1、javascript重点概念
1.1 javascript的基本数据类型介绍
基本数据类型:Undefined、Null、Boolean、Number、String、Symbol
引用数据类型:Object、Function、Array、Date等类型
1.1.1 Undefined类型
Undefined类型只有一个唯一的字面值undefined,表示的是一个变量不存在。
下面是4种常见的出现undefined的场景:
- 使用只声明而未初始化的变量时,会返回“undefined”。
- 获取一个对象的某个不存在的属性(自身属性和原型链继承属性)时,会返回“undefined”。
- 函数没有明确的返回值时,却在其他地方使用了返回值,会返回“undefined”。
- 函数定义时使用了多个形式参数(后文简称为形参),而在调用时传递的参数的数量少于形参数量,那么未匹配上的参数就为“undefined”
1.1.2 Null类型
Null类型只有一个唯一的字面值null,表示一个空指针对象,这也是在使用typeof运算符检测null值时会返回“object”的原因.
下面是3种常见的出现null的场景:
- 一般情况下,如果声明的变量是为了以后保存某个值,则应该在声明时就将其赋值为“null”。
- JavaScript在获取DOM元素时,如果没有获取到指定的元素对象,就会返回“null”。
- 在使用正则表达式进行捕获时,如果没有捕获结果,就会返回“null”。
1.1.3 Undefined和Null两种类型的异同
相同点:
- Undefined和Null两种数据类型都只有一个字面值,分别是undefined和null。
- Undefined类型和Null类型在转换为Boolean类型的值时,都会转换为false。所以通过非运算符(!)获取结果为true的变量时,无法判断其值为undefined还是null。
- 在需要将两者转换成对象时,都会抛出一个TypeError的异常,也就是平时最常见的引用异常。
- Undefined类型派生自Null类型,所以在非严格相等的情况下,两者是相等的,如下面代码所示。
不同点:
- null是JavaScript中的关键字,而undefined是JavaScript中的一个全局变量,即挂载在window对象上的一个变量,并不是关键字。
- 在使用typeof运算符检测时,Undefined类型的值会返回“undefined”,而Null类型的值会返回“object”。
- 在通过call调用toString()函数时,Undefined类型的值会返回“[object Undefined]”,而Null类型的值会返回“[object Null]”。
- 在需要进行数值类型的转换时,undefined会转换为NaN,无法参与计算;null会转换为0,可以参与计算。
- 无论在什么情况下都没有必要将一个变量显式设置为undefined。如果需要定义某个变量来保存将来要使用的对象,应该将其初始化为null。这样不仅能将null作为空对象指针的惯例,还有助于区分null和undefined。
1.1.4 Boolean类型
(1)String类型转换为Boolean类型
- 空字符串””或者’’都会转换为false。
- 任何非空字符串都会转换为true,包括只有空格的字符串” “。
(2)Object类型转换为Boolean类型
- 当object为null时,会转换为false。
- 如果object不为null,则都会转换为true,包括空对象{}。
1.2 Number类型
在JavaScript中,Number类型的数据既包括了整型数据,也包括了浮点型数据。
① 八进制:如果想要用八进制表示一个数值,那么首位必须是0,其他位必须是0~7的八进制序列。如果后面位数的字面值大于7,则破坏了八进制数据表示规则,前面的0会被忽略,当作十进制数据处理。
1 | var num1 = 024; // 20 2*8+4*1 |
② 十六进制: 如果想要用十六进制表示一个数值,那么前两位必须是0x,其他位必须是十六进制序列(0~9,a~f或者A~F)。如果超过了十六进制序列,则会抛出异常。
1 | var num3 = 0x3f; // 63 3×16+15 |
Null类型转换为Number类型
Null类型只有一个字面值null,直接转换为0。
Undefined类型转换为Number类型
Undefined类型只有一个字面值undefined,直接转换为NaN。
Object类型转换为Number类型
Object类型在转换为Number类型时,会优先调用valueOf()函数,然后通过valueOf()函数的返回值按照上述规则进行转换。如果转换的结果是NaN,则调用toString()函数,通过toString()函数的返回值重新按照上述规则进行转换;如果有确定的Number类型返回值,则结束,否则返回“NaN”。
1.2.1 Number类型转换
1.2.1.1 Number()函数
Number()函数可以用于将任何类型转换为Number类型,它在转换时遵循下列规则。
① 如果是数字,会按照对应的进制数据格式,统一转换为十进制并返回。
1 | Number(10); // 10 |
② 如果是Boolean类型的值,true将返回为“1”,false将返回为“0”。
③ 如果值为null,则返回“0”。
1 | Number(null); // 0 |
④ 如果值为undefined,则返回“NaN”。
1 | Number(undefined); // NaN |
⑤ 如果值为字符串类型,则遵循下列规则。
· 如果该字符串只包含数字,则会直接转换成十进制数;如果数字前面有0,则会直接忽略这个0。
· 如果字符串是有效的浮点数形式,则会直接转换成对应的浮点数,前置的多个重复的0会被清空,只保留一个。
· 如果字符串是有效的十六进制形式,则会转换为对应的十进制数值。
1 | Number('0x12'); // 18 |
· 如果字符串是有效的八进制形式,则不会按照八进制转换,而是直接按照十进制转换并输出,因为前置的0会被直接忽略。
1 | Number('010'); // 10 |
⑥ 如果值为对象类型,则会先调用对象的valueOf()函数获取返回值,并将返回值按照上述步骤重新判断能否转换为Number类型。如果都不满足,则会调用对象的toString()函数获取返回值,并将返回值重新按照步骤判断能否转换成Number类型。如果也不满足,则返回“NaN”。
以下是通过valueOf()函数将对象正确转换成Number类型的示例。
1 | var obj = { |
以下是通过toString()函数将对象正确转换成Number类型的示例。
1 | ar obj = { |
以下示例是通过valueOf()函数和toString()函数都无法将对象转换成Number类型的示例(最后返回“NaN”)。
1 | var obj = { |
如果toString()函数和valueOf()函数返回的都是对象类型而无法转换成基本数据类型,则会抛出类型转换的异常。
1 | var obj = { |
1.2.1.2 parseInt()函数
在使用parseInt()函数将字符串转换成整数时,需要注意以下5点。
- (1)非字符串类型转换为字符串类型
如果遇到传入的参数是非字符串类型的情况,则需要将其优先转换成字符串类型,即使传入的是整型数据。
1 | parseInt('0x12', 16); // 18 |
第一条语句直接将字符串”0x12”转换为十六进制数,得到的结果为1×16+2=18;
第二条语句由于传入的是十六进制数,所以会先转换成十进制数18,然后转换成字符串”18”,再将字符串”18”转换成十六进制数,得到的结果为1×16+8=24。
- (2)数据截取的前置匹配原则
parseInt()函数在做转换时,对于传入的字符串会采用前置匹配的原则。即从字符串的第一个字符开始匹配,如果处于基数指定的范围,则保留并继续往后匹配满足条件的字符,直到某个字符不满足基数指定的数据范围,则从该字符开始,舍弃后面的全部字符。在获取到满足条件的字符后,将这些字符转换为整数。
1 | parseInt("fg123", 16); // 15 |
对于字符串’fg123’,首先从第一个字符开始,’f’是满足十六进制的数据,因为十六进制数据范围是0~9,a~f(A~F),所以保留’f’;然后是第二个字符’g’,它不满足十六进制数据范围,因此从第二个字符至最后一个字符全部舍弃,最终字符串只保留字符’f’;然后将字符’f’转换成十六进制的数据,为15,因此最后返回的结果为“15”。
如果遇到的字符串是以”0x”开头的,那么在按照十六进制处理时,会计算后面满足条件的字符串;如果按照十进制处理,则会直接返回“0”。
1 | parseInt('0x12',16); // 18 = 16 + 2 |
需要注意的一点是,如果传入的字符串中涉及算术运算,则不执行,算术符号会被当作字符处理;如果传入的参数是算术运算表达式,则会先运算完成得到结果,再参与parseInt()函数的计算。
1 | parseInt(15 * 3, 10); // 45,先运算完成得到45,再进行parseInt(45, 10)的运算 |
- (3)对包含字符e的不同数据的处理差异
1 | parseInt(6e3, 10); // 6000 |
第一条语句parseInt(6e3, 10),首先会执行6e3=6000,然后转换为字符串”6000”,实际执行的语句是parseInt(‘6000’, 10),表示的是将字符串”6000”转换为十进制的整数,得到的结果为6000。
第二条语句parseInt(6e3, 16),首先会执行6e3=6000,然后转换为字符串”6000”,实际执行的语句是parseInt(‘6000’, 16),表示的是将字符串”6000”转换为十六进制的数,得到的结果是6×163 = 24576。
第三条语句parseInt(‘6e3’, 10),表示的是将字符串’6e3’转换为十进制的整数,因为字符’e’不在十进制所能表达的范围内,所以会直接省略,实际处理的字符串只有”6”,得到的结果为6。
第四条语句parseInt(‘6e3’, 16),表示的是将字符串’6e3’转换为十六进制的整数,因为字符’e’在十六进制所能表达的范围内,所以会转换为14进行计算,最后得到的结果为6×162 +14×16 + 3 = 1763。
- (4)对浮点型数的处理
如果传入的值是浮点型数,则会忽略小数点及后面的数,直接取整。
1 | parseInt('6.01', 10); // 6 |
经过上面的详细分析,我们再来看看以下语句的执行结果。以下语句都会返回“15”,这是为什么呢?
1 | parseInt("0xF", 16); // 十六进制的F为15,返回“15” |
- (5)map()函数与parseInt()函数的隐形坑
设想这样一个场景,存在一个数组,数组中的每个元素都是Number类型的字符串[‘1’,’2’, ‘3’, ‘4’],如果我们想要将数组中的元素全部转换为整数,我们该怎么做呢?
我们可能会想到在Array的map()函数中调用parseInt()函数,代码如下。
1 | var arr = ['1', '2', '3', '4']; |
但是在运行后,得到的结果是[1, NaN, NaN, NaN],与我们期望的结果[1, 2, 3, 4]差别很大,这是为什么呢?
上面的代码实际与下面的代码等效。
1 | arr.map(function (val, index) { |
任何整数以0为基数取整时,都会返回本身,所以第一行代码会返回“1”。
1.2.1.3 parseFloat()函数
① 如果在解析过程中遇到了正负号(+ / -)、数字0~9、小数点或者科学计数法(e / E)以外的字符,则会忽略从该字符开始至结束的所有字符,然后返回当前已经解析的字符的浮点数形式。
1 | parseFloat('+1.2'); // 1.2 |
② 字符串前面的空白符会直接忽略,如果第一个字符就无法解析,则会直接返回“NaN”。
1 | parseFloat(' 1.2'); // 1.2 |
③ 对于字符串中出现的合法科学运算符e,进行运算处理后会转换成浮点型数,这点与parseInt()函数的处理有很大的不同。
1 | parseFloat('4e3'); // 4000 |
④ 对于小数点,只能正确匹配第一个,第二个小数点是无效的,它后面的字符也都将被忽略。
1 | parseFloat('11.20'); // 11.2 |
下面是使用parseFloat()函数的综合实例。
1 | parseFloat("123AF"); // 123,匹配字符串'123' |
1.2.1.4 结论
· Number()函数转换的是传入的整个值,并不是像parseInt()函数和parseFloat()函数一样会从首位开始匹配符合条件的值。如果整个值不能被完整转换,则会返回“NaN”。
· parseFloat()函数在解析小数点时,会将第一个小数点当作有效字符,而parseInt()函数在解析时如果遇到小数点会直接停止,因为小数点不是整数的一部分。
· parseFloat()函数在解析时没有进制的概念,而parseInt()函数在解析时会依赖于传入的基数做数值转换。
1.2.2 isNaN()函数与Number.isNaN()函数对比
Number类型数据中存在一个比较特殊的数值NaN(Not a Number),它表示应该返回数值却并未返回数值的情况。
NaN存在的目的是在某些异常情况下保证程序的正常执行。例如0/0,在其他语言中,程序会直接抛出异常,而在JavaScript中会返回“NaN”,程序可以正常执行。
NaN有两个很明显的特点,第一个是任何涉及NaN的操作都会返回“NaN”,第二个是NaN与任何值都不相等,即使是与NaN本身相比。
1 | NaN == NaN; // false |
在判断NaN时,ES5提供了isNaN()函数,ECMAScript 6(后续简称ES6)为Number类型增加了静态函数isNaN()。
1.2.2.1 isNaN()函数
1 | isNaN(NaN); // true |
1.2.2.2 Number.isNaN()函数
既然在全局环境中有isNaN()函数,为什么在ES6中会专门针对Number类型增加一个isNaN()函数呢?
这是因为isNaN()函数本身存在误导性,而ES6中的Number.isNaN()函数会在真正意义上去判断变量是否为NaN,不会做数据类型转换。只有在传入的值为NaN时,才会返回“true”,传入其他任何类型的值时会返回“false”。
1 | Number.isNaN(NaN); // true |
上面代码运行后,除了传入NaN会返回“true”以外,传入其他的值都会返回“false”。如果在非ES6环境中想用ES6中的isNaN()函数,该怎么办呢?我们有以下兼容性处理方案。
1 | // 兼容性处理 |
1.2.2.3 总结
· isNaN()函数在判断是否为NaN时,需要先进行数据类型转换,只有在无法转换为数字时才会返回“true”;
· Number.isNaN()函数在判断是否为NaN时,只需要判断传入的值是否为NaN,并不会进行数据类型转换。
1.2.3 浮点型运算
在JavaScript中,整数和浮点数都属于Number类型,它们都统一采用64位浮点数进行存储
虽然它们存储数据的方式是一致的,但是在进行数值运算时,却会表现出明显的差异性。整数参与运算时,得到的结果往往会和我们所想的一样,而对于浮点型运算,有时却会出现一些意想不到的结果,如下面的代码所示。
1 | // 加法 |
得到这样的结果,大家是不是觉得很奇怪呢?0.1 + 0.2为什么不是等于0.3,而是等于0.30000000000000004呢?接下来我们一探究竟。
1.2.3.1 浮点运算不准确原因
首先我们来看看一个浮点型数在计算机中的表示,它总共长度是64位,其中最高位为符号位,接下来的11位为指数位,最后的52位为小数位,即有效数字的部分。
· 第0位:符号位sign表示数的正负,0表示正数,1表示负数。
· 第1位到第11位:存储指数部分,用e表示。
· 第12位到第63位:存储小数部分(即有效数字),用f表示,如图1-1所示。
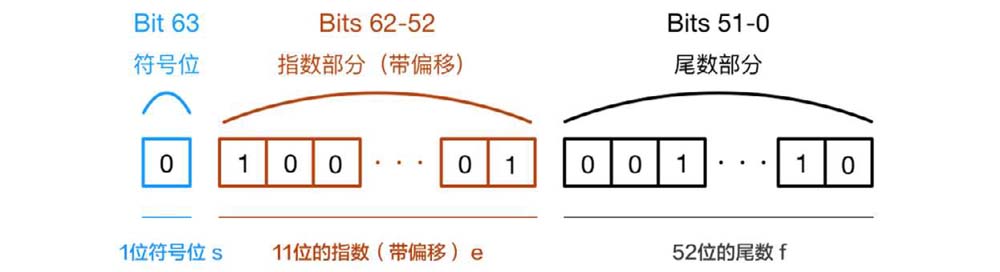
因为浮点型数使用64位存储时,最多只能存储52位的小数位,对于一些存在无限循环的小数位浮点数,会截取前52位,从而丢失精度,所以会出现上面实例中的结果。
1.2.3.2 浮点运算计算过程
接下来以0.1 + 0.2 = 0.30000000000000004的运算为例,看看为什么会得到这个计算结果。
首先将各个浮点数的小数位按照“乘2取整,顺序排列”的方法转换成二进制表示。
具体做法是用2乘以十进制小数,得到积,将积的整数部分取出;然后再用2乘以余下的小数部分,又得到一个积;再将积的整数部分取出,如此推进,直到积中的小数部分为零为止。
然后把取出的整数部分按顺序排列起来,先取的整数作为二进制小数的高位有效位,后取的整数作为低位有效位,得到最终结果。
0.1转换为二进制表示的计算过程如下。
1 | 0.1 * 2 = 0.2 //取出整数部分0 |
1.2取出整数部分1后,剩余小数为0.2,与这一轮运算的第一位相同,表示这将是一个无限循环的计算过程。
1 | 0.2 * 2 = 0.4 //取出整数部分0 |
因此0.1转换成二进制表示为0.0 0011 0011 0011 0011 0011 0011……(无限循环)。
同理对0.2进行二进制的转换,计算过程与上面类似,直接从0.2开始,相比于0.1,少了第一位的0,其余位数完全相同,结果为0.0011 0011 0011 0011 0011 0011……(无限循环)。
将0.1与0.2相加,然后转换成52位精度的浮点型表示。
1 | 0.0001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 (0.1) |
1.2.3.3 解决方案
这里提供一种方法,主要思路是将浮点数先乘以一定的数值转换为整数,通过整数进行运算,然后将结果除以相同的数值转换成浮点数后返回。
下面提供一套用于做浮点数加减乘除运算的代码。
1 | const operationObj = { |
1.3 String类型
JavaScript中的String类型(字符串类型)既可以通过双引号””表示,也可以通过单引号’’表示,而且是完全等效的,这点与Java、PHP等语言在字符串的处理上是不同的。
如果是引用类型的数据,则在转换时总是会调用toString()函数,得到不同类型值的字符串表示;如果是基本数据类型,则会直接将字面值转换为字符串表示形式。例如null值和undefined值转换为字符串时,会直接返回字面值,分别是”null”和”undefined”。
1.3.1 String类型的定义与调用
在JavaScript中,有3种定义字符串的方式,分别是字符串字面量,直接调用String()函数与new String()构造函数。
- 字符串字面量
1 | var str = 'hello JavaScript'; // 正确写法 |
- 直接调用String()函数
① 如果是Number类型的值,则直接转换成对应的字符串。
1 | String(123); // '123' |
② 如果是Boolean类型的值,则直接转换成’true’或者’false’。
1 | String(true); // 'true' |
③ 如果值为null,则返回字符串’null’;
1 | String(null); // 'null' |
④ 如果值为undefined,则返回字符串’undefined’;
1 | String(undefined); // 'undefined' |
⑤ 如果值为字符串,则直接返回字符串本身;
1 | String('this is a string'); // 'this is a string' |
⑥ 如果值为引用类型,则会先调用toString()函数获取返回值,将返回值按照上述步骤①~⑤判断能否转换字符串类型,如果都不满足,则会调用对象的valueOf()函数获取返回值,并将返回值重新按照步骤①~⑤判断能否转换成字符串类型,如果也不满足,则会抛出类型转换的异常。
以下是通过toString()函数将对象正确转换成String类型的示例:
1 | var obj = { |
以下是通过valueOf()函数将对象正确转换成String类型的示例:
1 | var obj = { |
如果toString()函数和valueOf()函数返回的都是对象类型而无法转换成原生类型时,则会抛出类型转换的异常:
1 | var obj = { |
- new String()构造函数
new String()构造函数使用new运算符生成String类型的实例,对于传入的参数同样采用和上述String()函数一样的类型转换策略,最后的返回值是一个String类型对象的实例。
1 | new String('hello JavaScript'); // String {"hello JavaScript"} |
- 三者在作比较时的区别
基本字符串在作比较时,只需要比较字符串的值即可;而在比较字符串对象时,比较的是对象所在的地址。
1 | var str = 'hello'; |
对于str4、str5和str6,因为是使用new运算符生成的String类型的实例,所以在比较时需要判断变量是否指向同一个对象,即内存地址是否相同,很明显str4、str5、str6都是在内存中新生成的地址,彼此各不相同。
- 函数的调用
在String对象的原型链上有一系列的函数,例如indexOf()函数、substring()函数、slice()函数等,通过String对象的实例可以调用这些函数做字符串的处理。
但是我们发现,采用字面量方式定义的字符串没有通过new运算符生成String对象的实例也能够直接调用原型链上的函数。
这是为什么呢?
