地方都设置一遍会非常麻烦。例如,在应用中的所有路由上都加上参数:https://berwin.me/a?referer=hao360cn和https://berwin.me/b?referer=hao360cn。
6.4.1 使用全局守卫beforeEach
事实上,全局守卫beforeEach并不具备修改query的能力,但可以在其中使用next方法来中断当前导航,并切换到新导航,添加一些新query进去。
当然,单单这样做会出问题,因为在进入新导航后,依然会被全局守卫beforeEach拦截,然后再次开启新导航,从而导致无限循环。解决办法是在beforeEach中判断这个全局添加的参数在路由对象中是否存在,如果存在,则不开启新导航:
1 | const query = {referer: 'hao360cn'} |
6.4.2 使用函数劫持
这种方式的原理是:通过拦截router.history.transitionTo方法,在vue-router内部在切换路由之前将参数添加到query中。其使用方式如下:
1 | const query = {referer: 'hao360cn'} |
代码中,先将vue-router内部的router.history.transitionTo方法缓存到变量transitionTo中。随后使用一个新的函数重写router.history.transitionTo方法,通过在函数中修改参数来达到全局添加query参数的目的。当执行缓存的原始方法时,将修改后的参数传递进去即可。
6.5 区分Vuex与props的使用边界
通常,在项目开发中,业务组件会使用Vuex维护状态,使用不同组件统一操作Vuex中的状态。这样不论是父子组件间的通信还是兄弟组件间的通信,都很容易。
对于通用组件,我会使用props以及事件进行父子组件间的通信(通用组件不需要兄弟组件间的通信)。这样做是因为通用组件会拿到各个业务组件中使用,它要与业务解耦,所以需要使用props获取状态。
6.6 避免v-if和v-for一起使用
Vue.js官方强烈建议不要把v-if和v-for同时用在同一个元素上。
通常,我们在下面两种常见的情况下,会倾向于不同的做法。
● 为了过滤一个列表中的项目(比如v-for=”user in users” v-if=”user.isActive”),请将users替换为一个计算属性(比如activeUsers),让它返回过滤后的列表。
● 为了避免渲染本应该被隐藏的列表(比如v-for=”user in users” v-if=”shouldShow-Users”),请将v-if移动至容器元素上(比如ul和ol)。
对于第一种情况,Vue.js官方给出的解释是:**当Vue.js处理指令时,v-for比v-if具有更高的优先级,所以即使我们只渲染出列表中的一小部分元素,也得在每次重渲染的时候遍历整个列表,而不考虑活跃用户是否发生了变化。**通过将列表更换为在一个计算属性上遍历并过滤掉不需要渲染的数据,我们将会获得如下好处。
- 过滤后的列表只会在数组发生相关变化时才被重新运算,过滤更高效。
- 使用v-for=”user in activeUsers”之后,我们在渲染时只遍历活跃用户,渲染更高效。
- 解耦渲染层的逻辑,可维护性(对逻辑的更改和扩展)更强。
1 | <ul> |
优化为:
1 | <ul> |
对于第二种情况,官方解释是为了获得同样的好处,可以把:
1 | <ul> |
优化为:
1 | <ul v-if="shouldShowUsers"> |
6.7 为组件样式设置作用域
对于应用来说,最佳实践是只有顶级App组件和布局组件中的样式可以是全局的,其他所有组件都应该是有作用域的。
6.8 避免在scoped中使用元素选择器
在scoped样式中,类选择器比元素选择器更好,因为大量使用元素选择器是很慢的。
为了给样式设置作用域,Vue.js会为元素添加一个独一无二的特性,例如data-v-f3f3eg9。然后修改选择器,使得在匹配选择器的元素中,只有带这个特性的才会真正生效(比如button[data-v-f3f3eg9])。
6.9 避免隐性的父子组件通信
我们应该优先通过prop和事件进行父子组件之间的通信,而不是使用this.$parent或改变prop。
一个理想的Vue.js应用是“prop向下传递,事件向上传递”。遵循这一约定会让你的组件更容易理解。然而,在一些边界情况下,prop的变更或this.$parent能够简化两个深度耦合的组件。
问题在于,这种做法在很多简单的场景下可能会更方便。但要注意,不要为了一时方便(少写代码)而牺牲数据流向的简洁性(易于理解)。
6.10 模板中简单的表达式
组件模板应该只包含简单的表达式,复杂的表达式则应该重构为计算属性或方法
复杂的表达式会让模板变得不是那么声明式。我们应该尽量描述理应出现的是什么,而非如何计算那个值。而且计算属性和方法使得代码可以重用。
1 | {{ |
优化为
1 | <!-- 在模板中 --> |
6.11 简单的计算属性
应该把复杂的计算属性分隔为尽可能多更简单的属性。简单、命名得当的计算属性具有以下特点。
● 易于测试:当每个计算属性都包含一个非常简单且很少依赖的表达式时,撰写测试以确保其正确工作会更加容易
● 易于阅读:简化计算属性要求你为每一个值都起一个描述性的名称,即便它不可复用。这使得开发者更容易专注在代码上并搞清楚发生了什么。
● 更好地“拥抱变化”:任何能够命名的值都可能用在视图上。举个例子,我们可能打算展示一个信息,告诉用户他们存了多少钱;也可能打算计算税费,但是可能会分开展现,而不是作为总价的一部分。
较小的、专注的计算属性减少了信息使用时的假设性限制,所以需求变更时也不需要那么多重构了。
1 | computed: { |
优化为:
1 | computed: { |