实际上基本字符串本身是没有字符串对象的函数,而在基本字符串调用字符串对象才有的函数时,JavaScript会自动将基本字符串转换为字符串对象,形成一种包装类型,这样基本字符串就可以正常调用字符串对象的方法了。
1.3.2 String类型常见算法
1.3.2.1 字符串逆序输出
给定一个字符串’abcdefg’,执行一定的算法后,输出的结果为’gfedcba’。
- 算法1
算法1的主要思想是借助数组的reverse()函数。
首先将字符串转换为字符数组,然后通过调用数组原生的reverse()函数进行逆序,得到逆序数组后再通过调用join()函数得到逆序字符串。
1 | // 算法1:借助数组的reverse()函数 |
- 算法2
算法2的主要思想是利用字符串本身的charAt()函数。
从尾部开始遍历字符串,然后利用charAt()函数获取字符并逐个拼接,得到最终的结果。charAt()函数接收一个索引数字,返回该索引位置对应的字符。
1 | // 算法2:利用charAt()函数 |
- 算法3
算法3的主要思想是通过递归实现逆序输出,与算法2的处理类似。
递归从字符串最后一个位置索引开始,通过charAt()函数获取一个字符,并拼接到结果字符串中,递归结束的条件是位置索引小于0。
1 | // 算法3:递归实现 |
- 算法4
算法4的主要思想是通过call()函数来改变slice()函数的执行主体。
调用call()函数后,可以让字符串具有数组的特性,在调用未传入参数的slice()函数后,得到的是一个与自身相等的数组,从而可以直接调用reverse()函数,最后再通过调用join()函数,得到逆序字符串。
1 | // 算法4: 利用call()函数 |
- 算法5
算法5的主要思想是借助栈的先进后出原则
由于JavaScript并未提供栈的实现,我们首先需要实现一个栈的数据结构,然后在栈中添加插入和弹出的函数,利用插入和弹出方法的函数字符串逆序。
首先,我们来看下基本数据结构——栈的实现。通过一个数组进行数据存储,通过一个top变量记录栈顶的位置,随着数据的插入和弹出,栈顶位置动态变化。
栈的操作包括两种,分别是出栈和入栈。出栈时,返回栈顶元素,即数组中索引值最大的元素,然后top变量减1;入栈时,往栈顶追加元素,然后top变量加1。
1 | // 栈 |
1 | // 算法5:自定义栈实现 |
1.3.2.2 统计字符串中出现次数最多的字符及出现的次数
假如存在一个字符串’helloJavascripthellohtmlhellocss’,其中出现次数最多的字符是l,出现的次数是7次。
- 算法1
算法1的主要思想是通过key-value形式的对象来存储字符串以及字符串出现的次数,然后逐个判断出现次数最大值,同时获取对应的字符,具体实现如下。
· 首先通过key-value形式的对象来存储数据,key表示不重复出现的字符,value表示该字符出现的次数。
· 然后遍历字符串的每个字符,判断是否出现在key中。如果在,直接将对应的value值加1;如果不在,则直接新增一组key-value,value值为1
· 得到key-value对象后,遍历该对象,逐个比较value值的大小,找出其中最大的值并记录key-value,即获得最终想要的结果。
1 | // 算法1 |
- 算法2
算法2同样会借助于key-value形式的对象来存储字符与字符出现的次数,但是在运算上有所差别。
· 首先通过key-value形式的对象来存储数据,key表示不重复出现的字符,value表示该字符出现的次数。
· 然后将字符串处理成数组,通过forEach()函数遍历每个字符。在处理之前需要先判断当前处理的字符是否已经在key-value对象中,如果已经存在则表示已经处理过相同的字符,则无须处理;如果不存在,则会处理该字符item。
· 通过split()函数传入待处理字符,可以得到一个数组,该数组长度减1即为该字符出现的次数。
· 获取字符出现的次数后,立即与表示出现最大次数和最大次数对应的字符变量maxCount和maxCountChar相比,如果比maxCount大,则将值写入key-value对象中,并动态更新maxCount和maxCountChar的值,直到最后一个字符处理完成。
· 最后得到的结果即maxCount和maxCountChar两个值。
1 | // 算法2 |
- 算法3
算法3的主要思想是对字符串进行排序,然后通过lastIndexOf()函数获取索引值后,判断索引值的大小以获取出现的最大次数。
· 首先将字符串处理成数组,调用sort()函数进行排序,处理成字符串。
· 然后遍历每个字符,通过调用lastIndexOf()函数,确定每个字符出现的最后位置,然后减去当前遍历的索引,就可以确定该字符出现的次数。
· 确定字符出现的次数后,直接与次数最大值变量maxCount进行比较,如果比maxCount大,则直接更新maxCount的值,并同步更新maxCountChar的值;如果比maxCount小,则不做任何处理。
· 计算完成后,将索引值设置为字符串出现的最后位置,进行下一轮计算,直到处理完所有字符。
1 | // 算法3 |
- 算法4
算法4的主要思想是将字符串进行排序,然后通过正则表达式将字符串进行匹配拆分,将相同字符组合在一起,最后判断字符出现的次数。
· 首先将字符串处理成数组,调用sort()函数进行排序,处理成字符串。
· 然后设置正则表达式reg,对字符串使用match()函数进行匹配,得到一个数组,数组中的每个成员是相同的字符构成的字符串。
· 遍历数组,依次将成员字符串长度值与maxCount值进行比较,动态更新maxCount与maxCountChar的值,直到数组所有元素处理完成。
1 | // 算法4 |
- 算法5
算法5的主要思想是借助replace()函数,主要实现方式如下。
· 通过while循环处理,跳出while循环的条件是字符串长度为0。
· 在while循环中,记录原始字符串的长度originCount,用于后面做长度计算处理。
· 获取字符串第一个字符char,通过replace()函数将char替换为空字符串’’,得到一个新的字符串,它的长度remainCount相比于originCount会小,其中的差值originCount - remainCount即为该字符出现的次数。
· 确定字符出现的次数后,直接与maxCount进行比较,如果比maxCount大,则直接更新maxCount的值,并同步更新maxCountChar的值;如果比maxCount小,则不做任何处理。
· 处理至跳出while循环,得到最终结果。
1 | // 算法5 |
1.3.2.3 去除字符串中重复的字符
假如存在一个字符串’helloJavaScripthellohtmlhellocss’,其中存在大量的重复字符,例如h、e、l等,去除重复的字符,只保留一个,得到的结果应该是’heloJavscriptm’。
- 算法1
算法1的主要思想是使用key-value类型的对象存储,key表示唯一的字符,处理完后将所有的key拼接在一起即可得到去重后的结果。
· 首先通过key-value形式的对象来存储数据,key表示不重复出现的字符,value为boolean类型的值,为true则表示字符出现过。
· 然后遍历字符串,判断当前处理的字符是否在对象中,如果在,则不处理;如果不在,则将该字符添加到结果数组中。
· 处理完字符串后,得到一个数组,转换为字符串后即可获得最终需要的结果。
1 | // 算法1 |
- 算法2
算法2的主要思想是借助数组的filter()函数,然后在filter()函数中使用indexOf()函数判断。
· 通过call()函数改变filter()函数的执行体,让字符串可以直接执行filter()函数。
· 在自定义的filter()函数回调中,通过indexOf()函数判断其第一次出现的索引位置,如果与filter()函数中的index一样,则表示第一次出现,符合条件则return出去。这就表示只有第一次出现的字符会被成功过滤出来,而其他重复出现的字符会被忽略掉。
· filter()函数返回的结果便是已经去重的字符数组,将其转换为字符串输出即为最终需要的结果。
1 | // 算法2 |
借助于ES6的语法,以上方法体的执行代码还可以简写成一行的形式。
1 | return Array.prototype.filter.call(str, (char, index, arr) => arr.indexOf |
- 算法3
算法3的主要思想是借助ES6中的Set数据结构,Set具有自动去重的特性,可以直接将数组元素去重。
· 将字符串处理成数组,然后作为参数传递给Set的构造函数,通过new运算符生成一个Set的实例。
· 将Set通过扩展运算符(…)转换成数组形式,最终转换成字符串获得需要的结果。
1 | // 算法3 |
1.3.2.4 判断一个字符串是否为回文字符串
回文字符串是指一个字符串正序和倒序是相同的,例如字符串’abcdcba’是一个回文字符串,而字符串’abcedba’则不是一个回文字符串。
需要注意的是,这里不区分字符大小写,即a与A在判断时是相等的。
给定两个字符串’abcdcba’和’abcedba’,经过一定的算法处理,分别会返回“true”和“false”。
- 算法1
算法1的主要思想是将字符串按从前往后顺序的字符与按从后往前顺序的字符逐个进行比较,如果遇到不一样的值则直接返回“false”,否则返回“true”。
1 | // 算法1 |
- 算法2
算法2与算法1的主要思想相同,将正序和倒序的字符逐个进行比较,与算法1不同的是,算法2采用递归的形式实现。
递归结束的条件有两种情况,一个是当字符串全部处理完成,此时返回“true”;另一个是当遇到首字符与尾字符不同,此时返回“false”。而其他情况会依次进行递归处理。
1 | // 算法2 |
- 算法3
算法3的主要思想是将字符串进行逆序处理,然后与原来的字符串进行比较,如果相等则表示是回文字符串,否则不是回文字符串。
1 | // 算法3 |
1.4 运算符
1.4.1 等于运算符
不同于其他编程语言,JavaScript中相等的比较分为双等于(==)比较和三等于(===)比较。这是因为在Java、C等强类型语言中,一个变量在使用前必须声明变量类型,所以在比较的时候就无须判断变量类型,只需要有双等于即可。
· 双等于运算符在比较时,会将两端的变量进行隐式类型转换,然后比较值的大小。
· 三等于运算符在比较时,会优先比较数据类型,数据类型相同才去判断值的大小,如果类型不同则直接返回“false”。
1.4.1.1 三等于运算符
① 如果比较的值类型不相同,则直接返回“false”。
1 | 1 === '1'; // false |
需要注意的是,基本类型数据存在包装类型。在未使用new操作符时,简单类型的比较实际为值的比较,而使用了new操作符后,实际得到的是引用类型的值,在判断时会因为类型不同而直接返回“false”。
1 | 1 === Number(1); // true |
② 如果比较的值都是数值类型,则直接比较值的大小,相等则返回“true”,否则返回“false”。需要注意的是,如果参与比较的值中有任何一方为NaN,则返回“false”。
1 | 23 === 23; // true |
③ 如果比较的值都是字符串类型,则判断每个位置的字符是否一样,如果一样则返回“true”,否则返回“false”。
1 | 'kingx' === 'kingx'; // true |
④ 如果比较的值都是Boolean类型,则两者同时为true或者false时,返回“true”,否则返回“false”。
1 | false === false; // true |
⑤ 如果比较的值都是null或者undefined,则返回“true”;如果只有一方为null或者undefined,则返回“false”。
1 | null === null; // true |
⑥ 如果比较的值都是引用类型,则比较的是引用类型的地址,当两个引用指向同一个地址时,则返回“true”,否则返回“false”。
1 | var a = []; |
实际上,如果不是通过赋值运算符(=)将定义的引用类型的值赋予变量,那么引用类型的值在比较后都会返回“false”,所以我们会发现空数组或者空对象的直接比较返回的是“false”。
1 | [] === []; // false |
引用类型变量的比较还有一个很明显的特点,即只要有一个变量是通过new操作符得到的,都会返回“false”,包括基本类型的包装类型。
1 | 'hello' === new String('hello'); // false |
1.4.1.2 双等于运算符
相比于三等于运算符,双等于运算符在进行相等比较时,要略微复杂,因为它不区分数据类型,而且会做隐式类型转换。
① 如果比较的值类型相同,则采用与三等于运算符一样的规则。
② 如果比较的值类型不同,则会按照下面的规则进行转换后再进行比较。
· 如果比较的一方是null或者undefined,只有在另一方是null或者undefined的情况下才返回“true”,否则返回“false”。
1 | null == undefined; // true |
· 如果比较的是字符串和数值类型数据,则会将字符串转换为数值后再进行比较,如果转换后的数值相等则返回“true”,否则返回“false”。
1 | 1 == '1'; // true |
需要注意的是,如果字符串是十六进制的数据,会转换为十进制后再进行比较。
1 | '0x15' == 21; // true |
字符串’0x15’实际为十六进制数,转换为十进制后为1×16 + 5 = 21,与21比较后返回“true”。
字符串并不支持八进制的数据,如果字符串以0开头,则0会直接省略,后面的值当作十进制返回。
1 | '020' == 16; // false |
· 如果任一类型是boolean值,则会将boolean类型的值进行转换,true转换为1,false转换为0,然后进行比较。
1 | '1' == true; // true |
· 如果其中一个值是对象类型,另一个值是基本数据类型或者对象类型,则会调用对象的valueOf()函数或者toString()函数,将其转换成基本数据类型后再作比较,
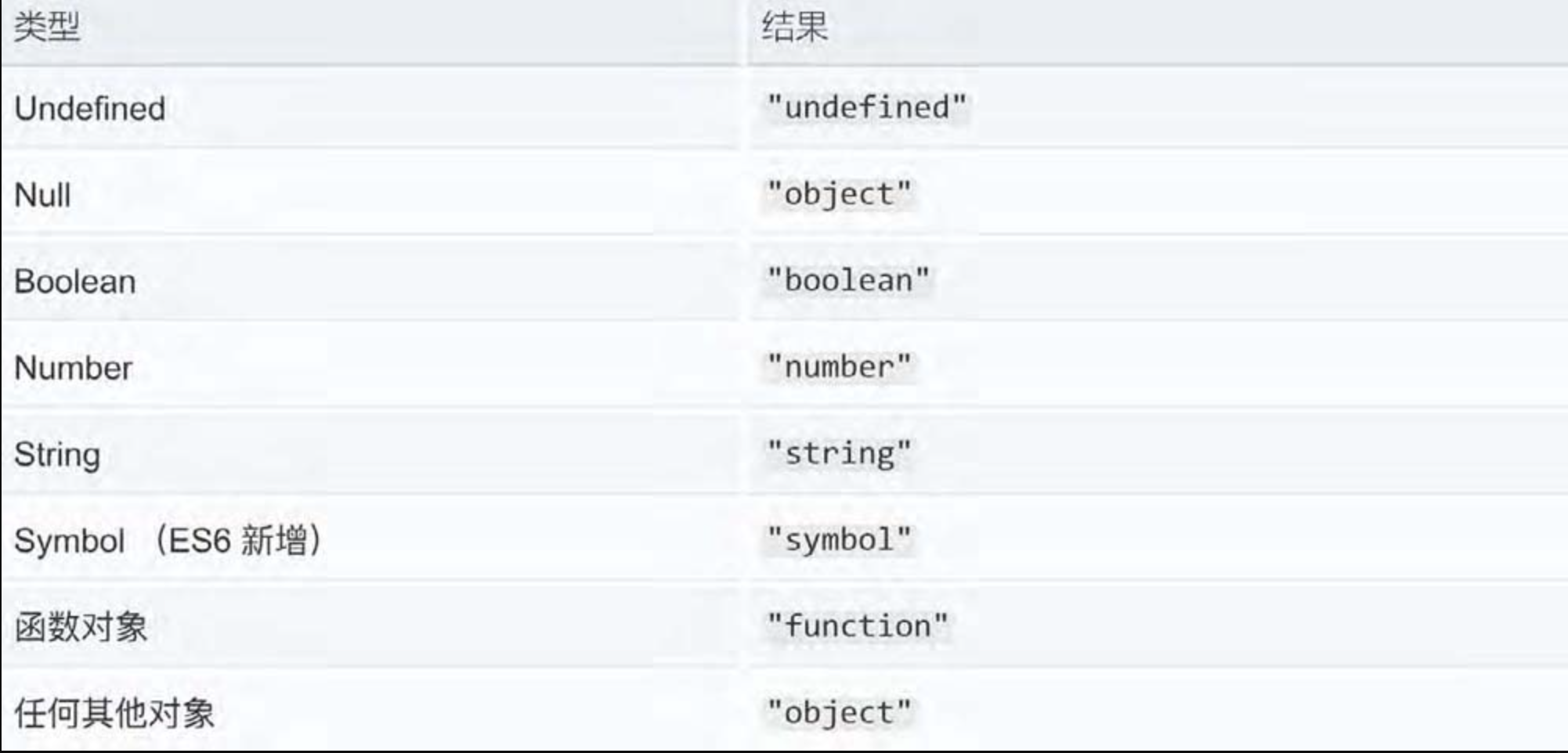
1.4.2 typeof运算符
typeof运算符在处理不同数据类型时会得到不同的结果。
1.4.2.1 处理Undefined类型的值
虽然Undefined类型的值只有一个undefined,但是typeof运算符在处理以下3种值时都会返回“undefined”。
· undefined本身。
· 未声明的变量。
· 已声明未初始化的变量。
1 | var declaredButUndefinedVariable; |
1.4.2.2 处理Boolean类型的值
Boolean类型的值只有两个,分别是true和false。typeof运算符在处理这两个值以及它们的包装类型时都会返回“boolean”,但是不推荐使用包装类型的写法。
1 | typeof true === 'boolean'; // true |
1.4.2.3 处理Number类型的值
1 | typeof 37 === 'number'; // true |
1.4.2.4 处理String类型的值
· 任何类型的字符串,包括空字符串和非空字符串。
· 返回值为字符串类型的表达式。
· 字符串类型的包装类型,例如String(‘hello’)、String(‘hello’ + ‘world’),虽然它们也会返回“String”,但是并不推荐这么写。
1 | typeof "" === 'string'; // true |
1.4.2.5 处理Symbol类型的值
1.4.2.6 处理Function类型的值
· 函数的定义,包括函数声明或者函数表达式两种形式。
· 使用class关键字定义的类,class是在ES6中新增的关键字,它不是一个全新的概念,原理依旧是原型继承,本质上仍然是一个Function。
· 某些内置对象的特定函数,例如Math.sin()函数、Number.isNaN()函数等。
· Function类型对象的实例,一般通过new关键字得到。
1 | var foo = function () {}; |
1.4.2.7 处理Object类型的值
· 对象字面量形式,例如{name: ‘kingx’}。
· 数组,例如[1, 2, 3]和Array(1, 2, 3)。
· 所有构造函数通过new操作符实例化后得到的对象,例如new Date()、new function(){},但是new Function(){}除外。
· 通过new操作符得到的基本数据类型的包装类型对象,如new Boolean(true)、new Number(1),但不推荐这么写。
细心的读者可能发现了,与基本数据类型的包装类型相关的部分,我们都有写“不推荐这么写”,这是为什么呢?因为涉及包装类型时,使用了new操作符与没有使用new操作符得到的值在通过typeof运算符处理后得到的结果是不一样的,很容易让人混淆。
1 | typeof {a:1} === 'object'; // true,对象字面量 |
1.4.2.8 使用typeof运算符注意事项
1、typeof运算符区分对待Object类型和Function类型
在实际使用过程中,有必要区分Object类型和Function类型,而typeof运算符就能帮我们实现。
2、typeof运算符对null的处理
使用typeof运算符对null进行处理,返回的是“object”,这是一个让大家都感到惊讶的结果。因为null是一个原生类型的数据,为什么typeof运算符会返回“object”呢?
这是一个在JavaScript设计之初就存在的问题,这里简单介绍下。
在JavaScript中,每种数据类型都会使用3bit表示。
· 000表示Object类型的数据。
· 001表示Int类型的数据。
· 010表示Double类型的数据。
· 100表示String类型的数据。
· 110表示Boolean类型的数据。
由于null代表的是空指针,大多数平台中值为0x00,因此null的类型标签就成了0,所以使用typeof运算符时会判断为object类型,返回“object”。
3、typeof运算符相关语法的括号
1 | var number = 123; |
1.4.3 逗号运算符
小小的逗号在JavaScript中有很大的用处,一方面它是基本的分隔符,例如,函数传递多个参数时,使用逗号分隔。
1 | console.log('我喜欢去%s上学习%s', '面试厅', 'JavaScript'); |
另一方面它可以作为一个运算符,作用是将多个表达式连接起来,从左至右依次执行。
1.4.3.1 在for循环中批量执行表达式
1 | for (var i = 0, j = 10; i < 10, j < 20; i++, j++) { |
一般在for循环的末尾处,只允许执行单个表达式。在这里我们通过逗号运算符,将i++和j++两个表达式视为同一个表达式,因此可以一次执行,处理i与j两个变量的递增。
1.4.3.2 用于简化代码
1 | if (x) { |
1.4.3.3 用小括号保证逗号运算符的优先级
在所有的运算符中,逗号运算符的优先级是最低的,因此对于某些涉及优先级的问题,我们需要使用到小括号,将含有逗号运算符的表达式括起来。
1 | var a = 20; |
对于上面的语句,首先定义一个变量a,然后使用逗号运算符对变量a执行自增操作,同时返回“10”,并将其赋值给变量b。
我们可能会认为最后输出b的值为10,但是运行后却抛出了异常,这是为什么呢?
在上面的代码中,同时出现了赋值运算符与逗号运算符,因为逗号运算符的优先级比较低,实际会先执行赋值运算符,即先执行var b = ++a语句,再去执行后面的10,它不是一个合法的语句,所以会抛出异常。
那么我们该怎么解决这个问题呢?
那就是使用小括号,保证逗号运算符的优先级,将赋值语句后面的内容括起来,执行完含有逗号运算符的表达式后,再执行赋值语句。
1 | var a = 20; |
1.4.4 运算符优先级
1 | // 语句1 |
在语句1中,将运算符OP1与OP2同时设置为赋值运算符,因为优先级相同,所以会从右到左依次运行
1 | b = 10; |
在语句2中,将运算符OP1与OP2同时设置为比较运算符,因为优先级相同,所以从左至右依次执行,
1 | 6 > 4; // true |
1.5 toString()函数 与 valueOf()函数
1.5.1 toString()函数
toString()函数的作用是把一个逻辑值转换为字符串,并返回结果。Object类型数据的toString()函数默认的返回结果是”[object Object]”,当我们自定义新的类时,可以重写toString()函数,返回可读性更高的结果。
1.5.2 valueOf()函数
valueOf()函数的作用是返回最适合引用类型的原始值,如果没有原始值,则会返回引用类型自身。Object类型数据的valueOf()函数默认的返回结果是”{}”,即一个空的对象字面量。
如果一个引用类型的值既存在toString()函数又存在valueOf()函数,那么在做隐式转换时,会调用哪个函数呢?
这里我们可以概括成两种场景,分别是引用类型转换为String类型,以及引用类型转换为Number类型。
1、 引用类型转换为String类型
一个引用类型的数据在转换为String类型时,一般是用于数据展示,转换时遵循以下规则。
· 如果对象具有toString()函数,则会优先调用toString()函数。如果它返回的是一个原始值,则会直接将这个原始值转换为字符串表示,并返回该字符串。
· 如果对象没有toString()函数,或者toString()函数返回的不是一个原始值,则会再去调用valueOf()函数,如果valueOf()函数返回的结果是一个原始值,则会将这个结果转换为字符串表示,并返回该字符串。
· 如果通过toString()函数或者valueOf()函数都无法获得一个原始值,则会直接抛出类型转换异常。
我们通过以下代码进行测试。
1 | var arr = []; |
上面代码执行后的结果如下所示。
1 | 执行了toString()函数 |
执行String(arr)代码时,需要将arr转换为字符串,则会优先执行toString()函数,但是其返回值为空数组[],并不能转换为原生数据;然后调用valueOf()函数,其返回值同样为空数组[];那么在调用完toString()函数和valueOf()函数后,均无法获取到原生数据类型表示,则抛出异常TypeError,表示无法将对象类型转换为原生数据类型。
2、 引用类型转换为Number类型
一个引用类型的数据在转换为Number类型时,一般是用于数据运算,转换时遵循以下规则。
· 如果对象具有valueOf()函数,则会优先调用valueOf()函数,如果valueOf()函数返回一个原始值,则会直接将这个原始值转换为数字表示,并返回该数字。
· 如果对象没有valueOf()函数,或者valueOf()函数返回的不是原生数据类型,则会再去调用toString()函数,如果toString()函数返回的结果是一个原始值,则会将这个结果转换为数字表示,并返回该数字。
· 如果通过toString()函数或者valueOf()函数都无法获得一个原始值,则会直接抛出类型转换异常。
我们通过以下代码进行测试。
1 | var arr = []; |
了解了valueOf()函数和toString()函数的关系后,我们再用下面两组代码深入拓展一下其他相关知识。
拓展1
1 | [] == 0; // true |
在第一行中,空数组可以转换为数字0;在第二行和第三行中,只有一个数字元素的数组可以转换为该数字。这是为什么呢?
因为数组继承了Object类型默认的valueOf()函数,这个函数返回的是数组自身,而不是原生数据类型,所以会继续调用toString()函数。数组调用toString()函数时会返回数组元素以逗号作为分隔符构成的字符串,那么空数组就转换为空字符串,而空字符串与数字0在非严格相等的情况下是相等的,即’’ == 0,返回“true”。
同样,只包含一个数字的数组[1],转换后为字符串”1”,后判断”1” == 1,返回“true”。
拓展2
以下是另外一组Object类型的数据,请观察结果有什么不同。
1 | var obj = { |
第一行执行代码为+obj,将对象obj转换为原始值,用于数据运算,优先调用valueOf()函数,获得原始值,结果为数字“10”。
第二行执行代码为’’ + obj,将对象obj转换为原始值,用于数据运算,优先调用valueOf()函数,获取原始值,并与字符串进行拼接,结果为字符串”10”。
第五行执行代码为obj == ‘10’,将对象obj转换为原始值,用于数据运算,优先调用valueOf()函数,即将10与’10’进行比较,两者是相等的,结果为“true”;
第六行执行代码为obj === ‘10’,因为两者数据类型不一致,直接返回“false”,并不会执行toString()函数或者valueOf()函数。
1.6 javascript中常见的判空方法
1.6.1 判断变量为空对象
(1)判断变量为null或者undefined
判断一个变量是否为空时,可以直接将变量与null或者undefined相比较,需要注意双等于(==)和三等于(===)的区别。
1 | if(obj == null) {} // 可以判断null或者undefined |
(2)判断变量为空对象{}
判断一个变量是否为空对象时,可以通过for…in语句遍历变量的属性,然后调用hasOwnProperty()函数,判断是否有自身存在的属性,如果存在则不为空对象,如果不存在自身的属性(不包括继承的属性),那么变量为空对象。
1 | // 判断变量为空 |
我们通过以下语句来做测试。
1 | // 定义空的对象字面量 |
1.6.2 判断变量为空数组
判断变量是否为空数组时,首先需要判断变量是否为数组,然后通过数组的length属性确定。
1 | arr instanceof Array && arr.length === 0 |
当以上两个条件都满足时,变量是一个空数组。
1.6.3 判断变量为空字符串
1 | str == '' || str.trim().length == 0; |
1.6.4 判断变量为0或者NaN
当一个变量为Number类型时,判空即判断变量是否为0或者NaN,因为NaN与任何值比较都为false,所以我们可以通过取非运算符完成。
1 | !(Number(num) && num) == true; |
1.6.5 !x == true的所有情况
本小节一开始就讲到!x为true时,会包含很多种情况,这里我们一起来总结下:
· 变量为null。
· 变量为undefined。
· 变量为空字符串’ ‘。
· 变量为数字0,包括+0、-0。
· 变量为NaN。
1.7 javascript中switch语句
1 | switch(expression) { |
因为在JavaScript中对于case的比较是采用严格相等(===)的。
2、引用数据类型
引用数据类型主要用于区别基本数据类型,描述的是具有属性和函数的对象。JavaScript中常用的引用数据类型包括Object类型、Array类型、Date类型、RegExp类型、Math类型、Function类型以及基本数据类型的包装类型,如Number类型、String类型、Boolean类型等。
引用数据类型有不同于基本数据类型的特点,具体如下所示。
· 引用数据类型的实例需要通过new操作符生成,有的是显式调用,有的是隐式调用。
· 引用数据类型的值是可变的,基本数据类型的值是不可变的。
· 引用数据类型变量赋值传递的是内存地址。
· 引用数据类型的比较是对内存地址的比较,而基本数据类型的比较是对值的比较。
2.1 Object类型及其实例和静态函数
2.1.1 深入了解JavaScript中的new操作符
**new操作符在执行过程中会改变this的指向,**所以在了解new操作符之前,我们先解释一下this的用法。
1 | function Cat(name, age) { |
事实上我们并未通过return返回任何值,为什么输出的信息中会包含name和age属性呢?其中起作用的就是this这个关键字了。
1 | function Cat(name,age) { |
在JavaScript中,如果函数没有return值,则默认return this
1 | function Cat(name, age) { |
通过以上的分析,我们了解了构造函数中this的用法,那么它与new操作符之间有什么关系呢?
1 | let cat = new Cat(); |
从表面上看这行代码的主要作用是创建一个Cat对象的实例,并将这个实例值赋予cat变量,cat变量就会包含Cat对象的属性和函数。
其实,new操作符做了3件事情,如下代码所示:
1 | 1. var cat = {}; |
第一件事: 创建cat空对象;
第二件事: 将空对象的__proto__指向Cat对象的prototype的属性
第三件事: 将Cat()函数中的this指向cat对象
我们自定义一个类似new功能的函数,来具体讲解上面的3行代码。
1 | function Cat(name, age) { |
返回的结果中也包含name和age属性,这就证明了new运算符对this指向的改变。Cat.apply(obj, arguments)调用后Cat对象中的this就指向了obj对象,这样obj对象就具有了name和age属性。
因此,不仅要关注new操作符的函数本身,也要关注它的原型属性。
我们对上面的代码进行改动,在Cat对象的原型上增加一个sayHi()函数,然后通过New()函数返回的对象,去调用sayHi()函数,看看执行情况如何。
1 | function Cat(name, age) { |
我们发现执行报错了,New()函数返回的对象并没有调用sayHi()函数,这是因为sayHi()函数是属于Cat原型的函数,只有Cat原型链上的对象才能继承sayHi()函数,那么我们该怎么做呢?
这里需要用到的就是__proto__属性,实例的__proto__属性指向的是创建实例对象时,对应的函数的原型。设置obj对象的__proto__值为Cat对象的prototype属性,那么obj对象就继承了Cat原型上的sayHi()函数,这样就可以调用sayHi()函数了。
1 | function Cat(name, age) { |
2.1.2 Object类型的实例函数
实例函数是指函数的调用是基于Object类型的实例的。代码如下所示。
1 | var obj = new Object(); |
所有实例函数的调用都是基于obj这个实例。
Object类型中有几个很重要的实例函数,这里分别进行详细的讲解。
1、 hasOwnProperty(propertyName)函数
该函数的作用是判断对象自身是否拥有指定名称的实例属性,此函数不会检查实例对象原型链上的属性。
2、propertyIsEnumerable(propertyName)函数
该函数的作用是判断指定名称的属性是否为实例属性并且是否是可枚举的,如果是原型链上的属性或者不可枚举都将返回“false”。
1 | // 1.数组 |
2.1.3 Object类型的静态函数
静态函数指的是方法的调用基于Object类型自身,不需要通过Object类型的实例。
1、 Object.create()函数
该函数的主要作用是创建并返回一个指定原型和指定属性的对象。语法格式如下所示。
1 | Object.create(prototype, propertyDescriptor)。 |
其中prototype属性为对象的原型,可以为null。若为null,则对象的原型为undefined。属性描述符的格式如下所示。
1 | // 建立一个自定义对象,设置name和age属性 |
我们尝试用polyfill版本实现Object.create()函数,通过polyfill我们可以更清楚明白Object.create()函数的实现原理。
1 | Object.create = function (proto, propertiesObject) { |
在create()函数中,首先声明一个函数为F()函数,然后将F()函数的prototype属性指向传入的proto参数,通过new操作符生成F()函数的实例。
假如var f = new F(),f._proto_ === F.prototype。实际上生成的对象实例会把属性继承到其__proto__属性上。
我们再通过下面的实例来验证。
1 | var test = Object.create({x:123, y:345}); |
实际生成的test为一个空对象{}。但是我们可以访问其x属性,这是因为我们可以通过其__proto__属性访问到x属性,所以我们通过test访问到x属性和y属性,实际是通过其__proto__属性访问到的。
2、 Object.defineProperties()函数
该函数的主要作用是添加或修改对象的属性值,语法格式如下所示。
1 | Object.defineProperties(obj, propertyDescriptor) |
其中的属性描述符propertyDescriptor同Object.create()函数一样。例如,给一个空对象{}添加name和age属性,其代码如下所示。
1 | var obj = {}; |
3、Object.getOwnPropertyNames()函数
该函数的主要作用是获取对象的所有实例属性和函数,不包含原型链继承的属性和函数,数据格式为数组。
1 | function Person(name, age, gender) { |
4、 Object.keys()函数
该函数的主要作用是获取对象可枚举的实例属性,不包含原型链继承的属性,数据格式为数组。keys()函数区别于getOwnPropertyNames()函数的地方在于,keys()函数只获取可枚举类型的属性。
1 | var obj = { |
2.2 Array类型
2.2.1 判断一个变量是数组还是对象
1 | var a = [1, 2, 3]; |
所以使用typeof运算符并不能直接判断一个变量是对象还是数组类型。实际上,typeof运算符在判断基本数据类型时会很有用,但是在判断引用数据类型时,却显得很吃力。
1、instanceof运算符
instanceof运算符用于通过查找原型链来检测某个变量是否为某个类型数据的实例,使用instanceof运算符可以判断一个变量是数组还是对象。
1 | var a = [1, 2, 3]; |
封装
1 | // 判断变量是数组还是对象 |
2、判断构造函数
判断一个变量是否是数组或者对象,从另一个层面讲,就是判断变量的构造函数是Array类型还是Object类型。因为一个对象的实例都是通过构造函数生成的,所以,我们可以直接判断一个变量的constructor属性。
1 | var a = [1, 2, 3]; |
那么一个变量为什么会有constructor属性呢?这就要涉及原型链的知识了。
每个变量都会有一个__proto__属性,表示的是隐式原型。一个对象的隐式原型指向的是构造该对象的构造函数的原型,这里用数组来举例,代码如下所示。
1 | []._ _proto_ _ === [].constructor.prototype; // true |
上面直接通过constructor属性判断的语句也可以改写成下面的形式。
1 | var a = [1, 2, 3]; |
封装
1 | // 判断变量是数组还是对象 |
3、toString()函数
每种引用数据类型都会直接或间接继承自Object类型,因此它们都包含toString()函数。不同数据类型的toString()函数返回值也不一样,所以通过toString()函数就可以判断一个变量是数组还是对象。
这里我们会借助call()函数,直接调用Object原型上的toString()函数,把主体设置为需要传入的变量,然后通过返回值进行判断。
1 | var a = [1, 2, 3]; |
4、Array.isArray()函数
1 | // 下面的函数调用都返回“true” |
2.2.2 filter()函数过滤满足条件的数据
**filter()函数用于过滤出满足条件的数据,返回一个新的数组,不会改变原来的数组。**它不仅可以过滤简单类型的数组,而且可以通过自定义方法过滤复杂类型的数组。
filter()函数接收一个函数作为其参数,返回值为“true”的元素会被添加至新的数组中,返回值为“false”的元素则不会被添加至新的数组中,最后返回这个新的数组。如果没有符合条件的值则返回空数组。
接下来我们可以具体看看filter()函数的使用场景。
1、针对简单类型的数组,找出数组中所有为奇数的数字
1 | var filterFn = function (x) { |
2、针对复杂类型的数组,找出所有年龄大于18岁的男生
1 | var filterFn = function (obj) { |
2.2.3 reduce()函数累加器处理数组元素
reduce()函数最主要的作用是做累加处理,即接收一个函数作为累加器,将数组中的每一个元素从左到右依次执行累加器,返回最终的处理结果。
1 | arr.reduce(callback[, initialValue]); |
initialValue用作callback的第一个参数值,如果没有设置,则会使用数组的第一个元素值。callback会接收4个参数(accumulator、currentValue、currentIndex、array)。
· accumulator表示上一次调用累加器的返回值,或设置的initialValue值。如果设置了initialValue,则accumulator=initialValue;否则accumulator=数组的第一个元素值。
· currentValue表示数组正在处理的值。
· currentIndex表示当前正在处理值的索引。如果设置了initialValue,则currentIndex从0开始,否则从1开始。
· array表示数组本身。
在掌握了reduce()函数的语法后,我们列举出了几种灵活运用reduce()函数的场景,看看它是如何解决对应问题的。
1、求数组每个元素相加的和
1 | var arr = [1, 2, 3, 4, 5]; |
设置initialValue为0,在进行第一轮运算时,accumulator为0,currentValue从1开始,第一轮计算完成累加的值为0+1=1;在进入第二轮计算时,accumulator为1,currentValue为2,第二轮计算完成累加的值为1+2=3;以此类推,在进行5轮计算后最终的输出结果为“15”。
2、 统计数组中每个元素出现的次数
假如存在一个数组为[1, 2, 3, 2, 2, 5, 1],通过一定的算法,统计出其中数字1出现的次数为2,2出现的次数为3,3出现的次数为1,5出现的次数为1。
1 | var countOccurrences = function(arr) { |
3、多维度统计数据
我们在知道不同币值汇率的情况下,将一组人民币的值分别换算成美元和欧元的等量值。
首先我们需要有一组人民币值,假设如下。
1 | var items = [{price: 10}, {price: 50}, {price: 100}]; |
此时查到人民币:美元汇率为1:0.1478,人民币:欧元汇率为1:0.1265。通过一定的算法,需要计算出这些人民币值对应的美元是23.792,对应的欧元是20.240。
解决问题的思路如下。
因为涉及不同汇率的计算,reduce()函数的第一个callback参数可以封装为一个reducers数组。数组中的每个元素实际为一个函数,利用reduce()函数单独完成一个汇率的计算。
1 | var reducers = { |
上面的reducers通过一个manager()函数,利用object.keys()函数同时执行多个函数,每个函数完成各自的汇率计算。
1 | var manageReducers = function(reducers) { |
运行结束后得到的结果为“{euros: 20.240, dollars: 23.792}”,符合预期。
2.2.4 求数组的最大值和最小值
1、通过prototype属性扩展min()函数和max()函数
1 | // 最小值 |
2、 借助Math对象的min()函数和max()函数
算法2的主要思想是通过apply()函数改变函数的执行体,将数组作为参数传递给apply()函数。这样数组就可以直接调用Math对象的min()函数和max()函数来获取返回值。
1 | // 最大值 |
3、算法二的优化
1 | // 最大值 |
4、借助Array类型的reduce()函数
1 | // 最大值 |
5、借助Array类型的sort()函数
算法5的主要思想是借助数组原生的sort()函数对数组进行排序,排序完成后首尾元素即是数组的最小、最大元素。
**默认的sort()函数在排序时是按照字母顺序排序的,数字都会按照字符串处理,例如数字11会被当作”11”处理,数字8会被当作”8”处理。**在排序时是按照字符串的每一位进行比较的,因为”1”比”8”要小,所以”11”在排序时要比”8”小。对于数值类型的数组来说,这显然是不合理的,所以需要我们自定义排序函数。
1 | var sortFn = function (a, b) { |
6、借助ES6的扩展运算符
算法6的主要思想是借助于ES6中增加的扩展运算符(…),将数组直接通过Math.min()函数与Math.max()函数的调用,找出数组中的最大值和最小值。
1 | var arr6 = [2, 4, 10, 7, 5, 8, 6] |
2.2.5 数组遍历的7种方法及兼容性处理(polyfill)
1、最原始的for循环
2、基于forEach()函数的方法
1 | var arr2 = [11, 22, 33]; |
3、 基于map()函数的方法
map()函数在用于在数组遍历的过程中,将数组中的每个元素做处理,得到新的元素,并返回一个新的数组。map()函数并不会改变原数组,其接收的参数和forEach()函数一样。
需要注意的一点是,在map()函数的回调函数中需要通过return返回处理后的值,否则会返回“undefined”。例如下面:在没有通过return返回处理后的值的情况下,最终的结果为[undefined,undefined, undefined]。
1 | var arr3 = [1, 2, 3]; |
4、 基于filter()函数的方法
filter()函数是通过判断返回值是否为“true”来决定是否将返回值push至新的数组中。
1 | // filter()函数兼容性处理 |
5、 基于some()函数与every()函数的方法
some()函数与every()函数的相似之处在于都用于数组遍历的过程中,判断数组是否有满足条件的元素,满足条件则返回“true”,否则返回“false”。some()函数与every()函数的区别在于some()函数只要数组中某个元素满足条件就返回“true”,不会对后续元素进行判断;而every()函数是数组中每个元素都要满足条件时才返回“true”。
1 | // 定义判断的函数 |
6、 基于reduce()函数的方法
1 | // reduce()函数兼容性处理 |
7、基于find()函数的方法
find()函数用于数组遍历的过程中,找到第一个满足条件的元素值时,则直接返回该元素值;如果都不满足条件,则返回“undefined”。
1 | var value = [1, 5, 10, 15].find(function (element, index, array) { |
2.2.6 数组去重的7种算法
例如存在一个数组[1, 4, 5, 7, 4, 8, 1, 10, 4],通过一定的算法,需要得到的数组为[1,4, 5, 7, 8, 10]。
1、遍历数组 / 利用对象键值对
1 | // 遍历数组 |
2、先排序,再去重
主要思想是借助原生的sort()函数对数组进行排序,然后对排序后的数组进行相邻元素的去重,将去重后的元素添加至新的数组中,返回这个新数组。
1 | function arrayUnique3(array) { |
3、优先遍历数组
主要思想是利用双层循环,分别指定循环的索引i与j,j的初始值为i+1。在每层循环中,比较索引i和j的值是否相等,如果相等则表示数组中出现了相同的值,则需要更新索引i与j,操作为++i;同时将其赋值给j,再对新的索引i与j的值进行比较。循环结束后会得到一个索引值i,表示的是右侧没有出现相同的值,将其push到结果数组中,最后返回结果数组。
1 | function arrayUnique4(array) { |
4、基于reduce()函数
需要借助一个key-value对象。在reduce()函数的循环中判断key是否重复,如果为是,则将当前元素push至结果数组中。实际做法是设置initialValue为一个空数组[],同时将initialValue作为最终的结果进行返回。在reduce()函数的每一轮循环中都会判断数据类型,如果数据类型不同,将表示为不同的值,如1和”1”,将作为不重复的值。
1 | function arrayUnique5(array) { |
5、借助ES6的Set数据结构
主要思想是借助于ES6中新增的Set数据结构,它类似于数组,但是有一个特点,即成员都是唯一的,所以Set具有自动去重的功能。
在ES6中,Array类型增加了一个from()函数,用于将类数组对象转化为数组,然后再结合Set可以完美实现数组的去重。
1 | function arrayUnique6(array) { |
6、借助ES6的Map数据结构
主要思想是借助于ES6中新增的Map数据结构,它是一种基于key-value存储数据的结构,每个key都只对应唯一的value。如果将数组元素作为Map的key,那么判断Map中是否有相同的key,就可以判断出元素的重复性。
Map还有一个特点是key会识别不同数据类型的数据,即1与”1”在Map中会作为不同的key处理,不需要通过额外的函数来判断数据类型。
基于Map数据结构,通过filter()函数过滤,即可获得去重后的结果。
1 | function arrayUnique7(array) { |
2.2.7 找出数组中出现次数最多的元素
存在一个数组为[3, 5, 6, 5, 9, 8, 10, 5, 7, 7, 10, 7, 7, 10, 10, 10, 10, 10],通过一定的算法,找出次数最多的元素为10,其出现次数为7次。
1、利用键值对
1 | function findMost1(arr) { |
2、利用键值对优化版
1 | function findMost2(arr) { |
3、借助Array类型的reduce()函数
主要思想是使用Array类型的reduce()函数,优先设置初始的出现次数最大值maxNum为1,设置initialValue为一个空对象{},每次处理中优先计算当前元素出现的次数,在每次执行完后与maxNum进行比较,动态更新maxNum与maxEle的值,最后获得返回的结果
1 | function findMost3(arr) { |
2.3 Date类型
2.3.1 日期格式化
2.3.1.1 基于严格的时间格式解析
1 | /** |
2.3.2 日期合法性校验
校验日期合法性的主要思想是利用正则表达式,将正则表达式按分组处理,匹配到不同位置的数据后,得到一个数组。利用数组的数据构造一个Date对象,获得Date对象的年、月、日的值,再去与数组中表示年、月、日的值比较。如果都相等的话则为合法的日期,如果不相等的话则为不合法的日期。
1 | function validateDate(str) { |
2.3.3 日期计算
2.3.3.1 比较日期大小
1 | function CompareDate(dateStr1, dateStr2) { |
2.3.3.2 计算当前日期前后N天的日期
1 | function GetDateStr(AddDayCount) { |
2.3.3.3 计算两个日期的事件差
计算两个日期的时间差的主要思路如下。
· 将传入的时间字符串中的“-”分隔符转换为“/”。
· 将转换后的字符串构造成新的Date对象。
· 以毫秒作为最小的处理单位,然后根据处理维度,进行相应的描述计算。例如天换算成毫秒,就为“1000 * 3600 * 24”。
· 两个时间都换算成秒后,进行减法运算,与维度值相除即可得到两个时间的差值。
1 | function GetDateDiff(startTime, endTime, diffType) { |
3、函数
在JavaScript中,要说理解起来,难度最大的就是函数了。函数中包括作用域、原型链、闭包等核心知识点
· 函数的定义与调用。
· 函数参数。
· 构造函数。
· 变量提升与函数提升。
· 闭包。
· this使用详解。
· call()函数、apply()函数、bind()函数的使用与区别。
3.1 函数的定义和调用
3.1.1 函数的定义
1、 函数声明
1 | function sum (num1, num2){ |
2、函数表达式
1 | // 函数表达式 |
或者
1 | // 具有函数名的函数表达式 |
其中foo是函数名称,它实际是函数内部的一个局部变量,在函数外部是无法直接调用的,示例如下。
1 | console.log(foo(1, 3)); // ReferenceError: foo is not defined |
在调用foo时,会直接抛出foo未定义的异常。
3、Function()构造函数
1 | // 其中的参数,除了最后一个参数是执行的函数体,其他参数都是函数的形参。 |
相比于函数声明和函数表达式这两种方式,Function()构造函数的使用比较少,主要有以下两个原因。
第一个原因是Function()构造函数每次执行时,都会解析函数主体,并创建一个新的函数对象,所以当在一个循环或者频繁执行的函数中调用Function()构造函数时,效率是非常低的。
第二个原因是使用Function()构造函数创建的函数,并不遵循典型的作用域,它将一直作为顶级函数执行。所以在一个函数A内部调用Function()构造函数时,其中的函数体并不能访问到函数A中的局部变量,而只能访问到全局变量。
4、函数表达式的应用场景
(1)函数递归
(2)代码模块化
1 | var person = (function () { |
5、函数声明与函数表达式的区别
(1)函数名称
在使用函数声明时,是必须设置函数名称的,这个函数名称相当于一个变量,以后函数的调用也会通过这个变量进行。
而对于函数表达式来说,函数名称是可选的,我们可以定义一个匿名函数表达式,并赋给一个变量,然后通过这个变量进行函数的调用。
1 | // 函数声明,函数名称sum必须设置 |
(2)函数提升
对于函数声明,存在函数提升,所以即使函数的调用在函数的声明之前,仍然可以正常执行。
对于函数表达式,不存在函数提升,所以在函数定义之前,不能对其进行调用,否则会抛出异常。
3.1.2 函数的调用
函数的调用存在5种模式,分别是函数调用模式,方法调用模式,构造器调用模式,call()函数、apply()函数调用模式,匿名函数调用模式。这5种模式在使用时都有很明显的特征
1、函数调用模式
待写
2、方法调用模式
方法调用模式会优先定义一个对象obj,然后在对象内部定义值为函数的属性property,通过对象obj.property()来进行函数的调用
1 | // 定义对象 |
3、构造器调用模式
构造器调用模式会定义一个函数,在函数中定义实例属性,在原型上定义函数,然后通过new操作符生成函数的实例,再通过实例调用原型上定义的函数。
1 | // 定义函数对象 |
4、call()函数、apply()函数调用模式
通过call()函数或者apply()函数可以改变函数执行的主体,使得某些不具有特定函数的对象可以直接调用该特定函数。
1 | // 定义一个函数 |
5、匿名函数调用模式
模式一
1 | // 通过函数表达式定义匿名函数,并赋给变量sum |
模式二
1 | (function (num1, num2) { |
需要注意的是,如果前半部分的函数声明没有使用小括号括住,则直接进行函数的调用时,会抛出语法异常。例如:
1 | // 因为JavaScript解释器在解析语句时,会将function关键字当作函数声明的开始, |
3.1.3 自执行函数
自执行函数即函数定义和函数调用的行为先后连续产生。它需要以一个函数表达式的身份进行函数调用,上面的匿名函数调用也属于自执行函数的一种。
接下来我们一起看看自执行函数的多种表现形式。
1 | function (x) { |
3.2 函数参数
3.2.1 形参和实参
形参和实参的区别有以下几点。
1、形参出现在函数的定义中,只能在函数体内使用,一旦离开该函数则不能使用;实参出现在主调函数中,进入被调函数后,实参也将不能被访问
1 | function fn1() { |
2、在强类型语言中,定义的形参和实参在数量、数据类型和顺序上要保持严格一致,否则会抛出“类型不匹配”的异常。
3、在函数调用过程中,数据传输是单向的,即只能把实参的值传递给形参,而不能把形参的值反向传递给实参。因此在函数执行时,形参的值可能会发生变化,但不会影响到实参中的值。
1 | var arg = 1; |
4、当实参是基本数据类型的值时,实际是将实参的值复制一份传递给形参,在函数运行结束时形参被释放,而实参中的值不会变化。当实参是引用类型的值时,实际是将实参的内存地址传递给形参,即实参和形参都指向相同的内存地址,此时形参可以修改实参的值,但是不能修改实参的内存地址。
下面的代码段定义了一个实参arg为一个对象,name属性值为kingx,在调用fn()函数时,首先修改了形参param的name属性值为kingx2,此时形参param与实参arg指向的是同一个内存地址(假设为A),因此arg的值也会发生变化。
然后将形参param重新赋值为一个空对象,表示的是将形参param指向了一个新的内存地址(假设为B),但是这并不会影响实参arg的值,它仍然指向原来的内存地址A,因此最后的输出结果为“{name: “kingx2”}”。
1 | var arg = {name: 'kingx'}; |
3.2.2 arguments对象性质
arguments对象是所有函数都具有的一个内置局部变量,表示的是函数实际接收的参数,是一个类数组结构。
之所以说arguments对象是一个类数组结构,是因为它除了具有length属性外,不具有数组的一些常用方法。
下面会分析arguments对象所具有的性质。
1、可通过索引访问
1 | function sum(num1, num2) { |
2、由实参决定
arguments对象的值由实参决定,而不是由定义的形参决定,形参与arguments对象占用独立的内存空间。
· arguments对象的length属性在函数调用的时候就已经确定,不会随着函数的处理而改变。
· 指定的形参在传递实参的情况下,arguments对象与形参值相同,并且可以相互改变。
· 指定的形参在未传递实参的情况下,arguments对象对应索引值返回“undefined”。
· 指定的形参在未传递实参的情况下,arguments对象与形参值不能相互改变。
1 | function foo(a, b, c) { |
3、特殊的arguments.callee属性
arguments对象有一个很特殊的属性callee,表示的是当前正在执行的函数,在比较时是严格相等的。
1 | function create() { |
尽管arguments.callee属性可以用于获取函数本身去做递归调用,但是我们并不推荐广泛使用arguments.callee属性,其中有一个主要原因是使用arguments.callee属性后会改变函数内部的this值
1 | var sillyFunction = function (recursed) { |
3.2.3 arguments对象的应用
1、实参的个数判断
1 | function f(x, y, z) { |
2、任意个数的参数处理
1 | function joinStr(seperator) { |
3、模拟函数重载
函数重载表示的是在函数名相同的情况下,通过函数形参的不同参数类型或者不同参数个数来定义不同的函数
我们都知道在JavaScript中是没有函数重载的,主要有以下几点原因。
· JavaScript是一门弱类型的语言,变量只有在使用时才能确定数据类型,通过形参是无法确定数据类型的。
· 无法通过函数的参数个数来指定调用不同的函数,函数的参数个数是在函数调用时才确定下来的。
· 使用函数声明定义的具有相同名称的函数,后者会覆盖前者。
那么遇到这种情况,我们该如何写出一个通用的函数,来实现任意个数字的加法运算求和呢?
答案就是使用arguments对象处理传递的参数。
首先通过call()函数间接调用数组的slice()函数以得到函数参数的数组;
然后调用数组的reduce()函数进行多个值的求和并返回。
1 | // 通用求和函数 |
3.3 构造函数
在函数中存在一类比较特殊的函数——构造函数。当我们创建对象的实例时,通常会使用到构造函数,例如对象和数组的实例化可以通过相应的构造函数Object()和Array()完成。
构造函数与普通函数在语法的定义上没有任何区别,主要的区别体现在以下3点。
1、 构造函数的函数名的第一个字母通常会大写。
2、 在函数体内部使用this关键字,表示要生成的对象实例,构造函数并不会显式地返回任何值,而是默认返回“this”。
3、 作为构造函数调用时,必须与new操作符配合使用。
1 | // 构造函数 |
一个函数在当作普通函数使用时,函数内部的this会指向window。
1 | Person('kingx', '12'); |
使用构造函数可以在任何时候创建我们想要的对象实例,构造函数在执行时会执行以下4步:
1、 通过new操作符创建一个新的对象,在内存中创建一个新的地址。
2、 为构造函数中的this确定指向。
3、 执行构造函数代码,为实例添加属性。
4、 返回这个新创建的对象。
以前面生成person实例的代码为例。
第一步:为person实例在内存中创建一个新的地址。
第二步:确定person实例的this指向,指向person本身。
第三步:为person实例添加name、age和sayName属性,其中sayName属性值是一个函数。
第四步:返回这个person实例。
1 | var person1 = new Person(); |
**事实上,当我们在创建对象的实例时,对于相同的函数并不需要重复创建,而且由于this的存在,总是可以在实例中访问到它具有的属性。**因此,我们需要使用一种更好的方式来处理函数类型的属性。大家可能会想到设置全局访问的函数,这样就可以被所有实例访问到,而不用重复创建。
但是这样也会存在一个问题,如果为一个对象添加的所有函数都处理成全局函数,这样会污染到全局作用域空间,而且也无法完成对一个自定义类型对象的属性和函数的封装,因此这不是一个好的解决办法。
这里就要引入原型的概念了!!!
3.4 变量提升与函数提升
在JavaScript中,会存在一些比较奇怪的现象。例如,一个函数体内,变量在定义之前就可以被访问到,而不会抛出异常。
1 | function fn() { |
1 | fn(); // 函数正常执行,输出“函数得到调用” |
3.4.1 作用域
在JavaScript中,一个变量的定义与调用都是会在一个固定的范围中的,这个范围我们称之为作用域。作用域可以分为:全局作用域、函数作用域和块级作用域。
需要注意的是块级作用域是在ES6中新增的,需要使用特定的let或者const关键字定义变量。
1 | // 全局作用域内的变量a |
3.4.2 变量提升
变量提升是将变量的声明提升到函数顶部的位置,而变量的赋值并不会被提升。
需要注意的一点是,会产生提升的变量必须是通过var关键字定义的,而不通过var关键字定义的全局变量是不会产生变量提升的。
通过下面的代码可以发现,变量v的定义未使用var关键字,那么它是一个全局变量,不会产生变量提升,直接进行输出,抛出一个变量v未定义的异常。
1 | (function () { |
1、代码段1的执行过程
在全局对象window上定义一个变量v,并赋值为Hello World。然后定义一个立即执行函数,这个立即执行函数的作用域为window。在函数内部引用变量v,然后会顺着作用域寻找,最终会在window上找到这个变量v,因此输出“Hello World”。
2、代码段2的执行过程
代码段2中出现了变量提升,在立即执行函数的内部,变量v的定义会提升到函数顶部,实际执行过程的代码如下所示。
1 | var v = 'Hello World'; |
同代码段1的分析,在window上定义一个变量v,赋值为Hello World,而且在立即执行函数的内部同样定义了一个变量v,但是赋值语句并未提升,因此v为undefined。在输出时,会优先在函数内部作用域中寻找变量,而变量已经在内部作用域中定义,因此直接输出“undefined”。
3.4.3 函数提升
不仅通过var定义的变量会出现提升的情况,使用函数声明方式定义的函数也会出现提升,
1 | show(); // 你好 |
3.4.4 变量提升与函数提升的应用
1、关于函数提升
1 | function foo() { |
由于变量提升的存在,两段代码都会被提升至foo()函数的顶部,而且后一个函数会覆盖前一个bar()函数,因此最后输出值为“8”。
2、变量提升和函数提升同时使用
1 | var a = true; |
在foo()函数内部,首先判断变量a的值,由于变量a在函数内部重新通过var关键字声明了一次,因此a会出现变量提升,a会提升至foo()函数的顶部,此时a的值为undefined。那么通过if语句进行判断时,返回“false”,并未执行a = 10的赋值语句,因此最后输出“undefined”。
3、变量提升和函数提升优先级
1 | function fn() { |
同时存在变量提升和函数提升,但是变量提升的优先级要比函数提升的优先级高。 上面的代码执行如下:
1 | function fn() { |
4、变量提升和函数提升整体应用
理解变量提升和函数提升可以使我们更了解这门语言,更好地驾驭它。但是在开发中,我们不应该使用这些技巧,而是要规范我们的代码,尽可能提高代码的可读性和可维护性。
- 无论变量还是函数,都做到先声明后使用。
- 对于ES6语法编写的代码,则全部使用let或者const关键字。
3.5 闭包
在正常情况下,如果定义了一个函数,就会产生一个函数作用域,在函数体中的局部变量会在这个函数作用域中使用。一旦函数执行完成,函数所占空间就会被回收,存在于函数体中的局部变量同样会被回收,回收后将不能被访问到。那么如果我们期望在函数执行完成后,函数中的局部变量仍然可以被访问到,这能不能实现呢?
3.5.1 执行上下文环境
JavaScript每段代码的执行都会存在于一个执行上下文环境中,而任何一个执行上下文环境都会存在于整体的执行上下文环境中。根据栈先进后出的特点,全局环境产生的执行上下文环境会最先压入栈中,存在于栈底。当新的函数进行调用时,会产生的新的执行上下文环境,也会压入栈中。当函数调用完成后,这个上下文环境及其中的数据都会被销毁,并弹出栈,从而进入之前的执行上下文环境中。
需要注意的是,处于活跃状态的执行上下文环境只能同时有一个,即图所示的深色背景的部分。

1 | var a = 10; // 1.进入全局执行上下文环境 |
有另外一种情况,虽然代码执行完毕,但执行上下文环境却被无法干净地销毁,这就是我们要讲到的闭包。
3.5.2 闭包的概念
在JavaScript中存在一种内部函数,即函数声明和函数表达式可以位于另一个函数的函数体内,在内部函数中可以访问外部函数声明的变量,当这个内部函数在包含它们的外部函数之外被调用时,就会形成闭包。
闭包有两个很明显的特点。
· 函数拥有的外部变量的引用,在函数返回时,该变量仍然处于活跃状态。
· 闭包作为一个函数返回时,其执行上下文环境不会被销毁,仍处于执行上下文环境中。
1 | function fn() { |
当代码执行到第10行时,调用f1()函数,注意此时是一个关键的节点,因为f1()函数中包含了对max变量的引用,而max变量是存在于外部函数fn()中的,此时fn()函数执行上下文环境并不会被直接销毁,依然存在于执行上下文环境中。
等到第10行代码执行结束后,bar()函数执行完毕,bar()函数执行上下文环境才会被销毁,同时因为max变量引用会被释放,fn()函数执行上下文环境也一同被销毁。
最后全局上下文环境执行完毕,栈被清空,流程执行结束。
从分析就可以看出闭包所存在的最大的一个问题就是消耗内存,如果闭包使用越来越多,内存消耗将越来越大
3.5.3 闭包的用途
3.5.3.1 结果缓存
在开发过程中,我们可能会遇到这样的场景,假如有一个处理很耗时的函数对象,每次调用都会消耗很长时间。
我们可以将其处理结果在内存中缓存起来。这样在执行代码时,如果内存中有,则直接返回;如果内存中没有,则调用函数进行计算,更新缓存并返回结果。
因为闭包不会释放外部变量的引用,所以能将外部变量值缓存在内存中。
1 | var cachedBox = (function () { |
3.5.3.2 封装
在JavaScript中提倡的模块化思想是希望将具有一定特征的属性封装到一起,只需要对外暴露对应的函数,并不关心内部逻辑的实现。
1 | var stack = (function () { |
接下来我们将通过几道练习题加深大家对闭包的理解。
1、ul中有若干个li,每次单击li,输出li的索引值
1 | <ul> |
但是真正运行后却发现,结果并不如自己所想,每次单击后输出的并不是索引值,而一直都是“5”。
这是为什么呢?因为在我们单击li,触发li的click事件之前,for循环已经执行结束了,而for循环结束的条件就是最后一次i++执行完毕,此时i的值为5,所以每次单击li后返回的都是“5”。
1 | <script> |
在每一轮的for循环中,我们将索引值i传入一个匿名立即执行函数中,在该匿名函数中存在对外部变量lis的引用,因此会形成一个闭包。而闭包中的变量index,即外部传入的i值会继续存在于内存中,所以当单击li时,就会输出对应的索引index值。
2、定时器问题
定时器setTimeout()函数和for循环在一起使用,总会出现一些意想不到的结果,我们看看下面的代码。
1 | var arr = ['one', 'two', 'three']; |
但是运行过后,我们却会发现结果是每隔一秒输出一个“undefined”,这是为什么呢?
通过闭包可以解决这个问题,代码如下所示。
1 | var arr = ['one', 'two', 'three']; |
**通过立即执行函数将索引i作为参数传入,在立即函数执行完成后,由于setTimeout()函数中有对arr变量的引用,其执行上下文环境不会被销毁,因此对应的i值都会存在内存中。**所以每次执行setTimeout()函数时,i都会是数组对应的索引值0、1、2,从而间隔一秒输出“one”“two”“three”。
3、作用域链问题
闭包往往会涉及作用域链问题,尤其是包含this属性时。
1 | var name = 'outer'; |
在调用obj.method()函数时,会返回一个匿名函数,而该匿名函数中返回的是this.name,因为引用到了this属性,在匿名函数中,this相当于一个外部变量,所以会形成一个闭包。
在JavaScript中,this指向的永远是函数的调用实体,而匿名函数的实体是全局对象window,因此会输出全局变量name的值“outer”。
1 | var name = 'outer'; |
4、多个相同函数名问题
1 | // 第一个foo()函数 |
在完成这道题目之前,我们需要搞清楚这3个foo()函数的指向。
首先最外层的foo()函数是一个具名函数,返回的是一个具体的对象。
第二个foo()函数是最外层foo()函数返回对象的一个属性,该属性指向一个匿名函数。
第三个foo()函数是一个被返回的函数,该foo()函数会沿着原型链向上查找,而foo()函数在局部环境中并未定义,最终会指向最外层的第一个foo()函数,因此第三个和第一个foo()函数实际是指向同一个函数。
第一行输出结果为“undefined,0,0,0”。
第二行输出结果为“undefined,0,1,2”。
第三行输出结果为“undefined,0,1,1”。
3.5.4 小结
3.5.4.1 闭包的优点
· 保护函数内变量的安全,实现封装,防止变量流入其他环境发生命名冲突,造成环境污染。
· 在适当的时候,可以在内存中维护变量并缓存,提高执行效率。
3.5.4.2 闭包的缺点
· 消耗内存:通常来说,函数的活动对象会随着执行上下文环境一起被销毁,但是,由于闭包引用的是外部函数的活动对象,因此这个活动对象无法被销毁,这意味着,闭包比一般的函数需要消耗更多的内存。
· 泄漏内存:在IE9之前,如果闭包的作用域链中存在DOM对象,则意味着该DOM对象无法被销毁,造成内存泄漏。
1 | function closure() { |
在closure()函数中,给一个element元素绑定了click事件,而在这个click事件中,输出了element元素的id属性,即在onclick()函数的闭包中存在了对外部元素element的引用,那么该element元素在网页关闭之前会一直存在于内存之中,不会被释放。如果这样的事件处理的函数很多,将会导致大量内存被占用,进而严重影响性能。
如果这样的事件处理的函数很多,将会导致大量内存被占用,进而严重影响性能。
对应的解决办法是:先将需要使用的属性使用临时变量进行存储,然后在事件处理函数时使用临时变量进行操作;此时闭包中虽然不直接引用element元素,但是对id值的调用仍然会导致element元素的引用被保存,此时应该手动将element元素设置为null。
1 | function closure() { |
3.6 this使用详解
当我们想要创建一个构造函数的实例时,需要使用new操作符,函数执行完成后,函数体中的this就指向了这个实例,通过下面这个实例可以访问到绑定在this上的属性。
1 | function Person(name) { |
假如我们将Person()函数当作一个普通的函数执行,其中的this又会指向谁呢?从哪个对象上可以访问到定义的name属性的值呢?
事实上,在window对象上,我们可以访问到name属性的值,这表明函数体中的this指向了window对象。
1 | function Person(name) { |
其实this这个概念并不是JavaScript所特有的,在java、c++等面向对象的语言中也存在this关键字。它们中的this概念很好理解,this指向的是当前类的实例对象。而在JavaScript中,this的指向是随着宿主环境的变化而变化的,在不同的地方调用,返回的可能是不同的结果。
在JavaScript中,this指向的永远是函数的调用者。
3.6.1 this指向全局对象
当函数没有所属对象而直接调用时,this指向的是全局对象,来看下面这段代码。
1 | var value = 10; |
当我们调用obj.method()函数时,foo()函数被执行,但是此时foo()函数的执行是没有所属对象的,因此this会指向全局的window对象,在输出this.value时,实际是输出window.value,因此输出“10”。
而method()函数的返回值是this.value,method()函数的调用体是obj对象,此时this就指向obj对象,而obj.value = 100,因此调用obj.method()函数后会返回“100”。
3.6.2 this指向所属对象
同样沿用场景1中的代码,我们修改最后一行代码,输出obj.method()函数的返回值。
1 | console.log(obj.method()); // 100 |
obj.method()函数的返回值是this.value,method()函数的调用体是obj对象,此时this就指向obj对象,而obj.value = 100,因此会输出“100”。
3.6.3 this指向对象实例
当通过new操作符调用构造函数生成对象的实例时,this指向该实例。
1 | // 全局变量 |
3.6.4 this指向call()函数、apply()函数、bind()函数调用后重新绑定的对象
通过call()函数、apply()函数、bind()函数可以改变函数执行的主体,如果函数中存在this关键字,则this也将会指向call()函数、apply()函数、bind()函数处理后的对象。
1 | // 全局变量 |
而在调用method.call(obj)时,将method()函数调用的主体改为obj对象,此时this指向的是obj对象,输出obj.value值,因此输出“20”。
apply()函数和bind()函数都会产生同样的效果,将函数指向的实体改为obj对象,因此后两个输出值也为“20”。
call()函数、apply()函数在改变函数的执行主体后,会立即调用该函数;而bind()函数在改变函数的执行主体后,并没有立即调用,而是可以在任何时候调用
在处理DOM事件处理程序中的this时,call()函数、apply()函数、bind()函数显得尤为有用,我们以bind()函数为例进行说明。
1 | var user = { |
但是当我们单击button按钮时,却会抛出异常。
1 | Uncaught TypeError: Cannot read property '1' of undefined |
这是为什么呢?
我们来看下异常信息栈便可以很好理解产生这种情况的原因。我们调用了一个undefined对象属性名为1的值,就是代码中this.data[1]的部分,间接可以表示出data为undefined。
这是因为当我们单击button按钮,触发click回调函数时,clickHandler()函数中的this指向的是button对象,而不是user对象,而button对象中是没有data属性的,因此data为undefined,从而抛出异常。
为了解决这个问题,我们需要将click回调函数中的this指向改变为user对象,而通过bind()函数可以达到这个目的。
button.onclick = user.clickHandler.bind(user);
修改完成后,再次单击button按钮,控制台会输出对应的结果。
1 | kingx2 43 |
3.6.5 闭包中的this
函数的this变量只能被自身访问,其内部函数无法访问。因此在遇到闭包时,闭包内部的this关键字无法访问到外部函数的this变量。
1 | var user = { |
在调用user.clickHandler()函数时,会执行到第9行代码,此时的this会指向user对象,因此可以访问到data属性,并进行forEach循环。**forEach循环实际是一个匿名函数,用于接收一个person参数,**表示每次遍历的数组中的值。
输出结果:
1 | kingx1 is playing undefined |
可以使用临时变量将clickHandler()函数的this提前进行存储,对其使用user对象,而在匿名函数中,使用临时变量访问sport属性,而不是直接用this访问。
1 | var user = { |
接下来我们通过一道题加深对this的理解。
1 | function f(k) { |
在执行f(1)的时候,因为f()函数的调用没有所属对象,所以this指向window,然后this.m=k语句执行后,相当于window.m = 1。通过return语句返回“window”,而又将返回值“window”赋值给全局变量m,因此变成了window.m = window,覆盖前面的window.m = 1。
在执行f(2)的时候,this同样指向window,此时window.m已经变成2,即window.m = 2,覆盖了window.m = window。通过return语句将window对象返回并赋值给n,此时window.n=window。
先看m.m的输出,m.m=(window.m).m,实际为2.m,2是一个数值型常量,并不存在m属性,因此返回“undefined”。再看n.m的输出,n.m=(window.n).m=window.m=2,因此输出“2”。
3.7 call、apply、bind函数的使用和区别
JavaScript中,每个函数都包含两个非继承而来的函数apply()和call(),这两个函数的作用是一样的,都是为了改变函数运行时的上下文而存在的,实际就是改变函数体内this的指向。
3.7.1 call()函数的基本使用
call()函数调用一个函数时,会将该函数的执行对象上下文改变为另一个对象。其语法如下所示。
1 | // function为需要调用的函数。 |
1 | // 定义一个add()函数 |
myAddCall()函数自身是不具备运算能力的,但是我们在myAddCall()函数中,通过调用add()函数的call()函数,并传入this值,将执行add()函数的主体改变为myAddCall()函数自身,然后传入参数x和y,这就使得myAddCall()函数拥有add()函数计算求和的能力。在实际计算时,就为10 + 20 = 30。
3.7.2 apply()函数的基本使用
1 | //定义一个add()函数 |
3.7.3 bind()函数的基本使用
bind()函数与call()函数接收的参数是一样的。其返回值是原函数的副本,并拥有指定的this值和初始参数。
1 | //定义一个add()函数 |
3.7.4 call、apply、bind的函数比较
三者的相同之处是:都会改变函数调用的执行主体,修改this的指向。
不同之处表现在以下两点。
1、第一点是关于函数立即执行,call()函数与apply()函数在执行后会立即调用前面的函数,而bind()函数不会立即调用,它会返回一个新的函数,可以在任何时候进行调用。
2、第二点是关于参数传递,call()函数与bind()函数接收的参数相同,第一个参数表示将要改变的函数执行主体,即this的指向,从第二个参数开始到最后一个参数表示的是函数接收的参数;而对于apply()函数,第一个参数与call()函数、bind()函数相同,第二个参数是一个数组,表示的是接收的所有参数,如果第二个参数不是一个有效的数组或者arguments对象,则会抛出一个TypeError异常。
3.7.5 call、apply、bind的函数用法
1、求数组中的最大项和最小项
Array数组本身没有max()函数和min()函数,无法直接获取到最大值和最小值,但是Math却有求最大值和最小值的max()函数和min()函数。我们可以使用apply()函数来改变Math.max()函数和Math.min()函数的执行主体,然后将数组作为参数传递给Math.max()函数和Math.min()函数。
1 | // 原生用法 |
2、类数组对象转换为数组对象
函数的参数对象arguments是一个类数组对象,自身不能直接调用数组的方法,但是我们可以借助call()函数,让arguments对象调用数组的slice()函数,从而得到一个真实的数组,后面就能调用数组的函数。
任意个数字的求和的代码如下所示。
1 | // 任意个数字的求和 |
3、用于继承
之前我们将会讲到继承的几种实现方式,其中的构造继承就会用到call()函数。
1 | // 父类 |
其中关键的语句是子类中的Animal.call(this, age),在call()函数中传递this,表示的是将Animal构造函数的执行主体转换为Cat对象,从而在Cat对象的this上会增加age属性和sleep函数,子类实际相当于如下代码。
1 | function Cat(name, age) { |
4、执行匿名函数
假如存在这样一个场景,有一个数组,数组中的每个元素是一个对象,对象是由不同的属性构成,现在我们想要调用一个函数,输出每个对象的各个属性值。
1 | var animals = [ |
在上面的代码中,在call()函数中传入animals[i],这样匿名函数内部的this就指向animals[i],在调用print()函数时,this也会指向animals[i],从而能输出speices属性和name属性。
5、bind()函数配合setTimeout
**在默认情况下,使用setTimeout()函数时,this关键字会指向全局对象window。**当使用类的函数时,需要this引用类的实例,我们可能需要显式地把this绑定到回调函数以便继续使用实例。
1 | // 定义一个函数 |
4、对象
JavaScript虽然是一门弱类型语言,但它同样是一门面向对象的语言,严格来说它是一门基于原型的面向对象的语言
4.1 对象的属性和访问方式
4.1.1 对象的属性
对象的属性可以分为数据属性和访问器属性
1、数据属性
数据属性具有4个描述其行为的特性,因为这些特性是内部值,所以ECMA-262规范将其放在了两对方括号中。
· [[Configurable]]:表示属性能否删除而重新定义,或者是否可以修改为访问器属性,默认值为true。
· [[Enumerable]]:表示属性是否可枚举,可枚举的属性能够通过for…in循环返回,默认值为true。
· [[Writable]]:表示属性值能否被修改,默认值为true。
· [[Value]]:表示属性的真实值,属性的读取和写入均通过此属性完成,默认值为undefined。
1 | // 定义对象 name属性的[[Configurable]]、[[Enumerable]]、[[Writable]]特性值都为true,[[Value]]特性值为'kingx'。 |
如果需要修改数据属性默认的特性,则必须使用Object.defineProperty()函数,语法如下。
1 | // 其中target表示目标对象,property表示将要修改特性的属性,第三个参数是一个描述符对象,描述符对象的属性必须为configurable、enumerable、writable、value |
2、访问器属性
访问器属性同样包含4个特性,分别是[[Configurable]]、[[Enumerable]]、[[Get]]和[[Set]]。
· [[Configurable]]:表示属性能否删除而重新定义,或者是否可以修改为访问器属性,默认值为true。
· [[Enumerable]]:表示属性是否可枚举,可枚举的属性能够通过for…in循环返回,默认值为true。
· [[Get]]:在读取属性值时调用的函数(一般称为getter()函数),负责返回有效的值,默认值为undefined。
· [[Set]]:在写入属性值时调用的函数(一般称为setter()函数),负责处理数据,默认值为undefined。
如果需要修改访问器属性默认的特性,则必须使用Object.defineProperty()函数。
getter()函数和setter()函数的存在在一定程度上可以实现对象的私有属性,私有属性不对外暴露。如果想要读取和写入私有属性的值,则需要通过设置额外属性的getter()函数和setter()函数来实现
1 | var person = { |
4.1.2 属性访问方式
(1)使用“。”来访问属性
(2)使用“[]”来访问属性
点操作符是静态的,只能是一个以属性名称命名的简单描述符,而且无法修改;而中括号操作符是动态的,可以传递字符串或者变量,并且支持在运行时修改。点操作符不能以数字作为属性名,而中括号操作符可以。
4.2 对象的创建
4.2.1 基于Object()构造函数
通过Object对象的构造函数生成一个实例,然后给它增加需要的各种属性。
1 | // Object()构造函数生成实例 |
4.2.2 基于对象字面量
对象字面量本身就是一系列键值对的组合,每个属性之间通过逗号分隔。
1 | var person = { |
方法1与方法2在创建对象时都具有相同的优点,即简单、容易理解。但是对象的属性值是通过对象自身进行设置的,如果需要同时创建若干个属性名相同,而只是属性值不同的对象时,则会产生很多的重复代码,造成代码冗余,因此不推荐使用方法1与方法2来批量创建对象。
4.2.3 基于工厂方法模式
工厂方法模式是一种比较重要的设计模式,用于创建对象,旨在抽象出创建对象和属性赋值的过程,只对外暴露出需要设置的属性值。
1 | // 工厂方法,对外暴露接收的name、age、address属性值 |
使用工厂方法可以减少很多重复的代码,但是创建的所有实例都是Object类型,无法更进一步区分具体的类型。
4.2.4 基于构造函数模式
构造函数是通过this为对象添加属性的,属性值类型可以为基本类型、对象或者函数,然后通过new操作符创建对象的实例。
1 | // 构造函数 |
构造函数问题:使用构造函数创建的对象可以确定其所属类型,解决了方法3存在的问题。但是使用构造函数创建的对象存在一个问题,即相同实例的函数是不一样的。
1 | var person = new Person('kingx', 11, { |
就意味着每个实例的函数都会占据一定的内存空间,其实这是没有必要的,会造成资源的浪费,另外函数也没有必要在代码执行前就绑定在对象上。
4.2.5 基于原型对象的模式
基于原型对象的模式是将所有的函数和属性都封装在对象的prototype属性上。
1 | // 定义函数 |
通过上面的代码可以发现,使用基于原型对象的模式创建的实例,其属性和函数都是相等的,不同的实例会共享原型上的属性和函数,解决了方法4存在的问题。
但是方法5也存在一个问题,因为所有的实例会共享相同的属性,那么改变其中一个实例的属性值,便会引起其他实例的属性值变化,这并不是我们所期望的。
1 | var person = new Person(); |
4.2.6 构造函数和原型混合的模式(常用)
构造函数中用于定义实例的属性,原型对象中用于定义实例共享的属性和函数。通过构造函数传递参数,这样每个实例都能拥有自己的属性值,同时实例还能共享函数的引用,最大限度地节省了内存空间
1 | // 构造函数中定义实例的属性 |
4.2.7 基于动态原型模式
动态原型模式是将原型对象放在构造函数内部,通过变量进行控制,只在第一次生成实例的时候进行原型的设置。
动态原型的模式相当于懒汉模式,只在生成实例时设置原型对象,但是功能与构造函数和原型混合模式是相同的。
1 | // 动态原型模式 |
4.3 对象克隆
针对不同的数据类型,浅克隆和深克隆会有不同的表现,主要表现于基本数据类型和引用数据类型在内存中存储的值不同。
对于基本数据类型的值,变量存储的是值本身,存放在栈内存的简单数据段中,可以直接进行访问。
对于引用类型的值,变量存储的是值在内存中的地址,地址指向内存中的某个位置。如果有多个变量同时指向同一个内存地址,则其中一个变量对值进行修改时,会影响到其他的变量。
4.3.1 对象浅克隆
浅克隆由于只克隆对象最外层的属性,如果对象存在更深层的属性,则不进行处理,这就会导致克隆对象和原始对象的深层属性仍然指向同一块内存
1、简单的引用复制
1 | /** |
2、ES6的Object.assign()函数
在ES6中,Object对象新增了一个assign()函数,用于将源对象的可枚举属性复制到目标对象中。
1 | var origin = { |
浅克隆实现方案都会存在一个相同的问题,即如果原始对象是引用数据类型的值,则对克隆对象的值的修改会影响到原始对象的值。
4.3.2 对象深克隆
1、JSON序列化和反序列化
如果一个对象中的全部属性都是可以序列化的,那么我们可以先使用JSON.stringify()函数将原始对象序列化为字符串,再使用JSON.parse()函数将字符串反序列化为一个对象,这样得到的对象就是深克隆后的对象。
1 | var origin = { |
这种方法能够解决大部分JSON类型对象的深克隆问题,但是对于以下几个问题不能很好地解决。
- 无法实现对函数、RegExp等特殊对象的克隆。
- 对象的constructor会被抛弃,所有的构造函数会指向Object,原型链关系断裂。
- 对象中如果存在循环引用,会抛出异常。
关于循环引用,我们同样列举一个特定的实例。
定义一个原始对象,为原始对象添加一个属性指向自身,形成循环引用。
1 | var origin = { |
2、自定义实现深克隆
1 | /** |
4.4 原型对象
在3.3节构造函数中,我们留下了一个问题,即单纯通过构造函数创建实例会导致函数在不同实例中重复创建,这该如何解决呢?
1 | function Person(name, age) { |
因此使用prototype属性就很好地解决了单纯通过构造函数创建实例会导致函数在不同实例中重复创建的问题。
4.4.1 原型对象、构造函数、实例之间的关系
1、原型对象、构造函数和实例之间的关系是什么样的?
2、使用原型对象创建了对象的实例后,实例的属性读取顺序是什么样的?
3、假如重写了原型对象,会带来什么样的问题?
1、原型对象、构造函数和实例之间的关系
每一个函数在创建时都会被赋予一个prototype属性。在默认情况下,所有的原型对象都会增加一个constructor属性,指向prototype属性所在的函数,即构造函数。
当我们通过new操作符调用构造函数创建一个实例时,实例具有一个__proto__属性,指向构造函数的原型对象,因此__proto__属性可以看作是一个连接实例与构造函数的原型对象的桥梁。
1 | function Person(){} |
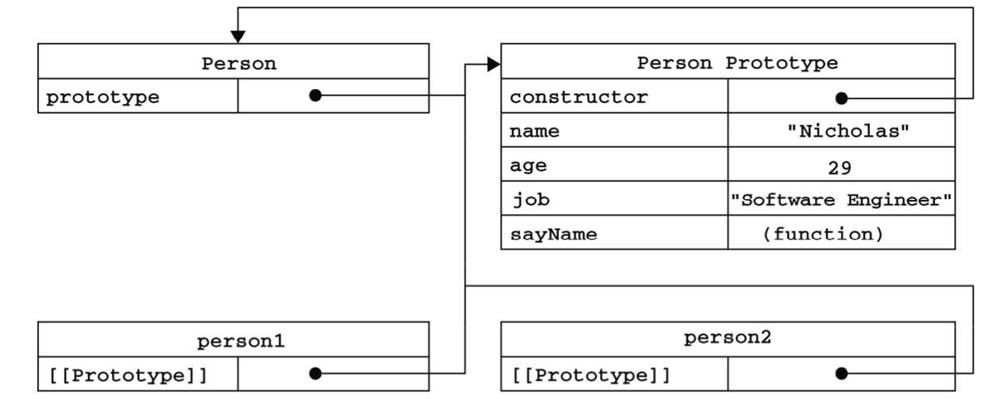
构造函数Person有个prototype属性,指向的是Person的原型对象。在原型对象中有constructor属性和另外4个原型对象上的属性,其中constructor属性指向构造函数本身
通过new操作符创建的两个实例person1和person2,都具有一个__proto__属性(上图中的[[Prototype]]即__proto__属性),指向的是Person的原型对象。
2、实例的属性读取顺序
当我们通过对象的实例读取某个属性时,是有一个搜索过程的。它会先在实例本身去找指定的属性,如果找到了,则直接返回该属性的值;如果没找到,则会继续沿着原型对象寻找;如果在原型对象中找到了该属性,则返回该属性的值。
1 | function Person() { |
改造:
1 | function Person() { |
3、假如重写了原型对象,会带来什么样的问题
在之前的代码中,每次为原型对象添加一个属性或者函数时,都需要手动写上Person.prototype,这是一种冗余的写法。我们可以将所有需要绑定在原型对象上的属性写成一个对象字面量的形式,并赋值给prototype属性。
1 | function Person() {} |
将一个对象字面量赋给prototype属性的方式实际是重写了原型对象,等同于切断了构造函数和最初原型之间的关系。因此有一点需要注意的是,如果仍然想使用constructor属性做后续处理,则应该在对象字面量中增加一个constructor属性,指向构造函数本身,否则原型的constructor属性会指向Object类型的构造函数,从而导致constructor属性与构造函数的脱离。
1 | function Person() {} |
通过结果,我们发现Person的原型对象的constructor属性不再指向Person()构造函数,而是指向Object类型的构造函数了。
由于重写原型对象会切断构造函数和最初原型之间的关系,因此会带来一个隐患,那就是如果在重写原型对象之前,已经生成了对象的实例,则该实例将无法访问到新的原型对象中的函数。
1 | function Person() {} |
上面的实例就是在提醒我们,如果想要重写原型对象,需要保证不要在重写完成之前生成对象的实例,否则会出现异常。
4.4.2 原型链
在前面有讲过,对象的每个实例都具有一个__proto__属性,指向的是构造函数的原型对象,而原型对象同样存在一个__proto__属性指向上一级构造函数的原型对象,就这样层层往上,直到最上层某个原型对象为null。
在JavaScript中几乎所有的对象都具有__proto__属性,由__proto__属性连接而成的链路构成了JavaScript的原型链,原型链的顶端是Object.prototype,它的__proto__属性为null。
我们通过实例来看看一个简单的原型链过程。首先定义一个构造函数,并生成一个实例。
1 | function Person() {} |
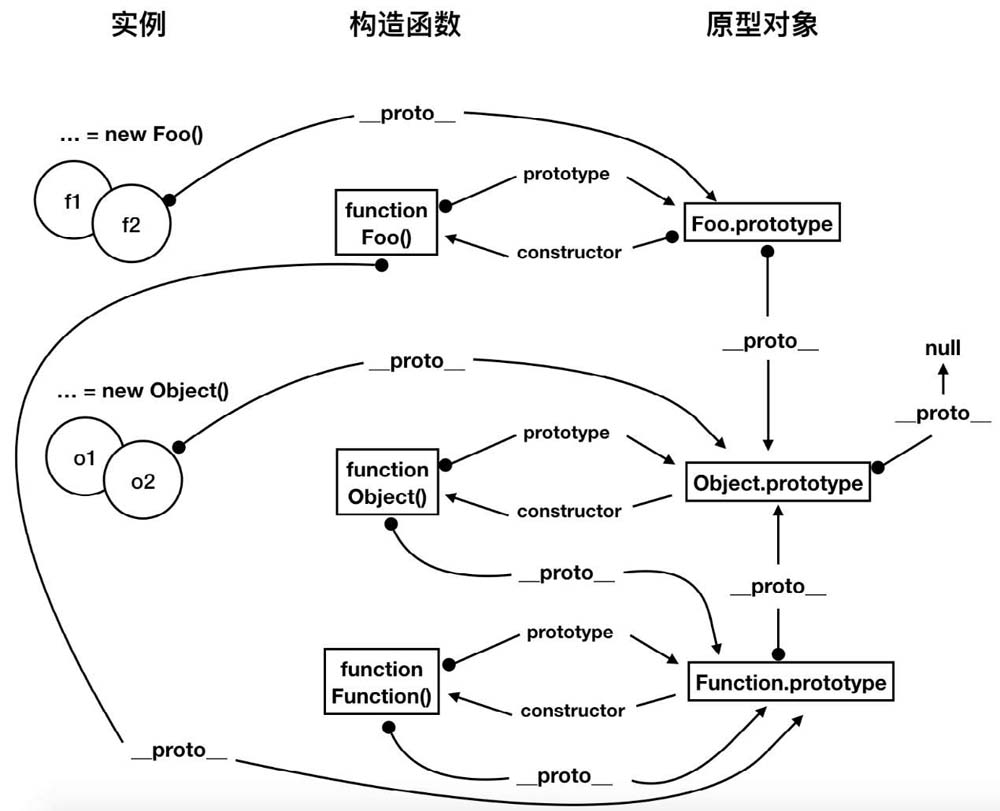
4.4.2.1 原型链的特点
1、特点一:由于原型链的存在,属性查找的过程不再是只查找自身的原型对象,而是会沿着整个原型链一直向上,直到追溯到Object.prototype
2、特点2:由于属性查找会经历整个原型链,因此查找的链路越长,对性能的影响越大。
4.4.2.2 属性区分
对象属性的寻找往往会涉及整个原型链,那么该怎么区分属性是实例自身的还是从原型链中继承的呢?
在使用for…in运算符遍历对象的属性时,一般可以配合hasOwnProperty()函数一起使用,检测是否是对象自身的属性,然后做后续处理。
1 | function Person(name) { |
4.4.2.3 内置构造函数
JavaScript中有一些特定的内置构造函数,如String()构造函数、Number()构造函数、Array()构造函数、Object()构造函数等。它们本身的__proto__属性都统一指向Function.prototype。
它们本身的__proto__属性都统一指向Function.prototype。
1 | String._ _proto_ _ === Function.prototype; // true |
4.4.2.4 __protot__属性
在JavaScript的原型链体系中,最重要的莫过于__proto__属性,只有通过它才能将原型链串联起来。
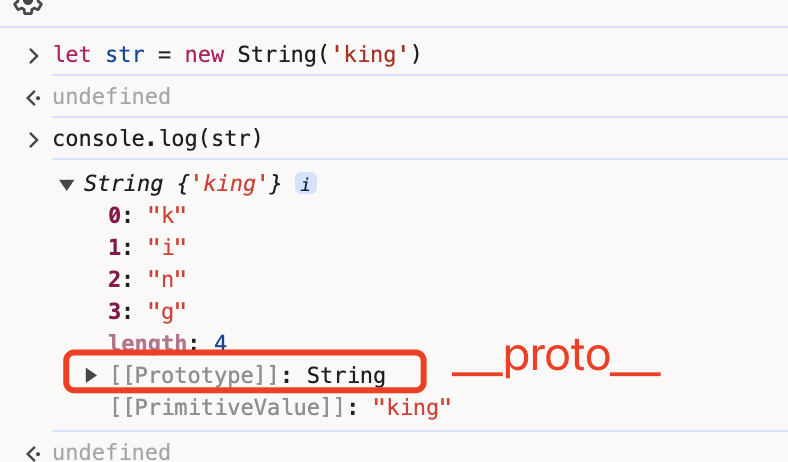
但是我们在调用str.substring(1, 3)时,却不会报错,这是为什么呢?
因为__proto__属性可以沿着原型链找到String.prototype中的函数,而substring()函数就在其中。
了解了以上内容后,我们再通过下面这段代码,加深对原型链知识的理解。
1 | Function.prototype.a = 'a'; |
4.5 继承
继承作为面向对象语言的三大特性之一,可以在不影响父类对象实现的情况下,使得子类对象具有父类对象的特性;同时还能在不影响父类对象行为的情况下扩展子类对象独有的特性,为编码带来了极大的便利。
1 | // 定义一个父类Animal |
4.5.1 原型链继承
原型链继承的主要思想是:重写子类的prototype属性,将其指向父类的实例。
1 | // 子类Cat |
在子类Cat中,我们没有增加type属性,因此会直接继承父类Animal的type属性,输出字符串“Animal”。
在子类Cat中,我们增加了name属性,在生成子类Cat的实例时,name属性值会覆盖父类Animal的name属性值,因此输出字符串“加菲猫”,而并不会输出父类Animal的name属性“动物”。
**同样因为Cat的prototype属性指向了Animal类型的实例,因此在生成实例cat时,会继承实例函数和原型函数,在调用sleep()函数和eat()函数时,this指向了实例cat,**从而输出“加菲猫正在睡觉!”和“加菲猫正在吃:猫粮”。
4.5.1.1 原型链继承的优点
(1)简单,易于实现
(2)继承关系纯粹
1 | // 生成的实例既是子类的实例,也是父类的实例。 |
(3)可通过子类直接访问父类原型链属性和函数
通过原型链继承的子类,可以直接访问到父类原型链上新增的函数和属性。
继续沿用前面的代码,我们通过在父类的原型链上添加属性和函数进行测试
1 | // 父类原型链上增加属性 |
4.5.1.2 原型链继承的缺点
(1)子类的所有实例将共享父类的属性
在使用原型链继承时,是直接改写了子类Cat的prototype属性,将其指向一个Animal的实例,那么所有生成Cat对象的实例都将共享Animal实例的属性。
1 | // 生成一个Animal的实例animal |
这就会带来一个很严重的问题,如果父类Animal中有个值为引用数据类型的属性,那么改变Cat某个实例的属性值将会影响其他实例的属性值。
1 | // 定义父类 |
(2)在创建子类实例时,无法向父类的构造函数传递参数
在通过new操作符创建子类的实例时,会调用子类的构造函数,而在子类的构造函数中并没有设置与父类的关联,从而导致无法向父类的构造函数传递参数。
(3)无法实现多继承
由于子类Cat的prototype属性只能设置为一个值,如果同时设置为多个值的话,后面的值会覆盖前面的值,导致Cat只能继承一个父类,而无法实现多继承。
(4)为子类增加原型对象上的属性和函数时,必须放在new Animal()函数之后
如果想要为子类新增原型对象上的属性和函数,那么需要在这个语句之后进行添加。因为如果在这个语句之前设置了prototype属性,后面执行的语句会直接重写prototype属性,导致之前设置的全部失效。
1 | Cat.prototype = new Animal(); |
4.5.2 构造继承
构造继承的主要思想是在子类的构造函数中通过call()函数改变this的指向,调用父类的构造函数,从而能将父类的实例的属性和函数绑定到子类的this上。
1 | // 父类 |
4.5.2.1 构造函数的优点
(1)可解决子类实例共享父类属性的问题
call()函数实际是改变了父类Animal构造函数中this的指向,调用后this指向了子类Cat,相当于将父类的type、age和sleep等属性和函数直接绑定到了子类的this中,成了子类实例的属性和函数,因此生成的子类实例中是各自拥有自己的type、age和sleep属性和函数,不会相互影响。
(2)创建子类的实例时,可以向父类传递参数
在call()函数中,我们可以传递参数,这个时候参数是传递给父类的,我们就可以对父类的属性进行设置,同时由子类继承下来。
1 | function Cat(name, parentAge) { |
(3)可以实现多继承
在子类的构造函数中,可以通过多次调用call()函数来继承多个父对象,每调用一次call()函数就会将父类的实例的属性和函数绑定到子类的this中。
4.5.2.2 构造函数的缺点
(1)实例只是子类的实例,并不是父类的实例
因为我们并未通过原型对象将子类与父类进行串联,所以生成的实例与父类并没有关系,这样就失去了继承的意义。
1 | var cat = new Cat('tony'); |
(2)只能继承父类实例的属性和函数,并不能继承原型对象上的属性和函数
子类的实例并不能访问到父类原型对象上的属性和函数。
(3)无法复用父类的实例函数
由于父类的实例函数将通过call()函数绑定到子类的this中,因此子类生成的每个实例都会拥有父类实例函数的引用,这会造成不必要的内存消耗,影响性能。
4.5.3 复制继承
复制继承的主要思想是首先生成父类的实例,然后通过for…in遍历父类实例的属性和函数,并将其依次设置为子类实例的属性和函数或者原型对象上的属性和函数。
1 | // 父类 |
4.5.3.1 复制继承的优点
(1)支持多继承
只需要在子类的构造函数中生成多个父类的实例,然后通过相同的for…in处理即可。
(2)能同时继承实例的属性和函数与原型对象上的属性和函数
(3)可以向父类构造函数中传递值
在生成子类的实例时,可以在构造函数中传递父类的属性值,然后在子类构造函数中,直接将值传递给父类的构造函数。
1 | function Cat(name, age) { |
4.5.3.2 复制继承的缺点
(1)父类的所有属性都需要复制,消耗内存
(2)实例只是子类的实例,并不是父类的实例
实际上我们只是通过遍历父类的属性和函数并将其复制至子类上,并没有通过原型对象串联起父类和子类,因此子类的实例不是父类的实例。
1 | console.log(cat instanceof Cat); // true |
4.5.4 组合继承
组合继承的主要思想是组合了构造继承和原型继承两种方法,一方面在子类的构造函数中通过call()函数调用父类的构造函数,将父类的实例的属性和函数绑定到子类的this中;另一方面,通过改变子类的prototype属性,继承父类的原型对象上的属性和函数。
1 | // 父类 |
4.5.4.1 组合继承的优点
(1)既能继承父类实例的属性和函数,又能继承原型对象上的属性和函数
一方面,通过Animal.call(this)可以将父类实例的属性和函数绑定到Cat构造函数的this中;另一方面,通过Cat.prototype = new Animal()可以将父类的原型对象上的属性和函数绑定到Cat的原型对象上。
(2)既是子类的实例,又是父类的实例
1 | console.log(cat instanceof Cat); // true |
(3)不存在引用属性共享的问题
因为在子类的构造函数中已经将父类的实例属性指向了子类的this,所以即使后面将父类的实例属性绑定到子类的prototype属性中,也会因为构造函数作用域优先级比原型链优先级高,所以不会出现引用属性共享的问题。
(4)可以向父类的构造函数中传递参数
通过call()函数可以向父类的构造函数中传递参数。
4.5.4.2 组合继承的缺点
组合继承的缺点为父类的实例属性会绑定两次。
在子类的构造函数中,通过call()函数调用了一次父类的构造函数;在改写子类的prototype属性、生成父类的实例时调用了一次父类的构造函数。
通过两次调用,父类实例的属性和函数会进行两次绑定,一次会绑定到子类的构造函数的this中,即实例属性和函数,另一次会绑定到子类的prototype属性中,即原型对象上的属性和函数,但是实例属性优先级会比原型对象上的属性优先级高,因此实例属性会覆盖原型对象上的属性。
4.5.5 寄生组合继承
事实上4.5.4组合继承的方案已经足够好,但是针对其存在的缺点,我们仍然可以进行优化。
在进行子类的prototype属性的设置时,可以去掉父类实例的属性和函数。
1 | // 子类 |
关键语句,只取父类Animal的prototype属性,过滤掉Animal的实例属性,从而避免了父类的实例属性绑定两次。
寄生组合继承的方式是实现继承最完美的一种,但是实现起来较为复杂,一般不太容易想到。
在大多数情况下,使用组合继承的方式就已经足够,当然能够使用寄生组合继承更好。
4.6 instanceof运算符
4.4节讲到了原型链中属性的查找过程需要确定对象实例的__proto__属性的指向,那么我们该如何确定一个对象是不是某个构造函数的实例,从而确定它的原型链呢?这就需要运用本节将要讲到的instanceof运算符的知识点了。
我们讲过typeof运算符,在判断一个变量的类型时,我们总是优先使用它。但是使用typeof运算符时,存在一个比较大的问题,即对于任何引用数据类型的值都会返回“object”,从而无法判断对象的具体类型
1 | target instanceof constructor |
上面的代码表示的是构造函数constructor()的prototype属性是否出现在target对象的原型链中,说得通俗一点就是,target对象是不是构造函数constructor()的实例。
4.6.1 instanceof运算符常规用法
1 | var stringObject = new String('hello world'); |
上面两行代码是判断变量stringObject是否是String类型的实例,因为变量stringObject是通过new操作符,由String的构造函数生成的,所以变量stringObject是String类型的实例,最终返回“true”。
1 | function Foo() {} |
4.6.2 instanceof运算符用于继承判断
instanceof运算符除了前面介绍的常规用法外,还有很重要的一点就是可以在继承关系中,判断一个实例对象是否属于它的父类。
1 | // 定义构造函数 |
需要注意的一点是,如果一个表达式obj instanceof Foo返回“true”,并不意味着这个表达式会永远返回“true”,我们可以有两种方法改变这个结果。
第一种方法是改变Foo.prototype属性值,使得改变后的Foo. prototype不在实例obj的原型链上。
1 | // 现在我们修改D.prototype属性,将其指向一个空对象。 |
第二种方法是改变实例obj的原型链,使得改变后的Foo()构造函数不在实例obj的原型链上。
在目前的ECMAScript规范中,某个对象实例的原型是只读而不能修改的,但是该规范提供了一个非标准的__proto__属性,用于访问其构造函数的原型对象。
1 | o3._ _proto_ _ = {}; |
4.6.3 instanceof运算符的复杂用法
1 | Object instanceof Object; //true |
看完上面这段代码,大家是不是又疑惑重重呢?为什么Object()构造函数和Function()构造函数在使用instanceof运算符处理自身的时候会返回“true”,而Number()构造函数和String()构造函数在使用instanceof运算符处理自身的时候返回“false”呢?
接下来我们将通过底层原理来看看instanceof运算符是怎么进行处理的。
1 | /** |
对上面代码的理解如下。
- 获取右表达式R的prototype属性为O,左表达式的__proto__隐式原型为L。
- 首先判断左表达式__proto__隐式原型L是否为空,如果为空,则直接返回“false”。实际上只有Object.prototype.__proto__属性为null,即到了原型链的最顶层。
- 然后判断O与L是否严格相等,需要注意的是只有在严格相等的时候,才返回“true”。
- 如果不相等,则递归L的__proto__属性,直到L为null或者O===L,得到最终结果。
在了解instanceof运算符的执行机制之后,再结合上一节中讲到的基于prototype属性的原型链,就可以对任何instanceof运算符的操作处理得更加游刃有余。
4.6.4 instanceof运算符的复杂用法的详细处理过程
4.6.4.1 Object instanceof Object
基于instanceof运算符的原理,需要区分运算符左侧值和右侧值
1 | // 将左、右侧值进行赋值 |
因此Object instanceof Object返回“true”。
4.6.4.2 Function instanceof Function
1 | // 将左、右侧值进行赋值 |
因此Function instanceof Function返回“true”。
4.6.4.3 Foo instanceof Foo
1 | // 将左、右侧值进行赋值 |
4.6.4.4 String instanceof String
1 | // 将左、右侧值进行赋值 |
5、DOM与事件
待补充
6、Ajax
待补充
7、ES6
7.1 let和const关键字
其实在ES6之前,只存在全局作用域和函数作用域,并不存在块级作用域,这就会导致变量提升的问题。
1 | { |
7.1.1 let关键字
let关键字用于声明变量,和var关键字的用法类似。但是与var不同的是,let声明的变量只能在let所在的代码块内有效,即在块级作用域内有效,而var声明的变量在块级作用域外仍然有效。
1 | { |
1、 let关键字的特性
(1)不存在变量提升
(2)存在暂时性死区
在使用let声明变量之前,该变量都是不可访问的。
1 | if (true) { |
(3)不能重复声明
(4)不再是全局对象的属性
在ES6以前,在浏览器环境的全局作用域下,使用var声明的变量、函数表达式或者函数声明均是window对象的属性。
2、 let关键字的好处
(1)不会导致for循环索引值泄露
1 | var arr = []; |
我们发现通过var定义的索引i值,在调用函数时,最终会输出“10”,这是为什么呢?
因为通过var声明的索引i是一个全局变量,每一次循环,全局变量i都会发生改变。而数组arr所有成员里面的i都指向同一个i,当循环结束后,全局变量i的值已经变为10。
最终在调用成员函数时,每个函数都闭包了全局变量i,因此会输出“10”。
1 | var arr = []; |
这是因为通过let定义的索引值i,只在当前循环内有效,实际上每一轮循环中的i都是一个新的变量,而且最关键的是JavaScript引擎能够记住上一轮循环的值,所以在本轮循环开始时,会基于上一轮循环计算,从而索引i的值会递增。
因此在调用arr数组的成员函数时,会输出正确的索引i值。
为什么通过let声明的变量i在循环体外,仍然可以访问呢?这是因为arr数组的每个成员都是一个函数,对变量i的引用构成了一个闭包,所以在循环体外调用函数时仍然可以访问到i。
1 | for (let i = 0; i < 2; i++) { |
根据let的特点,如果在同一个代码块中同时使用let定义了具有相同名称的变量,则会直接抛出异常。
而在上面的例子中,小括号内和循环体内同时使用let声明了变量i,但是在循环体内仍然可以输出变量i的值,就表明这两个变量i是处在两个独立的父子作用域中的。
(2)避免出现变量提升导致的变量覆盖问题
1 | var arg1 = 'kingx'; |
在上面的实例中,定义了一个全局变量arg1,在foo()函数中想要输出变量arg1,但是由于变量提升的存在,if代码块内的变量arg1会被提升至foo()函数顶部,导致输出arg1时覆盖了外层的全局变量arg1,因此输出“undefined”。
(3)代替立即执行函数IIFE
1 | // I IFE 写法 |
7.1.2 const关键字
使用const声明常量时,在声明时就必须初始化。如果只声明,不初始化,则会抛出异常。
我们所讲的使用const声明的变量不能被修改,严格意义来说是保存变量值的内存地址不能被修改。
1 | const person = { |
7.2 解构赋值
7.2.1 数组的解构赋值
1 | let [, , num3] = [12, 34, 56]; |
1、数组解构默认值
1 | let [ |
2、交换变量
1 | var a = 1; |
3、解析函数返回的数组
1 | function fn() { |
4、嵌套数组的解构
1 | let [num1, num2, [num3]] = [12, [34, 56], [78, 89]]; |
5、函数参数解构
1 | function foo([arg1, arg2]) { |
上述实例中,foo()函数的实参为[2, 3],形参为[arg1, arg2],使用数组的解构赋值时,得到变量arg1的值为“2”,变量arg2的值为“3”。
7.2.2 对象的解构赋值
在ES6中,对象同样可以进行解构赋值。数组的解构赋值是基于数组元素的索引,只要左右两侧的数组元素索引相同,便可以进行解构赋值。但是在对象中,属性是没有顺序的,这就要求右侧解构对象的属性名和左侧定义对象的变量名必须相同,这样才可以进行解构。
1 | let {m, n, o} = {m: 'kingx', n: 12}; |
1 | let {m: name, n: age} = {m: 'kingx', n: 12}; |
1、对象解构的默认值
1 | let {m, n = 1, o = true} = {m: ‘kingx’, o: null}; |
当属性名和变量名不相同时,默认值是赋给变量的。
1 | let {m, n: age = 1} = {m: 'kingx'}; |
2、嵌套对象的解构
嵌套的对象同样可以进行解构,解构时从最外层对象向内部逐层进行,每一层对象值都遵循相同的解构规则。
1 | let obj = { |
当父层对象对应的属性不存在,而解构子层对象时,会出错并抛出异常。
1 | let obj = { |
因为在obj对象中,外层的属性名是m,而在左侧的对象中,外层属性名是o,两者并不匹配,所以o会解构得到“undefined”。而对undefined再次解构想要获取n属性时,相当于调用undefined.n,会抛出异常。
3、选择性解构对象的属性
1 | let { min, max } = Math; |
4、函数参数解构
当函数的参数是一个复杂的对象类型时,我们可以通过解构去获得想要获取的值并赋给变量。
1 | function whois({displayName: displayName, fullName: {firstName: name}}) |
7.3 扩展运算符和rest运算符
在ES6中新增了两种运算符,一种是扩展运算符,另一种是rest运算符。这两种运算符可以很好地解决函数参数和数组元素长度未知情况下的编码问题,使得代码能更加健壮和简洁。
7.3.1 扩展运算符
扩展运算符用3个点表示(…),用于将一个数组或类数组对象转换为用逗号分隔的值序列。
它的基本用法是拆解数组和字符串。
1 | const array = [1, 2, 3, 4]; |
1、扩展运算符代替apply()函数
扩展运算符可以代替apply()函数,将数组转换为函数参数。
例如,获取数组最大值时,使用apply()函数的写法如下所示。
1 | let arr = [1, 4, 6, 8, 2]; |
自定义一个add()函数,用于接收两个参数,并返回两个参数相加的和。当传递的参数是一个数组时,如果使用apply()函数,写法如下。
1 | function add (num1, num2) { |
2、扩展运算符代替concat()函数合并数组
1 | let arr1 = [1, 2, 3]; |
3、扩展运算符转换Set,得到去重的数组
Set具有自动的去重性质,我们可以再次使用扩展运算符将Set结构转换成数组。
1 | let arr = [1, 2, 4, 6, 2, 7, 4]; |
4、扩展运算符用于对象克隆
1 | let obj = {name: 'kingx'}; |
我们再来看看下面这个例子,这是克隆对象的属性值为引用数据类型的场景。
1 | let obj3 = { |
在上面的实例中,obj3对象包含name和address两个属性,其中address属性值为引用数据类型。在使用扩展运算符副本后得到obj4对象,对obj4对象的name属性和address.city属性进行修改然后输出obj3对象,发现name属性值并未修改,而address.city值变为了shenzhen。表明对克隆后对象的值进行更改后,影响到了被克隆的对象,这就意味着使用扩展运算符的克隆并不是严格的深克隆。
当数组的元素为基本数据类型时,可以实现深克隆,而数组中出现引用数据类型元素的时候,就不再是深克隆。
1 | let arr1 = [1, 3, 4, 6]; // 可以进行深克隆 |
使用扩展运算符对数组或对象进行克隆时,如果数组的元素或者对象的属性是基本数据类型,则支持深克隆;如果是引用数据类型,则不支持深克隆。归根结底是因为引用数据类型的克隆只是复制了引用的地址,克隆后的对象仍然共享同一个引用地址。
7.3.2 rest运算符
rest运算符同样使用3个点表示(…),其作用与扩展运算符相反,用于将以逗号分隔的值序列转换成数组。
1、rest运算符与解构组合使用
1 | let arr = ['one', 'two', 'three', 'four']; |
需要注意的是,如果想要使用rest运算符进行解构,则rest运算符对应的变量应该放在最后一位,否则就会抛出异常。因为如果rest运算符不是放在最后一位,变量并不知道要读取多少个数值。
1 | let arr = ['one', 'two', 'three', 'four']; |
1 | let {x, y, ...z} = {x: 1, y: 2, a: 3, b: 4}; |
2、rest运算符代替arguments处理函数参数
在ES6之前,如果我们不确定传入的参数长度,可以统一使用arguments来获取所有传递的参数。
1 | function foo() { |
函数的参数是一个使用逗号分隔的值序列,可以使用rest运算符处理成一个数组,从而确定最终传入的参数,以代替arguments的使用。
1 | function foo(...args) { |
通过以上对扩展运算符和rest运算符的讲解,我们知道其实两者是互为逆运算的,扩展运算符是将数组分割成独立的序列,而rest运算符是将独立的序列合并成一个数组。
既然两者都是通过3个点(…)来表示的,那么如何去判断这3个点(…)属于哪一种运算符呢?我们可以遵循下面的规则。
· 当3个点(…)出现在函数的形参上或者出现在赋值等号的左侧,则表示它为rest运算符。
· 当3个点(…)出现在函数的实参上或者出现在赋值等号的右侧,则表示它为扩展运算符。
7.4 模版字符串
7.4.1 字符串原生输出
1 | // 传统字符串方案 |
而使用模板字符串语法,会保留字符串内部的空白、缩进和换行符。
1 | let str2 = `Hello, my name is kingx, |
7.4.2 字符串变量值传递
1、模板字符串中传递表达式
1 | // 数学运算 |
2、模板字符串中传递复杂引用数据类型的变量
1 | const tmpl = function (addrs) { |
输出的字符串结果如下所示。
1 | </table> |
7.5 箭头函数
1 | // ES6语法 |
7.5.1 箭头函数的特点
7.5.1.1 不绑定this
在3.6节中我们有讲解过this的指向问题,得出的结论是:this永远指向函数的调用者。但是在箭头函数中,this指向的是定义时所在的对象,而不是使用时所在的对象。
1 | function Timer() { |
在最后的结果中会发现s1和s2输出的值是不一样的。
在生成Timer的实例timer后,通过setTimeout()函数在3.1秒后输出timer的s1变量,此时setInterval()函数已经执行了3次,由于this.s1++是处在箭头函数中的,这里的this就指向timer,此时timer.s1值为“3”。
而this.s2++是处在普通函数中的,这里的this指向的是全局对象window,实际上相当于window.s2++,结果是window.s2 = 3,而在最后一行的输出结果中,timer.s2仍然为“0”。
在上文中,我们有讲到“this指向的是定义时所在的对象”。从严格意义上讲,箭头函数中不会创建自己的this,而是会从自己作用域链的上一层继承this。
我们可以通过下面这个实例来理解。
1 | const Person = { |
在第一段代码中,sayHello()函数通过function关键字进行定义,在执行Person.sayHello()函数时,sayHello()函数中的this会指向函数的调用体,即Person本身;在调用setTimeout()函数时,由于其函数体部分是通过箭头函数定义的,内部的this会继承至父作用域的this,因此setTimeout()函数内部的this会指向Person,从而输出结果“我叫kingx,我今年18岁!”。
在第二段代码中,sayHello()函数通过箭头函数定义,在执行Person2.sayHello()函数时,sayHello()函数中的this会指向外层作用域,而Person2的父作用域就是全局作用域window;在调用setTimeout()函数时,由于其函数体部分是通过箭头函数定义的,内部的this会继承至sayHello()函数所在的作用域的this,即window,而window上并没有定义name和age属性,因此输出结果“我叫undefined,我今年undefined岁!”。
从这里的实例可以看出,对象函数使用箭头函数是不合适的。
7.5.1.2 不支持call()函数与apply()函数的特性
我们都知道通过调用call()函数与apply()函数可以改变一个函数的执行主体,即改变被调用函数中this的指向。但是箭头函数却不能达到这一点,因为箭头函数并没有自己的this,而是继承父作用域中的this。
也就是说,在调用call()函数和apply()函数时,如果被调用函数是一个箭头函数,则不会改变箭头函数中this的指向。
1 | let adder = { |
在上面的实例中,执行adder.add(1)时,add()函数内部通过箭头函数的形式定义了f()函数,f()函数中的this会继承至父作用域,即adder,那么this.base = 1,因此执行adder.add(1)相当于执行1 + 1的操作,结果输出“2”。
执行adder.addThruCall(1)时,addThruCall()函数内部通过箭头函数定义了f()函数,其中的this指向了adder。虽然在返回结果时,通过call()函数调用了f()函数,但是并不会改变f()函数中this的指向,this仍然指向adder,而且会接收参数a,因此执行adder.addThruCall(1)相当于执行1 + 1的操作,结果输出“2”。
因此在使用call()函数和apply()函数调用箭头函数时,需要谨慎。
7.5.1.3 不绑定arguments
在普通的function()函数中,我们可以通过arguments对象来获取到实际传入的参数值,但是在箭头函数中,我们却无法做到这一点。
1 | const fn = () => { |
通过上面的代码可以看出,在浏览器环境下,在箭头函数中使用arguments时,会抛出异常。因为无法在箭头函数中使用arguments,同样也就无法使用caller和callee属性。
虽然我们无法通过arguments来获取实参,但是我们可以借助rest运算符(…)来达到这个目的。
1 | const fn = (...args) => { |
7.5.1.4 支持嵌套
箭头函数支持嵌套的写法,假如我们需要实现这样一个场景:有一个参数会以管道的形式经过两个函数处理,第一个函数处理完的输出将作为第二个函数的输入,两个函数运算完后输出最后的结果。
1 | const pipeline = (...funcs) => |
我们先看第5行代码,这里调用了pipeline()函数,并传入plus1和mult2两个参数,返回的是一个函数,在函数中使用reduce()函数先后调用传入的两个处理函数。
在执行第6行代码时,pipeline()函数中的val为5,在第一次执行reduce()函数时,a为5,b为plus1()函数,实际相当于执行5 + 1 = 6,并返回了计算结果。
在第二次执行reduce()函数时,a为上一次返回的结果6,b为mult2()函数,实际相当于执行6×2 = 12,因此最后输出“12”。
7.5.2 箭头函数不适用的场景
7.5.2.1 不适合作为对象的函数
我们有讲到箭头函数并不会绑定this,如果使用箭头函数定义对象字面量的函数,那么其中的this将会指向外层作用域,并不会指向对象本身,因此箭头函数并不适合作为对象的函数。
7.5.2.2 不能作为构造函数,不能使用new操作符
构造函数是通过new操作符生成对象实例的,生成实例的过程也是通过构造函数给实例绑定this的过程,而箭头函数没有自己的this。因此不能使用箭头函数作为构造函数,也就不能通过new操作符来调用箭头函数。
1 | // 普通函数 |
7.5.2.3 没有prototype属性
因为在箭头函数中是没有this的,也就不存在自己的作用域,因此箭头函数是没有prototype属性的。
1 | let a = () => { |
7.5.2.4 不适合将原型函数定义成箭头函数
在给构造函数添加原型函数时,如果使用箭头函数,其中的this会指向全局作用域window,而并不会指向构造函数,因此并不会访问到构造函数本身,也就无法访问到实例属性,这就失去了作为原型函数的意义。
1 | function Person(name) { |
在上面的代码中,Person()构造函数增加了一个原型函数sayHello(),因为sayHello()函数是通过箭头函数定义的,所以其中的this会指向全局作用域window,从而无法访问到实例的name属性,输出“undefined”。
7.6 ES6对于对象的扩展
对象是JavaScript中重要的数据结构,而ES6对它进行了重大的升级,包括数据结构本身和对象新增的函数,为开发带来了极大的便利。
7.6.1 属性简写
1 | const name = 'kingx'; |
7.6.2 属性遍历
到ES6为止,一共有5种方法可以实现对象属性的遍历,具体方法如下所示。
· for…in。
· Object.keys(obj)。
· Object.getOwnPropertyNames(obj)。
· Object.getOwnPropertySymbols(obj)。
· Reflect.ownKeys(obj)。
定义一个拥有实例属性、继承属性的对象,其中包含Symbol属性、可枚举属性、不可枚举属性,覆盖全部的场景,用来测试这5种属性遍历方法的差异。
1 | // 定义父类 |
实例cat具有的属性如下所示。
1 | 实例属性: age, weight, Symbol('one'), color |
(1)for…in【for…in用于遍历对象自身和继承的可枚举属性(不包含Symbol属性)。】
1 | for (let key in cat) { |
(2)Object.keys()函数【Object.keys()函数返回一个数组,包含对象自身所有可枚举属性,不包含继承属性和Symbol属性。】
1 | Object.keys(cat); // [ 'age', 'weight', 'color' ] |
(3)Object.getOwnPropertyNames()函数【Object.getOwnPropertyNames()函数返回一个数组,包含对象自身所有可枚举属性和不可枚举属性,不包含继承属性和Symbol属性。】
1 | Object.getOwnPropertyNames(cat); // [ 'age', 'weight', 'color', 'height' ] |
(4)Object.getOwnPropertySymbols()函数 【Object.getOwnPropertySymbols()函数返回一个数组,包含对象自身所有Symbol属性,不包含其他属性。】
1 | Object.getOwnPropertySymbols(cat); // [ Symbol('one') ] |
(5)Reflect.ownKeys()函数【Reflect.ownKeys()函数返回一个数组,包含可枚举属性、不可枚举属性以及Symbol属性,不包含继承属性。】
1 | Reflect.ownKeys(cat); // [ 'age', 'weight', 'color', 'height', Symbol('one') ] |
7.6.3 新增Object.assign()函数
Object.assign()函数用于将一个或者多个对象的可枚举属性赋值给目标对象,然后返回目标对象。
首先我们创建一个同时拥有可枚举属性、不可枚举属性、继承属性、Symbol属性的对象。
1 | let obj = Object.create({a: 1}, { // a是继承属性 |
1 | console.log(Object.assign({}, obj)); |
7.6.3.1 对象克隆
使用Object.assign()函数进行克隆时,进行的是浅克隆。如果属性是基本数据类型,则会复制它的值;如果属性是引用数据类型,则会复制它的引用。
1 | function cloneObj(source) { |
7.6.3.2 给对象添加属性
1 | // 传统的写法 |
7.6.3.3 给对象添加函数
1 | // 传统写法 |
7.6.3.4 合并对象
1 | // 多个对象合并到一个目标对象中 |
7.7 symbol类型
在传统的JavaScript中,对象的属性名都是由字符串构成的。这样就会带来一个问题,假如一个对象继承了另一个对象的属性,我们又需要定义新的属性时,很容易造成属性名的冲突。
为了解决这个问题,ES6引入了一种新的基本数据类型Symbol,它表示的是一个独一无二的值。
至此JavaScript中就一共存在6种基本数据类型,分别是Undefined类型、Null类型、Boolean类型、String类型、Number类型、Symbol类型。
7.7.1 Symbol类型的特性
1. Symbol值的唯一性
1 | const a = Symbol(); |
2. 不能使用new操作符
Symbol函数并不是一个构造函数,因此不能通过new操作符创建Symbol值。
1 | let s1 = new Symbol(); // TypeError: Symbol is not a constructor |
3. 不能参与类型运算
1 | let s4 = Symbol('hello'); |
4. 可以使用同一个Symbol值
那就是使用Symbol.for()函数,它接收一个字符串作为参数,然后搜索有没有以该参数作为名称的Symbol值。如果有,就返回这个Symbol值,否则就新建并返回一个以该字符串为名称的Symbol值。
1 | let s1 = Symbol.for('one'); |
Symbol.for()函数与Symbol()函数这两种写法,都会生成新的Symbol值。它们的区别是,前者会被登记在全局环境中以供搜索,而后者不会。Symbol.for()函数不会每次调用就返回一个新的Symbol类型的值,而是会先检查给定的key是否已经存在,如果不存在才会新建一个值。例如,调用“Symbol.for(“cat”)”10 次,每次都会返回同一个Symbol值,但是调用“Symbol(“cat”)”10次,会返回 10 个不同的Symbol值。
1 | Symbol.for("bar") === Symbol.for("bar"); // true |
7.7.2 Symbol类型的用法
7.7.2.1 用作对象属性名
由于每一个Symbol值都是不相等的,它会经常用作对象的属性名,尤其是当一个对象由多个模块组成时,这样能够避免属性名被覆盖的情况。
1 | // 新增一个symbol属性 |
需要注意的是,不能通过点运算符为对象添加Symbol属性。
1 | const PROP_NAME = Symbol(); |
在上面的实例中,我们在通过点运算符为obj增加PROP_NAME属性时,这个PROP_NAME实际是一个字符串,并不是一个Symbol变量。因此我们通过中括号输出PROP_NAME变量对应的值时,得到的是“undefined”;而通过中括号输出’PROP_NAME’字符串值时,得到的是字符串’Hello’。
7.7.2.2 用于属性区分
我们可能会遇到这样一种场景,即通过区分两个属性来做对应的处理。
1 | // 求图形的面积(传统写法) |
在上面的写法中,字符串’triangle’和’rectangle’会强耦合在代码中。而事实上,我们仅想区分各种不同的形状,并不关心每个形状使用什么字符串表示,我们只需要知道每个变量的值是独一无二的即可,此时使用Symbol就会很合适。
1 | // 事先声明两个Symbol值,用于作判断 (Symbol写法) |
7.7.2.3 用于属性名遍历
使用Symbol作为属性名时,不能通过Object.keys()函数或者for…in来枚举,这样我们可以将一些不需要对外操作和访问的属性通过Symbol来定义。
1 | let obj = { |
当我们需要获取Symbol属性时,可以使用专门针对Symbol的API。
1 | // 使用Object的API |
7.8 set和map数据结构
7.8.1 Set数据结构
ES6中新增了一种数据结构Set,表示的是一组数据的集合,类似于数组,但是Set的成员值都是唯一的,没有重复。
Set本身是一个构造函数,可以接收一个数组或者类数组对象作为参数。下面讲解Set实例的属性和函数。
(1)属性
· Set.prototype.constructor:构造函数,默认就是Set函数。
· Set.prototype.size:返回实例的成员总数。
(2)函数
· Set.prototype.add(value):添加一个值,返回Set结构本身。
· Set.prototype.delete(value):删除某个值,返回布尔值。
· Set.prototype.has(value):返回布尔值,表示是否是成员。
· Set.prototype.clear():清除所有成员,无返回值。
需要注意的是,向Set实例中添加新的值时,不会发生类型转换。这可以理解为使用add()函数添加新值时,新值与Set实例中原有值是采用严格相等(===)进行比较的,只有在严格相等的比较结果为不相等时,才会将新值添加到Set实例中。
1 | let set = new Set(); |
但是上述规则对于NaN是一个特例,NaN与NaN在进行严格相等的比较时是不相等的,但是在Set内部,NaN与NaN是严格相等的,因此一个Set实例中只可以添加一个NaN。
1 | let set = new Set(); |
7.8.1.1 Set的常见用法
(1)单一数组的去重
1 | let arr = [1, 3, 4, 2, 3, 2, 5]; |
(2)多个数组的合并去重
1 | let arr1 = [1, 2, 3, 4]; |
(3)Set与数组的转换
Set与数组都拥有便利的数据处理函数,对于两者的相互转换也非常简单。我们可以选择合适的时机对两者进行转换,并调用对应的函数。
将数组转换为Set时,只需要通过Set的构造函数即可;将Set转换为数组时,通过Array.from()函数或者扩展运算符即可。
1 | let arr = [1, 3, 5, 7]; |
7.8.1.2 Set的遍历
针对Set数据结构,我们可以使用传统的forEach()函数进行遍历。forEach()函数的第一个参数表示的是Set中的每个元素,第二个参数表示的是元素的索引,从0开始。
1 | let set5 = new Set([4, 5, 'hello']); |
除了forEach()函数外,我们还可以使用以下3种函数对Set实例进行遍历。
· keys():返回键名的遍历器。
· values():返回键值的遍历器。
· entries():返回键值对的遍历器。
通过上述函数获得的对象都是遍历器对象Iterator,然后通过for…of循环可以获取每一项的值。
因为Set实例的键和值是相等的,所以keys()函数和values()函数实际返回的是相同的值。
1 | let set = new Set(['red', 'green', 'blue']); |
7.8.2 Map数据结构
ES6还增加了另一种数据结构Map,与传统的对象字面量类似,它的本质是一种键值对的组合。但是与对象字面量不同的是,对象字面量的键只能是字符串,对于非字符串类型的值会采用强制类型转换成字符串,而Map的键却可以由各种类型的值组成。
1 | // 传统的对象类型 |
1 | // Map |
在上面的实例中,采用的是Map处理方案,将DOM元素作为键添加到实例map中,在输出时会发现,键的值为DOM元素的真实值,并没有转换为字符串的值。
Map本身是一个构造函数,可以接收一个数组作为参数,数组的每个元素同样是一个子数组,子数组元素表示的是键和值。
1 | const map = new Map([ |
Map结构有一系列的实例属性和函数,总结如下。
· size属性:返回Map结构的成员总数。
· set(key, value):set()函数设置键名key对应的键值为value,set()函数返回的是当前Map对象,因此set()函数可以采用链式调用的写法。
· get(key):get()函数读取key对应的键值,如果找不到key,返回“undefined”。
· has(key):has()函数返回一个布尔值,表示某个键是否在当前Map对象中。
· delete(key):delete()函数删除某个键,返回“true”;如果删除失败,返回“false”。
· clear():clear()函数清除所有成员,没有返回值。
类似于Set数据结构的元素值唯一性,在Map数据结构中,所有的键都必须具有唯一性。如果对同一个键进行多次赋值,那么后面的值会覆盖前面的值。
1 | const map = new Map(); |
如果Map实例的键是引用数据类型,则需要判断对象是否为同一个引用、是否占据同一个内存地址。
1 | const map = new Map(); |
在上面的实例中,我们将数组[0]作为map的键,但是[0]作为引用类型数据,每次生成一个新的值都会占据新的内存地址,实际为不同的键,因此map在输出时会有两个元素值。
如果希望元素[0]只占据同一个键,则可以将其赋给一个变量值,通过变量值添加到map中。
1 | let arr = [0]; |
在上面的实例中,arr对应的值[0]被两次添加至map中,但是实际指向的是同一个引用,在内存中占据同一个地址,因此后面的值会覆盖前一个值,最后输出的map中只有一个值。
7.8.2.1 Map的遍历
与Set一样,Map的遍历同样可以采用4种函数,分别是forEach()函数、keys()函数、values()函数、entries()函数。
对于forEach()函数,第一个参数表示的是值,第二个参数表示的是键。
1 | const map = new Map(); |
keys()函数返回的是键的集合,values()函数返回的是值的集合,entries()函数返回的键值对的集合。
1 | for (let key of map.keys()) { |
7.8.2.2 Map与其他数据结构的转换
1、Map转换为数组,可以通过扩展运算符实现。
1 | //Map转换为数组 |
2、数组转换为Map,可以通过Map构造函数实现,使用new操作符生成Map的实例。
1 | //Map转换为对象 |
3、Map转换为对象,如果Map的实例的键是字符串,则可以直接转换;如果键不是字符串,则会先转换成字符串然后再进行转换。
1 | // Map转换为对象 |
4、对象转换为Map,只需要遍历对象的属性并通过set()函数添加到Map的实例中即可。
1 | // 对象转换为Map |
5、Map转换为JSON字符串时,有两种情况,第一种是当Map的键名都是字符串时,可以先将Map转换为对象,然后调用JSON.stringify()函数。
1 | // Map转换为JSON,通过对象 |
6、第二种是当Map的键名有非字符串时,我们可以先将Map转换为数组,然后调用JSON.stringify()函数。
1 | // Map转换为JSON,通过数组 |
7、JSON转换为Map。JSON字符串是由一系列键值对构成,键一般都为字符串。我们可以直接通过调用JSON.parse()函数先将JSON字符串转换为对象,然后再转换为Map。
1 | // JSON转换为Map |
8、Set转换为Map,Set中以数组形式存在的数据可以直接通过Map的构造函数转换为Map。
1 | // Set转换为Map |
9、Map转换为Set,可以将遍历Map本身获取到的键和值构成一个数组,然后通过add()函数添加至set实例中。
1 | // Map实例转换为Set |
7.9 proxy
ES6中新增了Proxy对象,从字面上看可以理解为代理器,主要用于改变对象的默认访问行为,实际表现是在访问对象之前增加一层拦截,任何对对象的访问行为都会通过这层拦截。在拦截中,我们可以增加自定义的行为。
Proxy的基本语法如下所示。
1 | const proxy = new Proxy(target, handler); |
它实际是一个构造函数,接收两个参数,一个是目标对象target;另一个是配置对象handler,用来定义拦截的行为。
proxy、target和handler之间的关系是什么样的呢?
通过Proxy构造函数可以生成实例proxy,任何对proxy实例的属性的访问都会自动转发至target对象上,我们可以针对访问的行为配置自定义的handler对象,因此外界通过proxy访问target对象的属性时,都会执行handler对象自定义的拦截操作。
1 | // 定义目标对象 |
在使用Proxy时,有几点需要注意的内容。
(1)必须通过代理实例访问
如果需要配置对象的拦截行为生效,那么必须是对代理实例的属性进行访问,而不是直接对目标对象进行访问。
如果直接通过目标对象person访问name属性,则不会触发拦截行为。
1 | console.log(person.name); // kingx |
(2)配置对象不能为空对象
如果需要配置对象的拦截行为生效,那么配置对象不能为空对象。如果为空对象,则代表没有设置任何拦截,实际是对目标对象的访问。另外配置对象不能为null,否则会抛出异常。
7.9.1 Proxy实例函数及其基本使用
通过访问代理对象的属性来触发自定义配置对象的get()函数。而get()函数只是Proxy实例支持的总共13种函数中的一种,这13种函数汇总如下。
· get(target, propKey, receiver)。 拦截对象属性的读取操作,例如调用proxy.name或者proxy[name],其中target表示的是目标对象,propKey表示的是读取的属性值,receiver表示的是配置对象。
· set(target, propKey, value, receiver)。 拦截对象属性的写操作,即设置属性值,例如proxy.name=’kingx’或者proxy[name]=’kingx’,其中target表示目标对象,propKey表示的是将要设置的属性,value表示将要设置的属性的值,receiver表示的是配置对象。
· has(target, propKey)。拦截hasProperty的操作,返回一个布尔值,最典型的表现形式是执行propKey in target,其中target表示目标对象,propKey表示判断的属性。
· deleteProperty(target, propKey)。拦截delete proxy[propKey]的操作,返回一个布尔值,表示是否执行成功,其中target表示目标对象,propKey表示将要删除的属性。
· ownKeys(target)。
· getOwnPropertyDescriptor(target, propKey)。
· defineProperty(target, propKey, propDesc)。
· preventExtensions(target)。
· getPrototypeOf(target)。
· isExtensible(target)。
· setPrototypeOf(target, proto)。
· apply(target, object, args)。拦截Proxy实例作为函数调用的操作,例如proxy(…args)、proxy.call(object,…args)、proxy.apply(…),其中target表示目标对象,object表示函数的调用方,args表示函数调用传递的参数。
· construct(target, args)。
1 | const person = { |
接下来我们会针对其中比较重要的几个函数通过实例进行讲解,看看它们的应用场景。
1、读取不存在属性
在正常情况下,读取一个对象不存在的属性时,会返回“undefined”。通过Proxy的get()函数可以设置读取不存在的属性时抛出异常,从而避免对undefined值的兼容性处理。
1 | let person = { |
2、读取负索引的值
数组的索引值是从0开始依次递增的,正常情况下我们无法读取负索引的值,但是通过Proxy的get()函数可以做到这一点。
1 | const arr = [1, 4, 9, 16, 25]; |
3、禁止访问私有属性
在一些约定俗成的写法中,私有属性都会以下画线(_)开头,事实上我们并不希望用户能访问到私有属性,这可以通过设置Proxy的get()函数来实现。
1 | const person = { |
4、Proxy访问属性的限制
当我们期望使用Proxy对对象的属性进行代理,并修改属性的返回值时,我们需要这个属性不能同时为不可配置和不可写。如果这个属性同时为不可配置和不可写,那么在通过代理读取属性时,会抛出异常。
1 | const target = Object.defineProperties({}, { |
5、拦截属性赋值操作
set()函数会拦截属性的赋值操作,例如这样一个场景:事先确定好了某个属性的取值区间,但是在对属性赋值时却不在这个区间内,则可以直接抛出异常。
定义一个person对象,包含一个age属性,取值区间为0~200,只要设置的值不在这个区间内,就会抛出异常。
1 | const proxy = new Proxy({}, { |
6、隐藏内部私有属性
Proxy提供了has()函数,用于拦截hasProperty()函数,即判断对象是否具有某个属性,如果具有则返回“true”,如果不具有则返回“false”,典型的就是in操作符。
需要注意的是has()函数判断的是hasProperty()函数,而不是hasOwnProperty()函数,即has()函数不判断一个属性是对象自身的属性,还是对象继承的属性。
has()函数有一个最大的用处就是隐藏某些以下画线开头(_)的私有属性,不对外暴露它们,从而通过in循环时不会遍历出私有属性值。
1 | const obj = { |
7、禁止删除某些属性
Proxy中提供了deleteProperty()函数,用于拦截delete操作,返回“true”时表示属性删除成功,返回“false”时表示属性删除失败。
利用这个特性,我们可以做特殊处理,不能删除以下画线开头的私有属性。当删除了私有属性时,会抛出异常,终止操作。
1 | let obj = { |
8、函数的拦截
Proxy中提供了apply()函数,用于拦截函数调用的操作,函数调用包括直接调用、call()函数调用、apply()函数调用3种方式。
通过对函数调用的拦截,可以加入自定义操作,从而得到新的函数处理结果。
1 | function sum(num1, num2) { |
第一种函数执行形式是直接通过proxy进行调用,执行过程为(1 + 3)×2 = 8。
第二种函数执行形式是通过call()函数调用,执行过程为(3 + 4)×2 = 14。
第三种函数执行形式是通过apply()函数调用,执行过程为(5 + 6)×2 = 22。
7.9.2 Proxy使用场景
7.9.2.1 实现真正的私有
真正的私有所要达到的目标有以下几个。
· 不能访问到私有属性,如果访问到私有属性则返回“undefined”。
· 不能直接修改私有属性的值,即使设置了也无效。
· 不能遍历出私有属性,遍历出来的属性中不会包含私有属性。
1 | const apis = { |
7.9.2.2 增加日志记录
在日常的开发中,针对那些调用频繁、运行缓慢或者占用资源密集型的接口,我们期望能记录它们的使用情况,这个时候我们可以通过Proxy作为中间件增加日志记录。
为了达到上面的目的,我们需要使用Proxy进行拦截,首先通过get()函数拦截到调用的函数名,然后通过apply()函数进行函数的调用。
1 | const apis = { |
在执行proxy.getAllUsers()函数后,输出结果如下所示。
1 | 这是记录日志的函数 |
7.9.2.3 提供友好提示或者阻止特定操作
通过Proxy,我们可以增加某些操作的友好提示或者阻止特定的操作,主要包括以下几类。
· 某些被弃用的函数被调用时,给用户提供友好提示。
· 阻止删除属性的操作。
· 阻止修改某些特定的属性的操作。
1 | let dataStore = { |
在上面的实例中,我们定义了一个数据源对象dataStore,其中包含了不能删除的属性noDelete、已废弃的函数oldMethod()、不能改变的属性doNotChange。
然后在Proxy的deleteProperty()函数中增加了对删除属性操作的控制,如果包含了不可删除的属性,则抛出异常提示“${key} cannot be deleted”。
7.10 reflect
Reflect对象与Proxy对象一样,也是ES6为了操作对象而提供的新API。
那么什么是Reflect对象呢?
我们可以这样理解:有一个名为Reflect的全局对象,上面挂载了对象的某些特殊函数,这些函数可以通过类似于Reflect.apply()这种形式来调用,所有在Reflect对象上的函数要么可以在Object原型链中找到,要么可以通过命令式操作符实现,例如delete和in操作符
大家可能会有疑问,既然在ES6之前,Object对象中已经有与Reflect的函数相同功能的函数或者命令式操作符,那么为什么还要在ES6中专门增加一个Reflect对象呢?
主要原因有以下几点。
· 更合理地规划与Object对象相关的API。在ES6中,Object对象的一些明显属于语言内部的函数都会添加到Reflect对象中,这样Object对象与Reflect对象中会存在相同的处理函数。而在未来的设计中,语言内部的函数将只会添加到Reflect对象中。
· 用一个单一的全局对象去存储这些函数,能够保持其他的JavaScript代码的整洁、干净。不然的话,这些函数可能是全局的,或者要通过原型来调用,不方便统一管理。
· 将一些命令式的操作符如delete、in等使用函数来替代,这样做的目的是为了让代码更好维护,更容易向下兼容,同时也避免出现更多的保留字。
1 | // 传统写法 |
· 修改Object对象的某些函数的返回结果,可以让其变得更合理,使得代码更好维护。
如果一个对象obj是不能扩展的,那么在调用Object.defineProperty(obj, name,desc)时,会抛出一个异常。因此在传统的写法中,我们需要通过try…catch处理。
而使用Reflect.defineProperty(obj, name, desc)时,返回的是“false”,新的写法就可以通过if…else实现。
1 | // 传统写法 |
· Reflect对象的函数与Proxy对象的函数一一对应,只要是Proxy对象的函数,就能在Reflect对象上找到对应的函数。这就让Proxy对象可以方便地调用对应的Reflect对象上的函数,完成默认行为,并以此作为修改行为的基础。
也就是说,不管Proxy对象怎么修改默认行为,总可以在Reflect对象上获取默认行为。而事实上Proxy对象也会经常随着Reflect对象一起进行调用,这些会在后面的实例中讲解到。
1 | new Proxy(target, { |
7.10.1 Reflect静态函数
与Proxy对象不同的是,Reflect对象本身并不是一个构造函数,而是直接提供静态函数以供调用,Reflect对象的静态函数一共有13个,
· Reflect.apply(target, thisArg, args)。Reflect.apply()函数的作用是通过指定的参数列表执行target函数,等同于执行Function.prototype.apply.call(target, thisArg, args)。
其中target表示的是目标函数,thisArg表示的是执行target函数时的this对象,args表示的是参数列表。
· Reflect.construct(target, args [, newTarget])。作用是执行构造函数,等同于执行new target(…args)。
其中target表示的是构造函数,args表示的是参数列表。newTarget是选填的参数,如果增加了该参数,则表示将newTarget作为新的构造函数;如果没有增加该参数,则仍然使用第一个参数target作为构造函数。
· Reflect.defineProperty(target, propKey, attributes)。作用是为对象定义属性,等同于执行Object.defineProperty()。
其中target表示的是定义属性的目标对象,propKey表示的是新增的属性名,attributes表示的是属性描述符对象集。
· Reflect.deleteProperty(target, propKey)。作用是删除对象的属性,等同于执行delete obj[propKey]。
其中target表示的是待删除属性的对象,propKey表示的是待删除的属性。
· Reflect.get(target, propKey, receiver)。作用是获取对象的属性值,等同于执行target[propKey]。
其中target表示的是获取属性的对象,propKey表示的是获取的属性,receiver表示函数中this绑定的对象。
· Reflect.getPrototypeOf(target)。作用是读取对象的_ proto _属性,等同于执行Object.getPrototypeOf(obj)。
· Reflect.has(target, propKey)。作用是判断属性是否在对象中,等同于执行propKey in target。
· Reflect.ownKeys(target)。函数的作用是获取对象的所有属性,包括Symbol属性,等同于Object.getOwnPropertyNames与Object.getOwnPropertySymbols之和。
· Reflect.preventExtensions(target)。函数的作用是让一个对象变得不可扩展,等同于执行Object.preventExtensions()。
· Reflect.set(target, propKey, value, receiver)。作用是设置某个属性值,等同于执行target[propKey] =value。
· Reflect.setPrototypeOf(target, newProto)。作用是设置对象的原型prototype,等同于执行Object.setPrototypeOf(target, newProto)。
1、Reflect.apply(target, thisArg, args)
这里我们选择了两个应用场景,一个是找出数组里的最大元素,一个是截取字符串中的一部分值,这两个场景分别使用传统的apply()函数和Reflect.apply()函数来实现。
1 | // 查找一个数字数组里面的最大元素 |
1 | // 截取字符串的一部分 |
2、Reflect.defineProperty(target, propKey, attributes)
Reflect.defineProperty()函数与Object.defineProperty()函数的主要区别在于返回值,如果设置失败,Object.defineProperty()函数会抛出一个异常,而Reflect.defineProperty()函数会返回“false”。
1 | let obj = {}; |
我们在采用传统ES5写法时,通过Object.defineProperty()函数为null添加一个属性,是一个失败的操作,会抛出一个异常,所以需要采用try…catch()函数的写法。
通过Reflect.defineProperty()函数设置obj对象的name属性值时会失败,因此在输出result1时,结果为“false”。
3、Reflect.deleteProperty(target, propKey)
1 | // 新的Reflect写法 |
在使用新的Reflect.deleteProperty()函数删除对象的属性时,只要对象是可扩展的,删除任何属性都会返回为“true”,即使该属性不存在。
使用传统的delete操作符达到的是相同的目的,即使删除的是不存在的属性,程序也不会抛出异常,所以两次调用delete obj2.name后程序依然正常;而当对象obj2通过freeze()函数冻结后,delete操作将不再生效,因此最后obj2为“{ age: 22}”。
4、Reflect.set(target, propKey, value, receiver)
这里我们主要看Reflect.set()函数在传递与不传递第四个参数receiver上的差异。
1 | let obj = { |
然后第一次调用Reflect.set()函数,修改age属性的值为24,操作成功。
第二次调用Reflect.set()函数,修改name属性的值为’kingx’,此时并未传递第四个参数,所以this指向第一个参数obj,执行成功后obj的值为“{ _name: ‘kingx’,name: [Getter/Setter], age: 24 }”。
第三次调用Reflect.set()函数,修改name属性值为’kingx2’,此时传递了第四个参数为一个对象receiver,则this就指向这个新对象receiver,而不再是obj对象。因此在设置name时,执行了this._name = name,实际是为receiver对象新增了一个_name属性,值为’kingx2’,在执行完后,obj对象的值依然不变,而receiver对象的值变为“{ test: ‘test’, _name: ‘kingx2’ }”。
7.10.2 Reflect与Proxy
ES6在设计的时候就将Reflect对象和Proxy对象绑定在一起了,Reflect对象的函数与Proxy对象的函数一一对应,因此在Proxy对象中调用Reflect对象对应的函数是一个明智的选择。
例如我们使用Proxy对象拦截属性的读取、设置和删除操作、并配合Reflect对象实现时,可以编写如下所示的代码。
1 | let target = { |
有一个最经典的案例就是可以实现观察者模式。
观察者模式的表现是:一个目标对象管理所有依赖于它的观察者对象,当自身的状态有变更时,会主动向所有观察者发出通知。
按照观察者模式的表现,我们可以设想这样一个场景:有一个目标对象和两个观察者对象,在修改目标对象的属性时通知所有的观察者,其中一个观察者获得修改后的值“开心地笑了”,另一个观察者获得修改后的值“伤心地哭了”。
代码的编写思路如下。
· 定义目标对象。
· 定义观察者队列,用于包含所有的观察者对象。
· 定义两个观察者对象。
· 定义Proxy的set()函数,用于拦截目标对象属性修改的操作。在拦截到set操作后,使用Reflect.set()函数修改属性,然后通知所有的观察者执行各自的操作。
· 定义为目标对象添加观察者的函数。
· 通过Proxy构造函数生成代理的实例。
根据以上的分析,我们可以得到以下的代码。
1 | // 目标对象 |
当最后我们执行proxy.name = ‘kingx2’后,进入了Proxy的set()函数中,成功地修改了name属性值,并且通知观察者执行各自的操作,第一个观察者输出的结果如下所示。
1 | 目标对象的name属性值变为kingx2,观察者1开心地笑了 |
第二个观察者输出的结果如下所示。
1 | 目标对象的name属性值变为kingx2,观察者2伤心地哭了 |
7.11 promise
7.11.1 Promise诞生的原因
1 | // 第一个请求 |
一个行为所产生的异步请求可能比这个还要多,这就会导致代码的嵌套太深,引发“回调地狱”。
“回调地狱”存在以下几个问题。
· 代码臃肿,可读性差。
· 代码耦合度高,可维护性差,难以复用。
· 回调函数都是匿名函数,不方便调试。
那么有什么方法能够避免在处理异步请求时,产生“回调地狱”的问题呢?
Promise就应运而生了,它为异步编程提供了一种更合理、更强大的解决方案。
7.11.2 Promise的生命周期
每一个Promise对象都有3种状态,即pending(进行中)、fulfilled(已成功)和rejected(已失败)。
Promise在创建时处于pending状态,状态的改变只有两种可能,一种是在Promise执行成功时,由pending状态改变为fulfilled状态;另一种是在Promise执行失败时,由pending状态改变为rejected状态。
状态一旦改变,就不能再改变,状态改变一次后得到的就是Promise的终态。
7.11.3 Promise的基本用法
Promise对象本身是一个构造函数,可以通过new操作符生成Promise的实例。
1 | const promise = new Promise((resolve, reject) => { |
Promise执行的过程是:在接收的函数中处理异步请求,然后判断异步请求的结果,如果结果为“true”,则表示异步请求执行成功,调用resolve()函数,resolve()函数一旦执行,Promise的状态就从pending变为fulfilled;如果结果为“false”,则表示异步请求执行失败,调用reject()函数,reject()函数一旦执行,Promise的状态就从pending变为rejected。
resolve()函数和reject()函数可以传递参数,作为后续.then()函数或者.catch()函数执行时的数据源。
需要注意的是Promise在创建后会立即调用,然后等待执行resolve()函数或者reject()函数来确定Promise的最终状态。
1 | let promise = new Promise(function(resolve, reject) { |
在上面的代码中,会先后输出 “Promise” “Hello” “resolved”。
· 首先是Promise的创建,会立即执行,输出“Promise”。
· 然后是执行resolve()函数,这样的话就会触发then()函数指定回调函数的执行,但是它需要等当前线程中的所有同步代码执行完毕,因此会先执行最后一行同步代码,输出“Hello”。
· 最后是当所有同步代码执行完毕后,执行then()函数,输出“resolved”。
当一个Promise的实例创建好后,我们该如何进行成功或者失败的异步处理呢?
这就需要调用then()函数和catch()函数了。
1、then()函数
Promise在原型属性上添加了一个then()函数,表示在Promise实例状态改变时执行的回调函数。
then()函数返回的是一个新Promise实例,因此可以使用链式调用then()函数,在上一轮then()函数内部return的值会作为下一轮then()函数接收的参数值。
1 | const promise = new Promise((resolve, reject) => { |
需要注意的是,在then()函数中不能返回Promise实例本身,否则会出现Promise循环引用的问题,抛出异常。
1 | const promise = Promise.resolve() |
2、catch()函数
catch()函数与then()函数是成对存在的,then()函数是Promise执行成功之后的回调,
而catch()函数是Promise执行失败之后的回调,它所接收的参数就是执行reject()函数时传递的参数。
我们可以通过在Promise中手动抛出一个异常,来测试catch()函数的用法。
1 | const promise = new Promise((resolve, reject) => { |
因为promise实例在创建后会立即执行,所以进入try语句后会抛出一个异常,从而被catch()函数捕获到,在catch()函数中调用reject()函数,并传递Error信息。一旦reject()函数被执行,就会触发promise实例的catch()函数,从而能在catch()函数的回调函数中输出err的信息。
事实上只要在Promise执行过程中出现了异常,就会被自动抛出,并触发reject(err),而不用我们去使用try…catch,在catch()函数中手动调用reject()函数。
因此前面的代码可以改写成如下所示的代码。
1 | const promise = new Promise((resolve, reject) => { |
另外我们再拿一个空指针引用的异常来进行测试。
1 | const promise = new Promise((resolve, reject) => { |
在Promise接收的函数体中引用null的name属性时,会抛出一个异常。这个异常会被自动捕获,而且会自动执行reject()函数,从而会触发catch()函数并传递异常值,在函数体中将其输出.
需要注意的是,如果一个Promise的状态已经变成fulfilled成功状态,再去抛出异常,是无法触发catch()函数的。这是因为Promise的状态一旦改变,就会永久保持该状态,不会再次改变。
1 | const promise = new Promise((resolve, reject) => { |
在上面代码的Promise函数体中,调用resolve()函数,并传递一个参数1,会直接触发promise的then()函数,而不会执行下面的抛出异常的throw语句,从而输出“1”,整个Promise执行过程结束。
在ES6中不仅为Promise的原型对象添加了then()函数和catch()函数等异步处理函数,**还为Promise对象自身添加了一系列的静态函数,用来处理多Promise实例同时运行的情况。**接下来我们选择几个重点的静态函数来讲解。
1、Promise.all()函数
then()函数和catch()函数是Promise原型链中的函数,因此每个Promise的实例可以进行共享,而all()函数是Promise本身的静态函数,用于将多个Promise实例包装成一个新的Promise实例。
1 | const p = Promise.all([p1, p2, p3]); |
返回的新Promise实例p的状态由3个Promise实例p1、p2、p3共同决定,总共会出现以下两种情况。
· 只有p1、p2、p3全部的状态都变为fulfilled成功状态,p的状态才会变为fulfilled状态,此时p1、p2、p3的返回值组成一个数组,作为p的then()函数的回调函数的参数。
· 只要p1、p2、p3中有任意一个状态变为rejected失败状态,p的状态就变为rejected状态,此时第一个被reject的实例的返回值会作为p的catch()函数的回调函数的参数。
需要注意的是,作为参数的Promise实例p1、p2、p3,如果已经定义了catch()函数,那么当其中一个Promise状态变为rejected时,并不会触发Promise.all()函数的catch()函数。
1 | const p1 = new Promise((resolve, reject) => { |
在上面代码的实例p2中抛出了一个异常,p2的状态变为rejected,但是由于p2有自己的catch()函数,所以这个异常会在p2实例内部被消化,并不会继续向外抛到Promise.all()函数中。
p2实例执行完catch()函数后,p2的状态实际是变为fulfilled,只不过它的返回值是Error的信息。
如果想要Promise.all()函数能触发catch()函数,那么就不要在p1、p2实例中定义catch()函数
1 | const p1 = new Promise((resolve, reject) => { |
2、Promise.race()函数
Promise.race()函数作用于多个Promise实例上,返回一个新的Promise实例,表示的是如果多个Promise实例中有任何一个实例的状态发生改变,那么这个新实例的状态就随之改变,而最先改变的那个Promise实例的返回值将作为新实例的回调函数的参数。
1 | const p = Promise.race([p1, p2, p3]); |
当p1、p2、p3这3个Promise实例中有任何一个执行成功或者失败时,由Promise.race()函数生成的实例p的状态就与之保持一致,并且最先那个执行完的实例的返回值将会成为p的回调函数的参数。
使用Promise.race()函数可以实现这样一个场景:假如发送一个Ajax请求,在3秒后还没有收到请求成功的响应时,会自动处理成请求失败。
1 | const p1 = ajaxGetPromise('/testUrl'); |
3、Promise.resolve()函数
Promise提供了一个静态函数resolve(),用于将传入的变量转换为Promise对象,它等价于在Promise函数体内调用resolve()函数。
Promise.resolve()函数执行后,Promise的状态会立即变为fulfilled,然后进入then()函数中做处理。
1 | Promise.resolve('hello'); |
在Promise.resolve(param)函数中传递的参数param,会作为后续then()函数的回调函数接收的参数。
1 | Promise.resolve('success').then(result => console.log(result)); |
执行上面的代码后,会输出字符串“success”。
4、Promise.reject()函数
Promise.reject()函数用于返回一个状态为rejected的Promise实例,函数在执行后Promise的状态会立即变为rejected,从而会立即进入catch()函数中做处理,等价于在Promise函数体内调用reject()函数。
1 | const p = Promise.reject('出错了'); |
在Promise. reject (param)函数中传递的参数param,会作为后续catch()函数的回调函数接收的参数。
1 | Promise.reject('fail').catch(result => console.log(result)); |
执行上面的代码后,会输出字符串“fail”。
7.11.4 Promise的用法实例
7.11.4.1 场景1:Promise代码与同步代码在一起执行
1 | const promise = new Promise((resolve, reject) => { |
在上面的代码中,考察的是对Promise对象执行时机的理解,大致会分为以下几个过程。
· Promise在创建后会立即执行,所有同步代码按照书写的顺序从上往下执行,包括Promise外的同步代码,因此会先输出“1 2 4”。
· resolve()函数或者reject()函数会在同步代码执行完毕后再去执行。
· 当resolve()函数或者reject()函数执行后,进入then()函数或者catch()函数中执行,实例中调用了resolve()函数,会进行到then()函数中,因此会再输出“3”。
7.11.4.2 场景2:同一个Promise实例内,resolve()函数和reject()函数先后执行
1 | const promise2 = new Promise((resolve, reject) => { |
一个Promise的实例只能有一次状态的变更,当执行了resolve()函数后,后续其他的reject()函数和resolve()函数都不会执行,然后Promise进入then()函数中做处理。
7.11.4.3 场景3:同一个Promise实例自身重复执行
我们生成一个Promise的实例,针对这个实例重复调用then()函数,在then()函数中输出一个时间差值,看看最终的输出结果是什么。
1 | const promise3 = new Promise((resolve, reject) => { |
同一个Promise的实例只能有一次状态变换的过程,在状态变换完成后,如果成功会触发所有的then()函数,如果失败会触发所有的catch()函数。
在上面的代码中,第1~6行生成promise3实例,通过setTimeout()函数延迟执行resolve()函数,会继续向下执行到第7行代码,得到一个start时间戳。
当等待一秒后,执行第2行的setTimeout()函数,首先输出一个字符串’once’,然后执行resolve()函数并传递字符串’success’,开始进入第8行的then()函数中,计算当前时间戳与start时间戳的差值。
由于Promise的状态只能改变一次,第10行的then()函数与第8行的then()函数都会执行,而且会接收相同的参数,然后重新计算时间戳的差值。
如果大家在运行后得到的结果不同也是正常情况,这取决于运行的环境,很可能会相差几毫秒。
1 | once |
7.11.4.4 场景4:在then()函数中返回一个异常
在场景4中,我们会在一个Promise实例的then()函数中返回一个异常,然后链式调用then()函数和catch()函数,在函数中输出关键信息,看看最终的输出结果是什么。
1 | Promise.resolve() |
很多人看到代码中出现了new Error()函数就会想当然地认为会执行后面的catch()函数,其实不是这样的。
在then()函数中用return关键字返回了一个“Error”,依然会按照正常的流程走下去,进入第二个then()函数,并将Error实例作为参数传递,不会执行后续的catch()函数。
这个不同于使用throw抛出一个Error,如果是throw抛出一个Error则会被catch()函数捕获。
结果:
1 | 1 |
7.11.4.5 场景5:then()函数接收的参数不是一个函数
在之前的内容中,我们讲过then()函数接收的参数是函数的形式,而在场景5中,如果then()函数接收的参数不是一个函数,会产生什么样的情况呢?
1 | Promise.resolve(1) |
很多人乍一看这段代码,会想当然地以为返回“3”,但是结果却不是这样的。
这段代码的运行结果是只输出一个“1”,为什么会这样呢?
何为值穿透现象?简单点理解就是传递的值会被直接忽略掉,继续执行链式调用后续的函数。
场景5中,第一个then()函数接收一个值“2”,第二个then()函数接收一个Promise,都不是需要的函数形式,因此这两个then()函数会发生值穿透现象。
而第三个then()函数因为接收到console.log()函数,因此会执行,此时接收的是最开始的resolve(1)的值,因此场景5最终会输出“1”。
7.11.4.6 场景6:两种方法处理rejected状态的Promise
处理Promise失败的方法有两种,一种是使用then()函数的第二个参数,另一种是使用catch()函数。
1 | Promise.resolve() |
虽然这两种方法都能处理Promise状态变为rejected时的回调,但是then()函数的第二个函数却不能捕获第一个函数中抛出的异常,而catch()函数却能捕获到第一个函数中抛出的异常。
结果如下所示
1 | fail2: Error: error |
这也是我们推荐使用catch()函数去处理Promise状态异常回调的原因。
7.12 iterator与for…of循环
7.12.1 iterator概述
Iterator称为遍历器,是ES6为不同数据结构遍历所新增的统一访问接口,它有以下几个作用。
· 为任何部署了Iterator接口的数据结构提供统一的访问机制。
· 使得数据结构的成员能够按照某种次序排列。
· 为新的遍历方式for…of提供基础。
一个合法的Iterator接口都会具有一个next()函数,在遍历的过程中,依次调用next()函数,返回一个带有value和done属性的对象。value值表示当前遍历到的值,done值表示迭代是否结束,true表示迭代完成,Iterator执行结束;false表示迭代未完成,继续执行next()函数,进入下一轮遍历中,直到done值为true。
为了增进对Iterator遍历过程的理解,我们可以先使用数组来模拟Iterator接口的实现。
1 | function makeIterator(array) { |
7.12.2 默认iterator接口
1 | // 对象默认不能使用for...of循环 |
原生具备Iterator接口的数据结构有以下几个。
· Array。
· Map。
· Set。
· String。
· 函数的arguments对象。
· NodeList对象。
那么问题来了,如果我们想要自定义一些可以使用for…of循环的数据结构,那么该怎么做呢?
方法就是为数据结构添加上Iterator接口,Iterator接口是部署在Symbol.iterator属性上的,它是一个函数,因此我们只需要对特定的数据结构加上Symbol.iterator属性即可。
接下来我们就通过自定义的手段,为对象类型的数据添加Iterator接口,使得它也可以使用for…of循环,具体代码如下所示。
1 | function Person(name, age) { |
7.12.3 for…of循环
1、数组结构使用for…of循环
1 | const arr = ['one', 'two', 'three']; |
2、Set数据结构和Map数据结构使用for…of循环
对于Set结构的数据,for…of循环会返回Set中的每个值。
1 | let set = new Set(['one', 'two', 'three']); |
对于Map结构的数据,for…of循环在执行每轮循环时,会将Map中的每个键和对应的值组合成一个数组进行返回。
1 | let map = new Map(); |
3、NodeList结构使用for…of循环
1 | <p>这是第一个段落</p> |
4、函数参数arguments对象使用for…of循环
1 | function foo() { |
5、特定函数的返回值使用for…of循环
· Object.entries()函数:返回一个遍历器对象,由键、值构成的对象数组。
· Object.keys()函数:返回一个遍历器对象,由所有的键构成的数组。
· Object.values()函数:返回一个遍历器对象,由所有的值构成的数组。
7.12.4 for…of循环与其他循环方式对比
for…of循环与forEach()函数循环和for…in循环进行比较。
forEach()函数循环的主要问题在于无法跳出循环,不支持break和continue关键字,如果使用了break或continue关键字则会抛出异常,使用return关键字会跳过当前循环,但仍会执行后续的循环。
1 | const arr = ['one', 'two', 'three']; |
for…in循环的主要问题在于,它主要是为遍历对象设计的,对数组遍历并不友好,主要存在以下两个问题。
第一个问题是,在使用for…in循环遍历数组时,返回的键是字符串表示的数组的索引,如“0”“1”“2”,并不是数组项的值。
第二个问题是,通过手动给数组实例添加的属性,同样会被遍历出来,而事实上我们并不希望这些额外的属性被遍历出来。
1 | const arr = ['one', 'two', 'three']; |
相比于forEach()函数循环和for…in循环,for…of循环就有一些显著的优点。
优点1:和for…in循环有同样的语法,但没有for…in循环的缺点,遍历数组时,返回的是数组每项的值,而且给数组实例新增的属性并不会被遍历出来。
优点2:在for…of循环中,可以使用break、continue和return等关键字。
1 | const arr = ['one', 'two', 'three']; |
7.13 generator()函数
7.13.1 Generator()函数的概述与特征
1、Generator()函数的概述
Generator()函数是ES6提供的一种异步编程解决方案。
Generator()函数从语法上可以理解为是一个状态机,函数内部维护多个状态,函数执行的结果返回一个部署了Iterator接口的对象,通过这个对象可以依次获取Generator()函数内部的每一个状态。
2、Generator()函数的特征
Generator()函数本质上也是一个函数,调用方法也与普通函数相同,但是相比较于普通的函数,有以下两个明显的特征。
· function关键字与函数名之间有一个星号(*)。
· 函数体内部使用yield关键字来定义不同的内部状态。
案例
1 | function* helloworldGenerator() { |
代码中定义的helloWorldGenerator()函数在执行后,函数体并没有直接执行,而是返回一个部署了Iterator接口的对象,直到调用next()函数时,才开始从函数头部向下执行,直到遇到yield表达式或者return语句才会停止。
3、Generator()函数中的yield表达式与next()函数的关系
Generator()函数返回的是部署了Iterator接口的对象,而该对象是通过调用next()函数来遍历内部状态的,所以在没有调用下一轮next()函数时,函数处于暂停状态,而这个暂停状态就是通过yield表达式来体现的,因此Generator()函数对异步的控制是通过yield表达式来实现的。
通过Iterator接口的next()函数执行过程可以看出next()函数与yield表达式的关系。
· next()函数的返回值是一个具有value和done属性的对象,next()函数调用后,如果遇到yield表达式,就会暂停后面的操作,并将yield表达式执行的结果作为value值进行返回,此时done属性的值为false。
· 当再次执行next()函数时,会再继续往下执行,直到遇到下一个yield表达式。
· 当所有的yield语句执行完毕时,会直接运行至函数末尾,如果有return语句,将return语句的表达式值作为value值返回;如果没有return语句,则value以undefined值进行返回,这两种情况下的done属性的值都为true,遍历结束。
1 | function* helloworldGenerator() { |
return与yield语句都能将后面的表达式作为next()函数的返回值,但是它们也是有差异的,主要表现在以下几个方面。
· 当遇到yield语句时,程序的执行会暂停,而return语句却不会,一旦return语句执行,整个函数执行结束,后面的yield语句都会失效。
· return语句如果没有返回值,那么next()函数的返回值为“{ value:undefined,done: true }”。yield语句如果没有接表达式,next()函数的返回值中value值同样为“undefined”,而done属性的值为“false”。
· Generator()函数能有多个yield语句,但是只能有一个return语句。
yield语句本身没有返回值,如果将其赋给一个变量,则该变量的值为undefined。如果我们想要使用上一轮yield表达式的结果,则需要借助next()函数,next()函数携带的参数可以作为上一轮yield表达式的返回值。
1 | function* foo(x) { |
4、for…of循环遍历Generator()函数的返回值
Generator()函数的返回值是一个部署了Iterator接口的对象,刚好可以使用for…of循环进行遍历,并且不需要手动调用next()函数,遍历的结果就是yield表达式的返回值。
1 | function* testGenerator() { |
对象类型的值在默认情况下是不能使用for…of循环进行遍历的,但是借助于Generator()函数可以实现for…of循环的遍历。
主要思路是给对象的Symbol.iterator属性设置一个Generator()函数,在Generator()函数内通过yield控制遍历的返回值。
1 | function* propGenerator() { |
7.13.2 Generator()函数注意事项
1、默认情况下不能使用new关键字
2、yield表达式会延迟执行
在Generator()函数中,yield表达式只有在调用next()函数时才会去执行,因此起到了延迟执行的效果。
1 | function* testGenerator() { |
3、yield表达式只能在Generator()函数中调用
4、yield表达式需要小括号括起来
当一个yield表达式出现在其他表达式中时,需要用小括号将yield表达式括起来,否则会抛出语法异常。
1 | function* demo() { |
5、Generator()函数中的this特殊处理
在默认情况下,不能使用new关键字生成Generator的实例,因此Generator()函数中的this是无效的。
1 | function* testGenerator() { |
在this上绑定的name属性不会生效,访问的时候会返回“undefined”。
如果既想使用Generator()函数的特性,又想使用this的特性,那该怎么做呢?
1 | function* testGenerator() { |
6、 Generator()函数嵌套使用
一般的写法如下所示。
1 | function* fn1() { |
为了解决这个问题,ES6提供了一种新的写法,那就是使用yield* 表达式,以支持Generator()函数的嵌套使用。
上面实例使用yield* 表达式的写法后的代码如下所示。
1 | function* fn1() { |
7.14 class
7.14.1 Class基本用法
传统的JavaScript中只有对象,没有类概念,跟面向对象语言差异很大。为了让JavaScript具有更接近面向对象语言的写法,ES6引入了Class(类)的概念,通过class关键字定义类。
不管是ES5还是ES6的写法,想要生成对象的实例,都需要通过new关键字调用构造函数,但是在具体实现上有一些差异。
ES5需要定义构造函数,在构造函数中定义实例属性,然后在prototype原型上添加原型属性或者函数。
ES6则使用class关键字定义类的名称,然后在类的constructor构造函数中定义实例属性,原型属性在class内部直接声明并赋值,原型函数的声明与构造函数处于同一层级,并且省略function关键字。
下面是分别使用ES5和ES6的写法来生成对象实例的代码。
1 | // ES5的写法 |
class的本质还是一个函数,只不过是函数的另一种写法,这种写法可以让对象的原型属性和函数更加清晰。
1 | console.log(typeof Person2); // function |
事实上,class中的所有属性和函数都是定义在prototype属性中的,但是我们却没有使用过prototype属性,这是为什么呢?其实这是因为ES6将prototype相关的操作封装在了class中,避免我们直接去使用prototype属性。
我们以前面代码中的getName属性做测试。
1 | console.log(p2.getName === Person2.prototype.getName); // true |
p2实例的getName属性与Person2类原型中的getName属性是严格相等的。
1、class重点理解的内容
在class内部有两点内容需要重点理解,一个是constructor()函数,一个是静态属性和函数,接下来将详细讲解。
1、constructor()函数
constructor()函数是一个类必须具有的函数,可以手动添加,如果没有手动添加,则会自动隐式添加一个空的constructor()函数。
constructor()函数默认会返回当前对象的实例,即默认的this指向,我们可以手动修改返回值。
1 | class Person3 { |
2、静态属性和函数
静态属性和函数同样存在于类内部,使用static关键字修饰时,静态属性和函数无法被实例访问,只能通过类自身使用。
1 | class Foo { |
静态函数中的this指向的是类本身,而不是类的实例,也正因为静态函数和实例函数中的this是隔离的,所以同一个类中可以存在函数名相同的静态函数和实例函数。
1 | class MyClassroom { |
2、Class使用示例
下面我们使用Class定义一个类,来完成一个简单的版本控制功能,主要有以下操作。
· 使用一个二维数组作为所有历史提交记录的集合,数组的每个元素为一个一维数组,表示某次commit时记录的信息。
· 使用一个一维数组装下用户所有的历史修改值,当调用commit()函数时,会将历史修改值添加至历史记录对应的二维数组中。
· 当调用revert()函数时,会回滚到最近一次commit的版本。
1 | class VersionedArray { |
3、Class使用注意点
(1)只能与new关键字配合使用
1 | class Person {} |
(2)不存在变量提升
之前章节有讲过let关键字和const关键字声明的变量不存在变量提升,class定义的类同样不存在变量提升,因此如果在定义类之前去使用它,会抛出引用异常。
1 | const p = new Person(); // ReferenceError: Person is not defined |
(3)在类中声明函数时,不要加function关键字
1 | class Person3 { |
(4)this指向会发生变化
类内部的this默认指向的是类的实例,在调用实例函数时,一定要注意this的指向性问题。如果单独使用实例函数时,this的指向会发生变化,很容易带来一定的问题。
1 | class Person4 { |
在上面的代码中,生成Person4对象的实例p,然后使用解构获取到getName()函数,在调用时抛出类型异常。
这是因为getName()函数是在全局环境中执行的,this指向的是全局环境,而在ES6的class关键字中使用了严格模式。在严格模式下this不能指向全局环境,而是指向undefined,所以getName()函数在执行时,this实际为undefined,通过undefined引用name属性就会抛出异常。
为了解决上述问题,我们可以在构造函数中使用bind关键字重新绑定this。
1 | class Person4 { |
在上面的代码中,使用bind关键字重新绑定了getName()函数在调用时内部的this,使其指向实例p,因此在执行getName()函数时,输出结果为“kingx”。
7.14.2 Class继承
ES6新增了extends关键字,可以快速实现类的继承。
在子类的constructor构造函数中,需要首先调用super()函数执行父类的构造函数,再执行子类的函数修饰this。
1 | // 父类 |
使用extends关键字不仅可以继承自定义的类,还可以继承原生的内置构造函数
1 | class MyArr extends Array { |
父类的静态函数无法被实例继承,但可以被子类继承。子类在访问时同样是通过本身去访问,而不是通过子类实例去访问。
1 | class Parent { |
7.15 module
7.15.1 Module概述
ES6提供了模块化的设计,可以将具有某一类特定功能的代码放在一个文件里,在使用时,只需要引入特定的文件,便可以降低文件之间的耦合性。
相比于早期制定的CommonJS规范,
- CommonJS在运行时完成模块的加载,而ES6模块是在编译时完成模块的加载,效率要更高。
- CommonJS模块是对象,而ES6模块可以是任何数据类型,通过export命令指定输出的内容,并通过import命令引入即可。
- CommonJS模块会在require加载时完成执行,而ES6的模块是动态引用,只在执行时获取模块中的值。
7.15.2 export命令
7.15.2.1 export命令的特性
export命令的一些特性需要大家重点理解。
(1)export的是接口,而不是值
不能直接通过export输出变量值,而是需要对外提供接口,必须与模块内部的变量建立一一对应的关系,例如以下写法都是错误的。
1 | let obj = {}; |
需要修改成对象被括起来或者直接导出的形式。
1 | let obj = {}; |
(2)export值的实时性
export对外输出的接口,在外部模块引用时,是实时获取的,并不是import那个时刻的值。
假如在文件中export一个变量,然后通过定时器修改这个变量的值,那么在其他文件中不同时刻使用import的变量,值也会不同。
1 | // 导出文件export1.js |
7.15.2.2 export命令的常见用法
(1)使用as关键字设置别名
如果不想对外暴露内部变量的真实名称,可以使用as关键字设置别名,同一个属性可以设置多个别名。
在外部文件进行引入时,通过name和name2两个变量都可以访问到“kingx”值。
1 | const _name = 'kingx'; |
(2)相同变量名只能够export一次
1 | const _name = ‘kingx’; |
(3)尽量统一export
如果文件export的内容有很多,建议都放在文件末尾处统一进行export,这样对export的内容能一目了然。
7.15.3 import命令
如果想要在HTML页面中使用import命令,需要在script标签上使用代码type=”module”。
1 | <script type="module"></script> |
7.15.3.1 import命令的特性
(1)与export的变量名相同
import命令引入的变量需要放在一个大括号里,括成对象的形式,而且import的变量名必须与export的变量名一致。
这点特性在使用了export default命令时会有新的表现形式,在后面我们会具体讲到。
1 | // export.js |
(2)相同变量名的值只能import一次
1 | // export1.js |
(3)import命令具有提升的效果
import命令具有提升的效果,会将import的内容提升到文件头部。
1 | // export.js |
在上面的代码中,import语句出现在输出语句的后面,但是仍然能正常输出。本质上是因为import是在编译期运行的,在执行输出代码之前已经执行了import语句。
(4)多次import时,只会一次加载
每个模块只加载一次,每个JS文件只执行一次,如果在同一个文件中多次import相同的模块,则只会执行一次模块文件,后续直接从内存读取。
1 | // export.js |
(5)import的值本身是只读的,不可修改
使用import命令导入的值,如果是基本数据类型,那么它们的值是不可以修改的,相当于一个const常量;如果是引用数据类型的值,那么它们的引用本身是不能修改的,只能修改引用对应的值本身。
1 | // export.js |
7.15.3.2 import命令的常见用法
(1)设置引入变量的别名
同样可以使用as关键字为变量设置别名,可以用于解决上一部分中相同变量名import一次的问题。
1 | // export1.js |
(2)模块整体加载
当我们需要加载整个模块的内容时,可以使用星号(*)配合as关键字指定一个对象,通过对象去访问各个输出值。
1 | // export.js |
7.15.4 export default命令
在之前的讲解中,使用import引入的变量名需要和export导出的变量名一样。在某些情况下,我们希望不设置变量名也能供import使用,import的变量名由使用方自定义,这时就要使用到export default命令了。
1 | // export.js |
在使用export default命令时,有几点是需要注意的。
1. 一个文件只有一个export default语句
2. import的内容不需要使用大括号括起来
7.15.5 Module加载的实质
ES6模块的运行机制是这样的:当遇到import命令时,不会立马去执行模块,而是生成一个动态的模块只读引用,等到需要用到时,才去解析引用对应的值。
由于ES6的模块获取的是实时值,就不存在变量的缓存。
1 | // export.js |
第一次输出变量counter的值时,counter为“1”,在执行incCounter()函数后,counter的值加1,输出“2”。
这表明导入的值仍然与原来的模块存在引用关系,并不是完全隔断的。
如7.15.3小节的描述,这个引用关系是只读的,不能被修改。
1 | import {counter, incCounter} from './export7.js'; |
对上述代码稍做修改,将counter的值设置为自增,就会抛出异常。
如果在多个文件中引入相同的模块,则它们获取的是同一个模块的引用。
在export.js文件中定义一个Counter模块,并导出一个Counter的实例,代码如下所示。
1 | function Counter() { |
在另外两个模块中分别导入Counter模块,并进行不同处理。
1 | // import1.js |
在一个html文件中引入两个import文件。
1 | import './import1.js'; |
通过控制台可以看到,结果输出为“1”。因为在两个import文件中使用的c变量指向的是同一个引用,在import1.js文件中调用了add()函数,增加了sum变量的值,在import2.js文件中输出sum变量时,值也变为了1。